第一篇:使用Spark探索经典数据集MovieLens
Posted 穆晨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第一篇:使用Spark探索经典数据集MovieLens相关的知识,希望对你有一定的参考价值。
前言
MovieLens数据集包含多个用户对多部电影的评级数据,也包括电影元数据信息和用户属性信息。
这个数据集经常用来做推荐系统,机器学习算法的测试数据集。尤其在推荐系统领域,很多著名论文都是基于这个数据集的。(PS: 它是某次具有历史意义的推荐系统竞赛所用的数据集)。
下载地址为:http://files.grouplens.org/datasets/movielens/,有好几种版本,对应不同数据量,可任君选用。
本文下载数据量最小的100k版本,对该数据集进行探索:
环境
本人机器所用的操作系统为号称国产操作系统的Ubuntu Kylin 14.04,美化后的界面还是蛮酷炫的:
spark版本为:v1.5.2,下面是集成了Ipython,pylab的python-shell:

初步预览
1. 首先是用户信息:
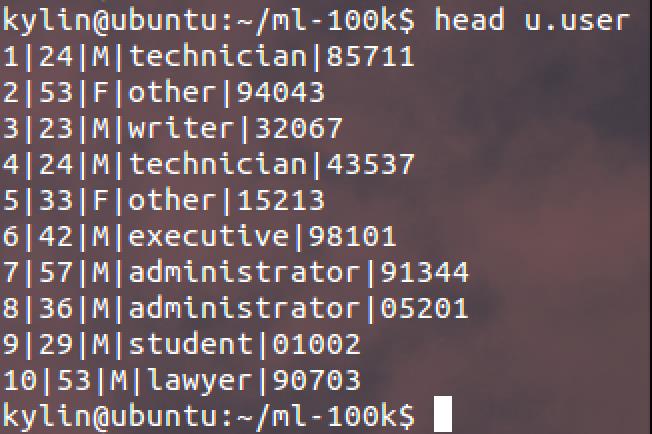
其中各列数据分别为:
用户id | 用户年龄 | 用户性别 | 用户职业 | 用户邮政编码
2. 然后是影片信息:

其中前几列数据分别为:
影片id | 影片名 | 影片发行日期 | 影片链接 | (后面几列先不去管)
3. 最后是评分数据:

用户id | 影片id | 评分值 | 时间戳(timestamp格式)
探索用户数据
1. 打开Spark的python-shell,执行以下代码载入数据集并打印首行记录:
1 # 载入数据集 2 user_data = sc.textFile("/home/kylin/ml-100k/u.user") 3 # 展示首行记录 4 user_data.first()
结果如下:

2. 分别统计用户,性别,职业的个数:
1 # 以\' | \'切分每列,返回新的用户RDD 2 user_fields = user_data.map(lambda line: line.split("|")) 3 # 统计用户数 4 num_users = user_fields.map(lambda fields: fields[0]).count() 5 # 统计性别数 6 num_genders = user_fields.map(lambda fields: fields[2]).distinct().count() 7 # 统计职业数 8 num_occupations = user_fields.map(lambda fields: fields[3]).distinct().count() 9 # 统计邮编数 10 num_zipcodes = user_fields.map(lambda fields: fields[4]).distinct().count() 11 # 返回结果 12 print "用户数: %d, 性别数: %d, 职业数: %d, 邮编数: %d" % (num_users, num_genders, num_occupations, num_zipcodes)
结果如下:

3. 查看年龄分布情况:
1 # 获取用户年龄RDD,并将其落地到驱动程序 2 ages = user_fields.map(lambda x: int(x[1])).collect() 3 # 绘制用户年龄直方图 4 hist(ages, bins=20, color=\'lightblue\', normed=True)
结果如下:

18岁以上观看者人数激增,估计是“高考”完了时间多了?
20多岁的年轻人,我猜主要是大学生和刚工作不久的年轻人?观看者最多。
然后50岁的观看者也蛮多的,估计是快退休了,开始享受生活了。
4. 查看职业分布情况:
1 # 并行统计各职业人数的个数,返回职业统计RDD后落地 2 count_by_occupation = user_fields.map(lambda fields: (fields[3], 1)).reduceByKey(lambda x, y: x + y).collect() 3 4 # 生成x/y坐标轴 5 x_axis1 = np.array([c[0] for c in count_by_occupation]) 6 y_axis1 = np.array([c[1] for c in count_by_occupation]) 7 x_axis = x_axis1[np.argsort(y_axis1)] 8 y_axis = y_axis1[np.argsort(y_axis1)] 9 10 # 生成x轴标签 11 pos = np.arange(len(x_axis)) 12 width = 1.0 13 ax = plt.axes() 14 ax.set_xticks(pos + (width / 2)) 15 ax.set_xticklabels(x_axis) 16 17 # 绘制职业人数条状图 18 plt.xticks(rotation=30) 19 plt.bar(pos, y_axis, width, color=\'lightblue\')
值得注意的是,统计各职业人数的时候,是将不同职业名记录搜集到不同节点,然后开始并行统计。
结果如下:

果然,是学生,教育工作者观看影片的多。
不过程序猿观众也不少...... 医生是最少看电影的。
这里再给出一种统计各职业人数的解决方案:
1 count_by_occupation2 = user_fields.map(lambda fields: fields[3]).countByValue()
countByValue是Spark提供的便捷函数,它会自动统计每个Key下面的Value个数,并以字典的格式返回。
探索电影数据
1. 打开Spark的python-shell,执行以下代码载入数据集并打印首行记录:
1 # 载入数据集 2 movie_data = sc.textFile("/home/kylin/ml-100k/u.item") 3 # 展示首行记录 4 print movie_data.first()
结果如下:

2. 查看下有多少部电影吧:
1 num_movies = movie_data.count() 2 print num_movies
结果为: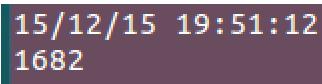
3. 过滤掉没有发行时间信息的记录:
1 # 输入影片的发行时间字段,若非法则返回1900 2 def convert_year(x): 3 try: 4 return int(x[-4:]) 5 except: 6 return 1900 7 8 # 以\' | \'切分每列,返回影片RDD 9 movie_fields = movie_data.map(lambda lines: lines.split("|")) 10 # 生成新的影片发行年份RDD,并将空/异常的年份置为1900, 11 years = movie_fields.map(lambda fields: fields[2]).map(lambda x: convert_year(x)) 12 # 过滤掉影片发行年份RDD中空/异常的记录 13 years_filtered = years.filter(lambda x: x != 1900)
4. 统计影片的年龄分布:
1 # 生成影片年龄RDD,然后统计不同年龄的影片数并落地 2 movie_ages = years_filtered.map(lambda yr: 1998-yr).countByValue() 3 # 获得影片数 4 values = movie_ages.values() 5 # 获得年龄 6 bins = movie_ages.keys() 7 # 绘制电影年龄分布图 8 hist(values, bins=bins, color=\'lightblue\', normed=True)
因为这份数据集比较老,1998年提供的,所以就按当时的年龄来统计吧。另外这次使用了countByValue来统计个数,而它是执行函数,不需要再collect了。
结果为:
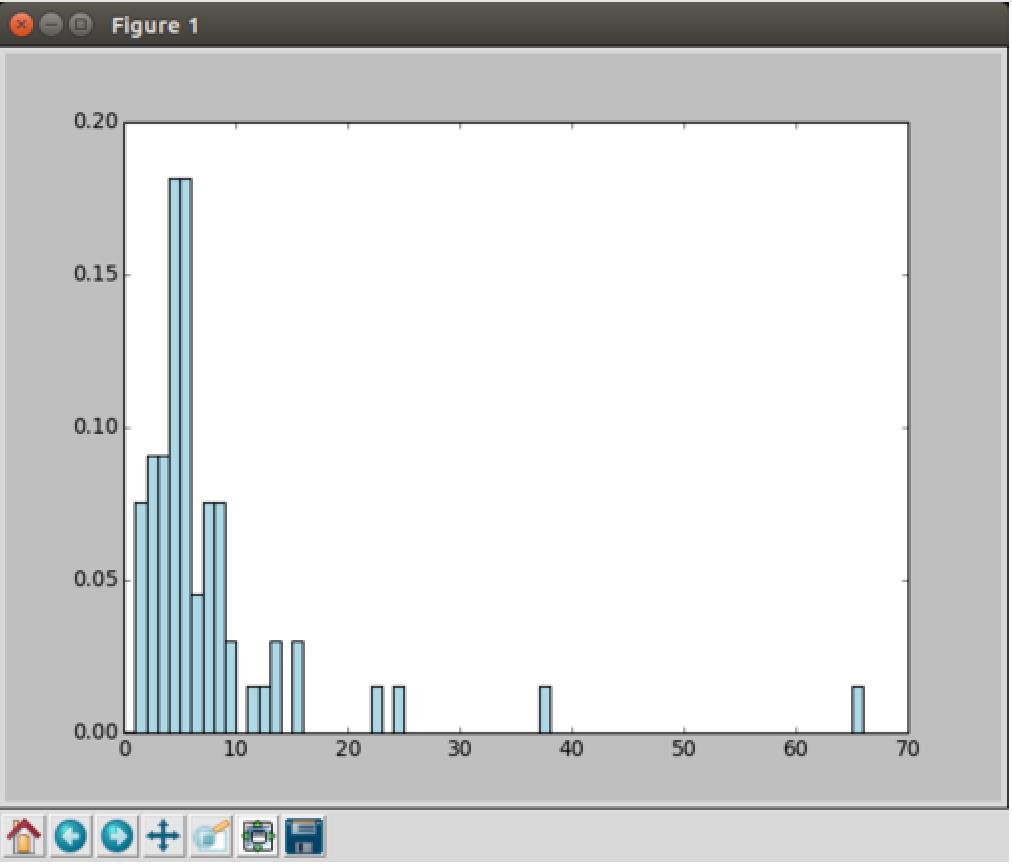
看得出电影库中的电影大都还是比较新的。
探索评级数据
1. 打开Spark的python-shell,执行以下代码载入数据集并打印首行记录:
1 # 载入数据集 2 rating_data_raw = sc.textFile("/home/kylin/ml-100k/u.data") 3 # 展示首行记录 4 print rating_data_raw.first()
结果为:

