第二篇:使用Spark对MovieLens的特征进行提取
Posted 穆晨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第二篇:使用Spark对MovieLens的特征进行提取相关的知识,希望对你有一定的参考价值。
前言
在对数据进行了初步探索后,想必读者对MovieLens数据集有了感性认识。而在数据挖掘/推荐引擎运行前,往往需要对数据预处理。预处理的重要性不言而喻,甚至比数据挖掘/推荐系统本身还重要。
然而完整的数据预处理工作会涉及到:缺失值,异常值,口径统一,去重,特征提取等等等等,可以单写一本书了,本文无法一一介绍。
本文仅就特征提取这一话题进行粗略讨论并展示。
类别特征提取
在很多场景下,数据集的很多特征是类型变量,比如MovieLens里面的职业类型。这样的变量无法作为很多算法的输入,因为这类变量无法作用于样本间距离的计算。
可参考的方法是 1 of k 编码,就是将某种类型的特征打平,将其转化为具有n列的向量。具体的做法是先为特征列创建字典,然后将各具体特征值映射到 1 of k 编码。
下面以MoveiLens中的职业类型特征为例,演示特征值为programmer的特征提取:
1 # 载入数据集 2 user_data = sc.textFile("/home/kylin/ml-100k/u.user") 3 # 以\' | \'切分每列,返回新的用户RDD 4 user_fields = user_data.map(lambda line: line.split("|")) 5 # 获取职业RDD并落地 6 all_occupations = user_fields.map(lambda fields: fields[3]).distinct().collect() 7 # 对各职业进行排序 8 all_occupations.sort() 9 10 # 构建字典 11 idx = 0 12 all_occupations_dict = {} 13 for o in all_occupations: 14 all_occupations_dict[o] = idx 15 idx +=1 16 17 # 生成并打印职业为程序员(programmer)的1 of k编码 18 K = len(all_occupations_dict) 19 binary_x = np.zeros(K) 20 k_programmer = all_occupations_dict[\'programmer\'] 21 binary_x[k_programmer] = 1 22 print "程序员的1 of k编码为: %s" % binary_x
结果为:

派生特征提取
并非所有的特征均可直接拿来学习。比如电影发行日期特征,它显然无法拿来进行学习。但正如上一节所做的一个工作,将它转化为电影年龄,这就可以在很多场景下进行学习了。
再比如时间戳属性,可参考将他们转为为:早/中/晚这样的分类变量:
1 # 载入数据集 2 rating_data_raw = sc.textFile("/home/kylin/ml-100k/u.data") 3 # 获取评分RDD 4 rating_data = rating_data_raw.map(lambda line: line.split("\\t")) 5 ratings = rating_data.map(lambda fields: int(fields[2])) 6 7 # 函数: 将时间戳格式转换为datetime格式 8 def extract_datetime(ts): 9 import datetime 10 return datetime.datetime.fromtimestamp(ts) 11 12 # 获取小时RDD 13 timestamps = rating_data.map(lambda fields: int(fields[3])) 