Scrapy 豆瓣电影爬虫
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy 豆瓣电影爬虫相关的知识,希望对你有一定的参考价值。
本篇主要介绍通过scrapy 框架来豆瓣电影
下面我简单总结一下Scrapy爬虫过程:
1、在Item中定义自己要抓取的数据:
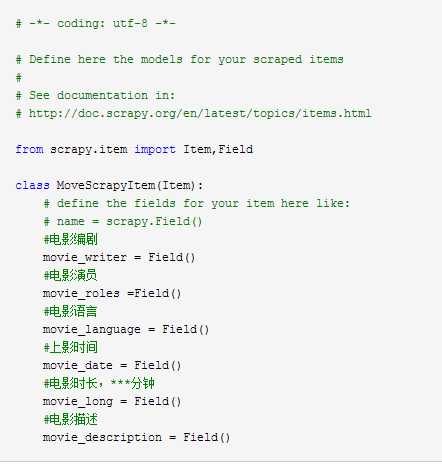
2、编辑在spiders目录下DoubanSpider文件

3、编辑pipelines.py文件,可以通过它将保存在MoveScrapyPipeline中的内容写入到数据库或者文件中
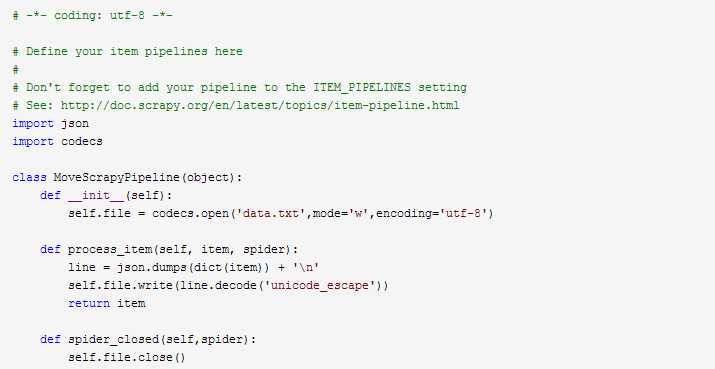
以上是关于Scrapy 豆瓣电影爬虫的主要内容,如果未能解决你的问题,请参考以下文章
(Scrapy框架)爬虫获取豆瓣正在热映的电影信息,xpath属性爬取 | 爬虫案例
运维学python之爬虫高级篇scrapy爬取豆瓣电影TOP250
用Scrapy爬虫爬取豆瓣电影排行榜数据,存储到Mongodb数据库