2. 先看看有多少评分记录吧:
1 num_ratings = rating_data .count() 2 print num_ratings
结果为: 。果然共有10万条记录,没下载错版本。
。果然共有10万条记录,没下载错版本。
3. 统计最高评分,最低评分,平均评分,中位评分,平均每个用户的评分次数,平均每部影片被评分次数:
1 # 获取评分RDD 2 rating_data = rating_data_raw.map(lambda line: line.split("\\t")) 3 ratings = rating_data.map(lambda fields: int(fields[2])) 4 # 计算最大/最小评分 5 max_rating = ratings.reduce(lambda x, y: max(x, y)) 6 min_rating = ratings.reduce(lambda x, y: min(x, y)) 7 # 计算平均/中位评分 8 mean_rating = ratings.reduce(lambda x, y: x + y) / float(num_ratings) 9 median_rating = np.median(ratings.collect()) 10 # 计算每个观众/每部电影平均打分/被打分次数 11 ratings_per_user = num_ratings / num_users 12 ratings_per_movie = num_ratings / num_movies 13 # 输出结果 14 print "最低评分: %d" % min_rating 15 print "最高评分: %d" % max_rating 16 print "平均评分: %2.2f" % mean_rating 17 print "中位评分: %d" % median_rating 18 print "平均每个用户打分(次数): %2.2f" % ratings_per_user 19 print "平均每部电影评分(次数): %2.2f" % ratings_per_movie
结果为:
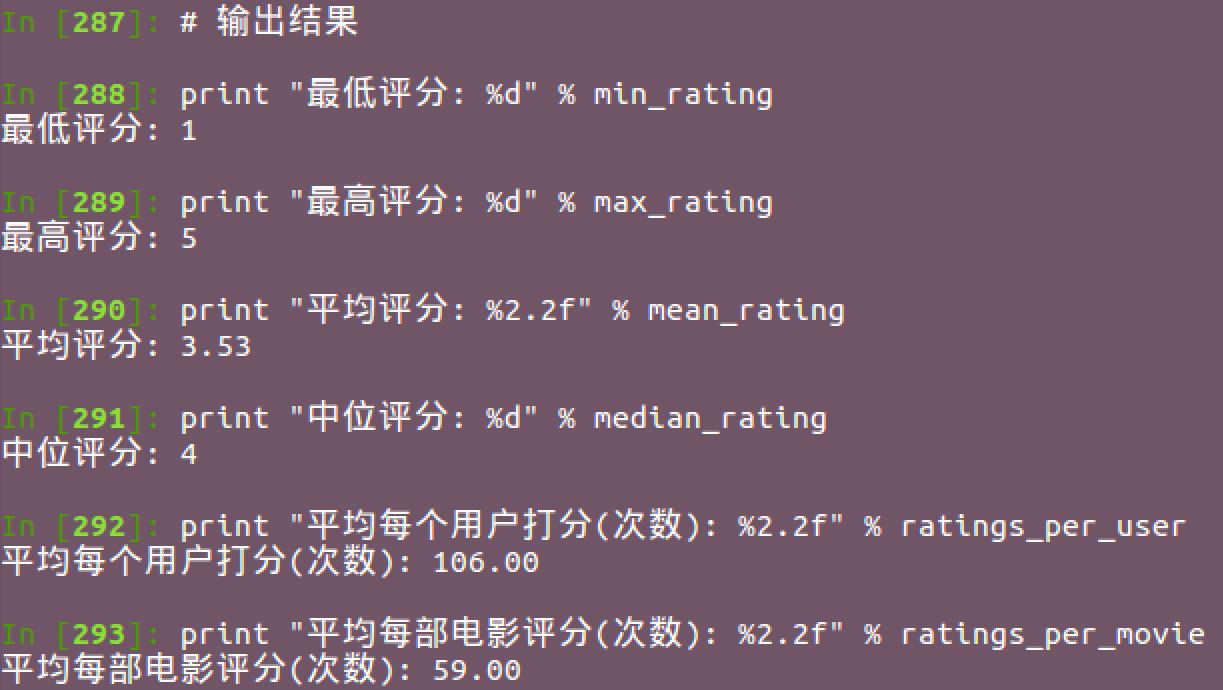
另外Spark有个挺实用的统计函数stats可直接获取常用的统计信息,类似R语言的summary函数:
ratings.stats()
结果为:

4. 统计评分分布:
1 # 生成评分统计RDD,并落地 2 count_by_rating = ratings.countByValue() 3 # 生成x/y坐标轴 4 x_axis = np.array(count_by_rating.keys()) 5 y_axis = np.array([float(c) for c in count_by_rating.values()]) 6 # 对人数做标准化 7 y_axis_normed = y_axis / y_axis.sum() 8 9 # 生成x轴标签 10 pos = np.arange(len(x_axis)) 11 width = 1.0 12 ax = plt.axes() 13 ax.set_xticks(pos + (width / 2)) 14 ax.set_xticklabels(x_axis) 15 16 # 绘制评分分布柱状图 17 plt.bar(pos, y_axis_normed, width, color=\'lightblue\') 18 plt.xticks(rotation=30)
结果为:
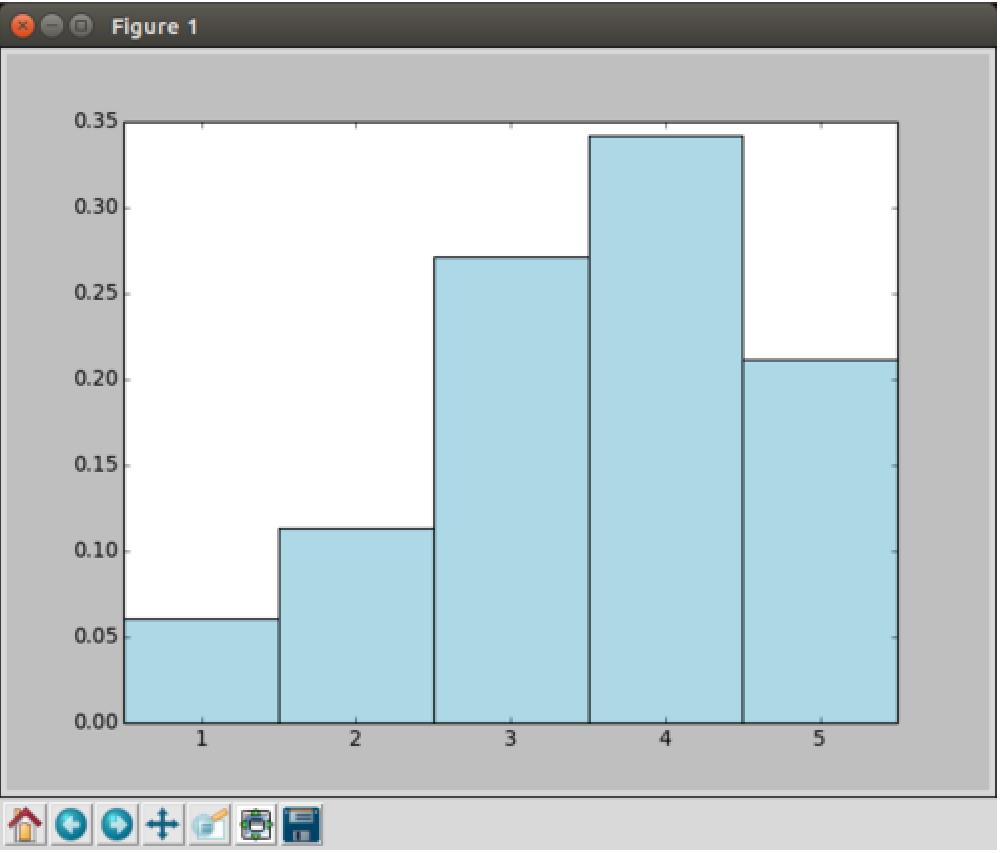
评分分布看来也应该挺满足正态分布的。
5. 统计不同用户的评分次数:
1 # 首先将数据以用户id为Key分发到各个节点 2 user_ratings_grouped = rating_data.map(lambda fields: (int(fields[0]), int(fields[2]))).groupByKey() 3 # 然后统计每个节点元素的个数,也即每个用户的评论次数 4 user_ratings_byuser = user_ratings_grouped.map(lambda (k, v): (k, len(v))) 5 # 输出前5条记录 6 user_ratings_byuser.take(5)
注意到这次使用了groupyByKey方法,这个方法和reduceByKey功能有点相似,但是有区别。请读者自行百度。
结果为:

以上是关于第一篇:使用Spark探索经典数据集MovieLens的主要内容,如果未能解决你的问题,请参考以下文章