用Scrapy爬虫爬取豆瓣电影排行榜数据,存储到Mongodb数据库
Posted tsostsos
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Scrapy爬虫爬取豆瓣电影排行榜数据,存储到Mongodb数据库相关的知识,希望对你有一定的参考价值。
爬虫第一步:新建项目
- 选择合适的位置,执行命令:scrapy startproje xxxx(我的项目名:douban)
爬虫第二步:明确目标
- 豆瓣电影排行url:https://movie.douban.com/top250?start=0,
分析url后发现srart=后面的数字,以25的步长递增,最大为225,所以可以利用这个条件来发Request请求 - 本文只取了三个字段,电影名、评分和介绍,当然你想去更多信息也是可以的
- item["name"]:电影名
- item["rating_num"]:评分
- item["inq"]:介绍
- 用xpath提取数据
# 电影名字 extract()方法的作用是将xpath对象转为unicode对象
item["name"] = each.xpath('.//span[@class="title"][1]/text()').extract()[0]
# 评分
item["rating_num"] = each.xpath('.//span[@class="rating_num"]/text()').extract()[0]
# 介绍
item["inq"] = each.xpath('.//span[@class="inq"]/text()').extract()[0]- 写好items.py文件
import scrapy
class DoubanItem(scrapy.Item):
# 电影名
name = scrapy.Field()
# 评分
rating_num = scrapy.Field()
# 介绍
inq = scrapy.Field()爬虫第三步:编写爬虫文件spider
- 这里用spider类,执行命令:scrapy genspider doubanMovie "movie.douban.com"(爬虫名不能和项目名一样)
import scrapy
# 从items.py文件中导入DoubanItem类
from douban.items import DoubanItem
class DoubanmovieSpider(scrapy.Spider):
# 爬虫名
name = 'doubanMovie'
# 允许爬虫的范围
allowed_domains = ['movie.douban.com']
# 构造url地址,因为最后那个数字是变化的,可以动态生成url地址
url = "https://movie.douban.com/top250?start="
offset = 0
start_urls = [url + str(offset)]
# 页面解析函数
def parse(self, response):
# xpath找到一个根节点
datas = response.xpath('//div[@class="item"]//div[@class="info"]')
for each in datas:
# 实例化item对象
item = DoubanItem()
# 电影名字 extract()方法的作用是将xpath对象转为unicode对象
item["name"] = each.xpath('.//span[@class="title"][1]/text()').extract()[0]
# 评分
item["rating_num"] = each.xpath('.//span[@class="rating_num"]/text()').extract()[0]
# 介绍
item["inq"] = each.xpath('.//span[@class="inq"]/text()').extract()[0]
yield item
# 当start后面的数字小于225就一直发请求
if self.offset < 225:
self.offset +=25
# 回调函数仍然是这个方法
yield scrapy.Request(self.url+str(self.offset),callback=self.parse)爬虫第四步:存储内容,编写管道文件pipeline.py
- 将数据存储在Mongodb数据库里,需要先在配置文件里配置主机、端口、数据库名、表名,四个字段的数据(当然你也可以选择在pipelinse文件中写)
# python中操作Mongodb数据库是通过pymongo这个模块来实现的,所以要导入这个模块
import pymongo
# 导入setting.py中的相关内容
from scrapy.utils.project import get_project_settings
class DoubanPipeline(object):
def __init__(self):
settings = get_project_settings()
# 主机ip
host = settings["MONGODB_HOST"]
# port
port = settings["MONGODB_PORT"]
# 数据库名
dbname = settings['MONGODB_DBNAME']
# 表名
sheetname= settings['MONGODB_SHEETNAME']
# 创建数据库连接
client = pymongo.MongoClient(host=host,port=port)
# 指定数据库
mydb = client[dbname]
# 指定数据库表名字
self.sheet = mydb[sheetname]
def process_item(self, item, spider):
# 转为字典格式
data = dict(item)
# 插入数据
self.sheet.insert(data)
return item最后配置完setting.py文件就可以运行了
- 以下只是需要添加或修改的代码,没有贴全
# 这个需要自己取消注释,才会执行我们的管道方法
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,
}
# MONGODB 主机名
MONGODB_HOST = "127.0.0.1"
# MONGODB 端口号
MONGODB_PORT = 27017
# MONGODB 数据库名
MONGODB_DBNAME = "Douban"
# MONGODB 存放的表名
MONGODB_SHEETNAME = "doubanmovies"运行结果
- 用Robo 3T可视化工具查看数据:
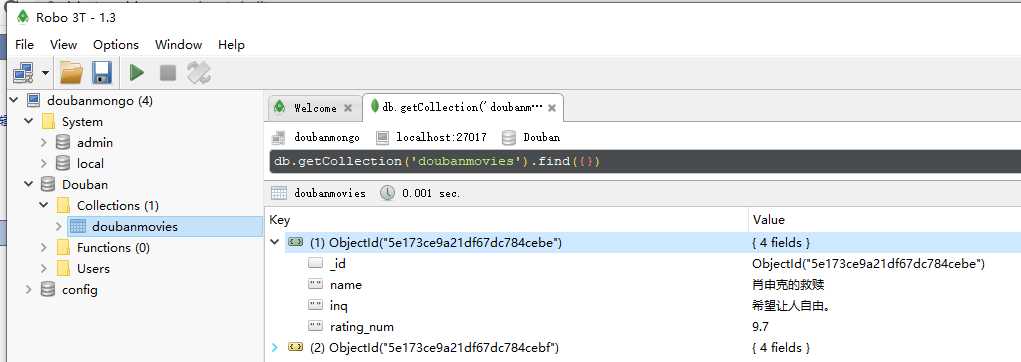
如图是拿到的250条数据,第一个是肖申克的救赎。
以上是关于用Scrapy爬虫爬取豆瓣电影排行榜数据,存储到Mongodb数据库的主要内容,如果未能解决你的问题,请参考以下文章
(Scrapy框架)爬虫获取豆瓣正在热映的电影信息,xpath属性爬取 | 爬虫案例