14 hour_of_day = timestamps.map(lambda ts: extract_datetime(ts).hour) 15 16 # 函数: 将小时映射为分类变量并展示 17 def assign_tod(hr): 18 times_of_day = { 19 \'morning\' : range(7, 12), 20 \'lunch\' : range(12, 14), 21 \'afternoon\' : range(14, 18), 22 \'evening\' : range(18, 23), 23 \'night\' : range(23, 7) 24 } 25 for k, v in times_of_day.iteritems(): 26 if hr in v: 27 return k 28 29 # 获取新的分类变量RDD 30 time_of_day = hour_of_day.map(lambda hr: assign_tod(hr)) 31 time_of_day.take(5)
结果为:

若要使用这个特征,大部分机器学习算法可以考虑将其1 of k编码。部分支持分类型变量的算法除外。
PS:有两个None是因为代码中night:range(23,7)这么写是不对的。算了不纠结,意思懂就好 :)
文本特征提取
关于文本特征提取方法有很多,本文仅介绍一个简单而又经典的提取方法 - 词袋法。
其基本步骤如下:
1. 分词 - 将文本分割为由词组成的集合。可根据空格符,标点进行分割;
2. 删除停用词 - the and 这类词无学习的价值意义,删除之;
3. 提取词干 - 将各个词转化为其基本形式,如men -> man;
4. 向量化 - 从根本上来说和1 of k相同。不过由于词往往很多,所以稀疏矩阵技术很重要;
下面将MovieLens数据集中的影片标题进行特征提取:
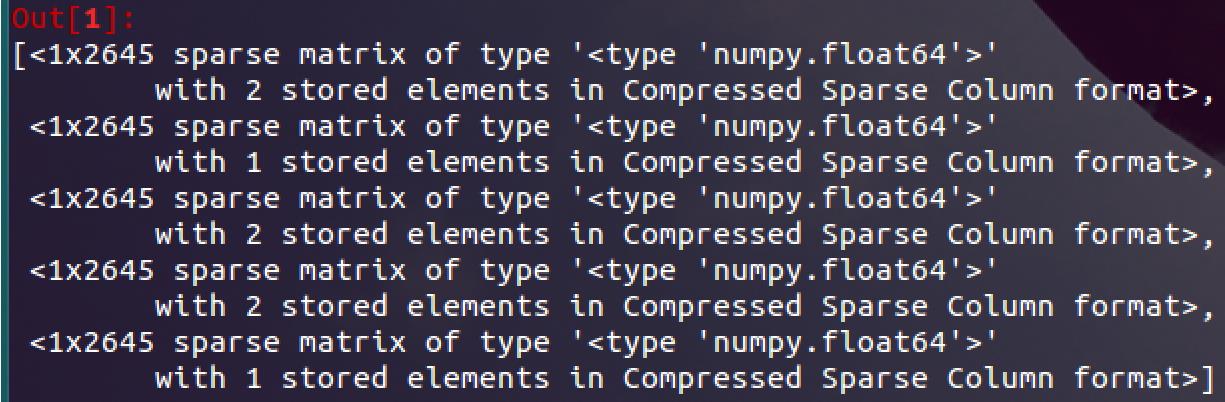
1 # 载入数据集 2 movie_data = sc.textFile("/home/kylin/ml-100k/u.item") 3 # 以\' | \'切分每列,返回影片RDD 4 movie_fields = movie_data.map(lambda lines: lines.split("|")) 5 6 # 函数: 剔除掉标题中的(年份)部分 7 def extract_title(raw): 8 import re 9 grps = re.search("\\((\\w+)\\)", raw) 10 if grps: 11 return raw[:grps.start()].strip() 12 else: 13 return raw 14 15 # 获取影片名RDD 16 raw_titles = movie_fields.map(lambda fields: fields[1]) 17 18 # 剔除影片名中的(年份) 19 movie_titles = raw_titles.map(lambda m: extract_title(m)) 20 21 # 由于仅仅是个展示的例子,简简单单用空格分割 22 title_terms = movie_titles.map(lambda t: t.split(" ")) 23 24 # 搜集所有的词 25 all_terms = title_terms.flatMap(lambda x: x).distinct().collect() 26 # 创建字典 27 idx = 0 28 all_terms_dict = {} 29 for term in all_terms: 30 all_terms_dict[term] = idx 31 idx +=1 32 num_terms = len(all_terms_dict) 33 34 # 函数: 采用稀疏向量格式保存编码后的特征并返回 35 def create_vector(terms, term_dict): 36 from scipy import sparse as sp 37 x = sp.csc_matrix((1, num_terms)) 38 for t in terms: 39 if t in term_dict: 40 idx = term_dict[t] 41 x[0, idx] = 1 42 return x 43 44 # 将字典保存为广播数据格式类型。