HDFS读写流程
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS读写流程相关的知识,希望对你有一定的参考价值。
读程图:
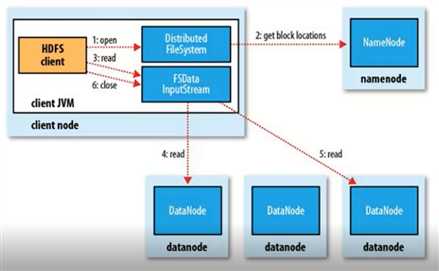
1、客户端发送请求,调用DistributedFileSystem API的open方法发送请求到Namenode,获得block的位置信息,因为真正的block是存在Datanode节点上的,而namenode里存放了block位置信息的元数据。
2、Namenode返回所有block的位置信息,并将这些信息返回给客户端。
3、客户端拿到block的位置信息后调用FSDataInputStream API的read方法并行的读取block信息,图中4和5流程是并发的,block默认有3个副本,所以每一个block只需要从一个副本读取就可以。
4、datanode返回给客户端。
写流程:
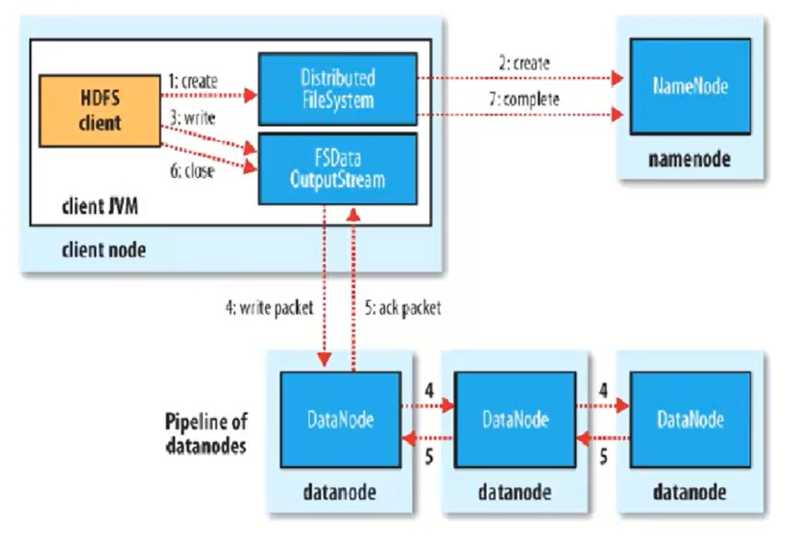
1、客户端发送请求,调用DistributedFileSystem API的create方法去请求namenode,并告诉namenode上传文件的文件名、文件大小、文件拥有者。
2、namenode根据以上信息算出文件需要切成多少块block,以及block要存放在哪个datanode上,并将这些信息返回给客户端。
3、客户端调用FSDataInputStream API的write方法首先将其中一个block写在datanode上,每一个block默认都有3个副本,并不是由客户端分别往3个datanode上写3份,而是由
已经上传了block的datanode产生新的线程,由这个namenode按照放置副本规则往其它datanode写副本,这样的优势就是快。
4、写完后返回给客户端一个信息,然后客户端在将信息反馈给namenode。
5、需要注意的是上传文件的拥有者就是客户端上传文件的用户名,举个例子用windows客户端上传文件,那么这个文件的拥有者就是administrator,和linux上的系统用户名不是一样的。
以上是关于HDFS读写流程的主要内容,如果未能解决你的问题,请参考以下文章