HDFS读写流程
Posted dragon-123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS读写流程相关的知识,希望对你有一定的参考价值。
HDFS写流程
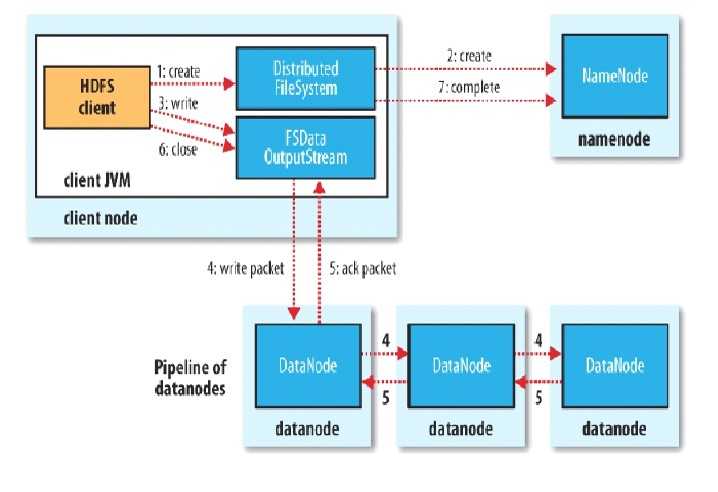
Client
- 切分文件Block
- 按Block线性和NN获取DN列表(副本数)
- 验证DN列表后以更小的单位流式传输数据
- 各节点,两两通信确定可用
- Block传输结束后
- DN向NN汇报Block信息
- DN向Client汇报完成
- Client向NN汇报完成
- 获取下一个Block存放的DN列表
- 。。。。。。
- 最终Client汇报完成
- NN会在写流程更新文件状态
HDFS读流程
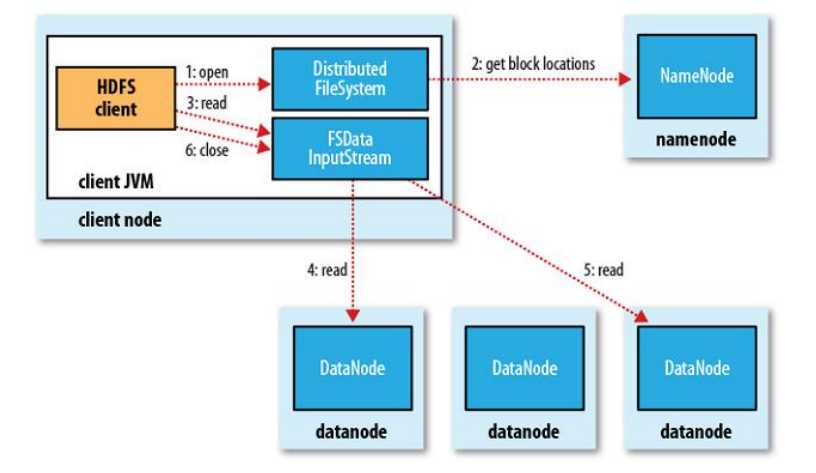
Client
- 向NN获取一部分Block副本位置列表
- 线性和DN获取Block,最终合并为一个文件
- 在Block副本列表中按距离择优选取
- MD5验证数据完整性
HDFS文件权限 POSIX标准(可移植操作系统接口)
- 与Linux文件权限类似
- r: read; w:write; x:execute
- 权限x对于文件忽略,对于文件夹表示是否允许访问其内容
- 例如Linux系统用户jack使用hadoop命令创建一个文件,那么这个文件在HDFS中owner就是jack。
- HDFS的权限目的:阻止误操作,但不绝对。HDFS相信,你告诉我你是谁,我就认为你是谁。
HDFS安全模式
- namenode启动的时候,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作。
- 一旦在内存中成功建立文件系统元数据的映射,则创建一个新的fsimage文件(这个操作不需要SecondaryNameNode)和一个空的编辑日志。
- 此刻namenode运行在安全模式。即namenode的文件系统对于客服端来说是只读的。(显示目录,显示文件内容等。写、删除、重命名都会失败,尚未获取动态信息)。
- 在此阶段Namenode收集各个datanode的报告,当数据块达到最小副本数以上时,会被认为是“安全”的, 在一定比例(可设置)的数据块被确定为“安全”后,再过若干时间,安全模式结束
- 当检测到副本数不足的数据块时,该块会被复制直到达到最小副本数,系统中数据块的位置并不是由namenode维护的,而是以块列表形式存储在datanode中。
以上是关于HDFS读写流程的主要内容,如果未能解决你的问题,请参考以下文章