因为各个worker都要用 45 all_terms_bcast = sc.broadcast(all_terms_dict) 46 # 采用稀疏矩阵格式保存影片名特征 47 term_vectors = title_terms.map(lambda terms: create_vector(terms, all_terms_bcast.value)) 48 # 展示提取结果 49 term_vectors.take(5)
其中,字典的创建过程也可以使用Spark提供的便捷函数zipWithIndex,这个函数可以将原RDD中的值作为主键,而新的值为主键在原RDD中的位置:
1 all_terms_dict2 = title_terms.flatMap(lambda x: x).distinct().zipWithIndex().collectAsMap()
collectAsMap则是将结果落地为Python的dict格式。
结果为:
归一化特征
归一化最经典的做法就是所有特征值-最小值/特征区间。但对于一般特征的归一化网上很多介绍,请读者自行学习。本文仅对特征向量的归一化做介绍。
一般来说,我们是先计算向量的二阶范数,然后让向量的所有元素去除以这个范数。
下面演示对某随机向量进行归一化:
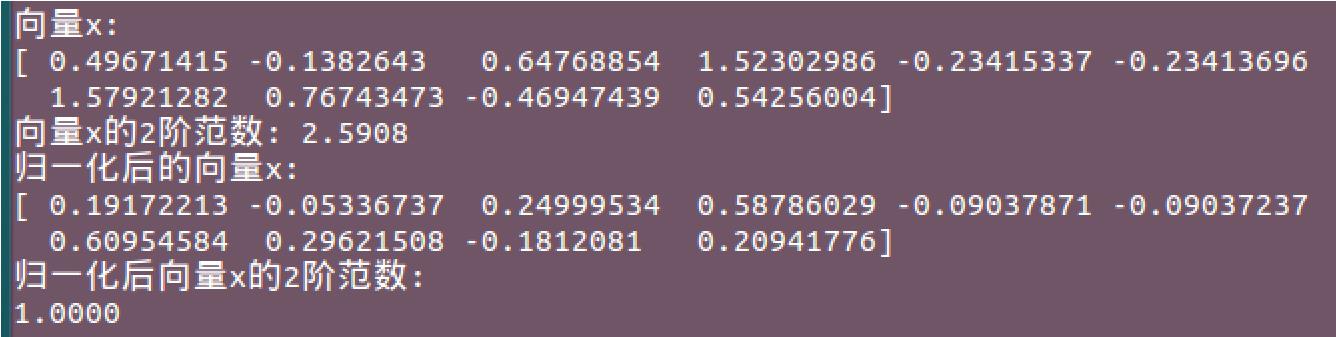
1 # 设置随机数种子 2 np.random.seed(42) 3 # 生成随机向量 4 x = np.random.randn(10) 5 # 产生二阶范数 6 norm_x_2 = np.linalg.norm(x) 7 # 归一化 8 normalized_x = x / norm_x_2 9 10 # 结果展示 11 print "向量x:\\n%s" % x 12 print "向量x的2阶范数: %2.4f" % norm_x_2 13 print "归一化后的向量x:\\n%s" % normalized_x 14 print "归一化后向量x的2阶范数:\\n%2.4f" % np.linalg.norm(normalized_x)
结果为:
Spark的MLlib库提供了专门的正则化函数,它们执行起来的效率显然远远高于我们自己写的:
1 # 导入Spark库中的正则化类 2 from pyspark.mllib.feature import Normalizer 3 # 初始化正则化对象 4 normalizer = Normalizer() 5 # 创建测试向量(RDD) 6 vector = sc.parallelize([x]) 7 # 对向量进行归一化并返回结果 8 normalized_x_mllib = normalizer.transform(vector).first().toArray() 9 10 # 结果展示 11 print "向量x:\\n%s" % x 12 print "向量x的二阶范数: %2.4f" % norm_x_2 13 print "被MLlib归一化后的向量x:\\n%s" % normalized_x_mllib 14 print "被MLlib归一化后的向量x的二阶范数: %2.4f" % np.linalg.norm(normalized_x_mllib)
结果请读者自行对比。
以上是关于第二篇:使用Spark对MovieLens的特征进行提取的主要内容,如果未能解决你的问题,请参考以下文章