初识正则表达式
Posted 叶祖辉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初识正则表达式相关的知识,希望对你有一定的参考价值。
1>概念:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。正则表达式就是记录文本规则的代码。
所以正则表达式并不是python中特有的功能,它是一种通用的方法。python中的正则表达式库,所做的事情是利用正则表达式来搜索文本。要使用它,你必须会自己用正则表达式来描述文本规则
4>字符匹配(普通字符,元字符):
普通字符:大多数数字和字母的任意集合
元字符:在正则表达式中具有特殊意义的专用字符
5>元字符
. :匹配除换行符以外的任意字符
^ :匹配字符串的开始(从字符串开头开始匹配)…………放到集合中的时候表示“非”
$ : 匹配字符串的结尾(从字符串的结尾开始匹配)
* : 匹配前面的子表达式零次或多次…………po*等价于子表达式可能是p、po、poo、pooo.......
+ :匹配前面的子表达式一次或多次…………po+等价于子表达式可能是po、poo、pooo.......
? :匹配前面的子表达式零次或一次…………po?等价于子表达式可能是p、po
| :将俩个匹配条件进行逻辑“或”运算
\\ :反斜杠后面跟元字符去除其特殊功能
反斜杠后面跟普通字符实现特殊功能
引用序号所对应的字组所匹配的字符串…………re.search(r"(alex)(eric)com\\2","alexericcomeric")
\\d :匹配任意一个数字字符…………相当于[0-9]
\\D :匹配任意一个非数字字符………相当于[^0-9]
\\s :匹配任意一个不可见字符,包括空格、制表符、换页符等等…………等价于[ \\t\\n\\r\\f\\v]
\\S :匹配任意一个可见字符…………等价于[^ \\t\\n\\r\\f\\v]
\\w :匹配任意一个字母或数字或下划线或汉字…………等价于[a-zA-Z0-9_]
\\W :匹配任意一个非字母或数字或下划线或汉字…………等价于[^a-zA-Z0-9_]
\\b :匹配一个单词边界,也就是指单词和空格间的位置。
\\n :匹配一个换行符
\\f :匹配一个换页符
\\r :匹配一个回车符
[a-z] :匹配括号中所包含的任意一个字符………-表示范围
[^a-z] :匹配任何不在指定范围内的字符…………其中^表示非得意思
[] :表示一个字符集,特殊字符在字符集中会失去其特殊意义(“^” 在字符集中是非得意思 “-”在字符集中是至的意思 “\\d” "\\w"等等还保留其原有意义)
{n} :n是一个非负整数 ,匹配整数n次
{n,} :n是一个非负整数,至少匹配n次
{n,m} :m,n均为非负整数,m>n,最少匹配n次,最多匹配m次
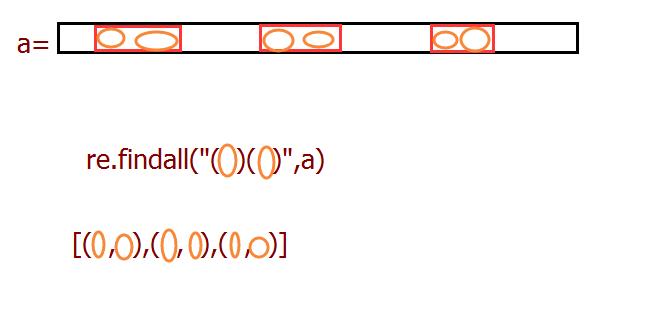
() :表示分组,利用findall匹配时,只输出的组里面的内容,并组成一个新组放到列表中
利用search和match匹配时,输出全部内容,可以用group方法取出来各个组的内容
a=re.findall(r"(123)(asd)\\1","123asd123") b=re.findall(r"(123)(asd)(123)","123asd123") c=re.findall(r"(123)(asd)123","123asd123") d=re.findall(r"(123)(asd)","123asd123") print(a) print(b) print(c) print(d) [(\'123\', \'asd\')]
[(\'123\', \'asd\', \'123\')]
[(\'123\', \'asd\')]
[(\'123\', \'asd\')]
import re a=re.search(r"(123)(asd)\\1","123asd123").group() b=re.search(r"(123)(asd)(123)","123asd123").group() c=re.search(r"(123)(asd)123","123asd123").group() d=re.search(r"(123)(asd)","123asd123").group() print(a) print(b) print(c) 123asd123
123asd123
123asd123
123asd

6、flags(编译标志符):
re.I 使匹配对大小写不敏感
re.M 多行匹配
re.S 使.匹配包括换行在内的所有字符
re.X 正则表达式里面可以有注释 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解
7、re模块
python中正则表达式封装在re模块中,要想使用的话必须调用(import re),re模块下有常用的几种方法:
1、match(pattern, string, flags=0):
2、search(pattern, string, flags=0):
pattern:表示匹配规则
string:表示字符串
flags:表示编译标志位,匹配模式,用于修改正则表达式的匹配方式,如:是否区分大小写,多行匹配等等
从起始位置开始根据模型规则去字符串中匹配指定内容,只能匹配单个,如果匹配成功返回一个match object对象,利用group方法查看,没匹配到返回None
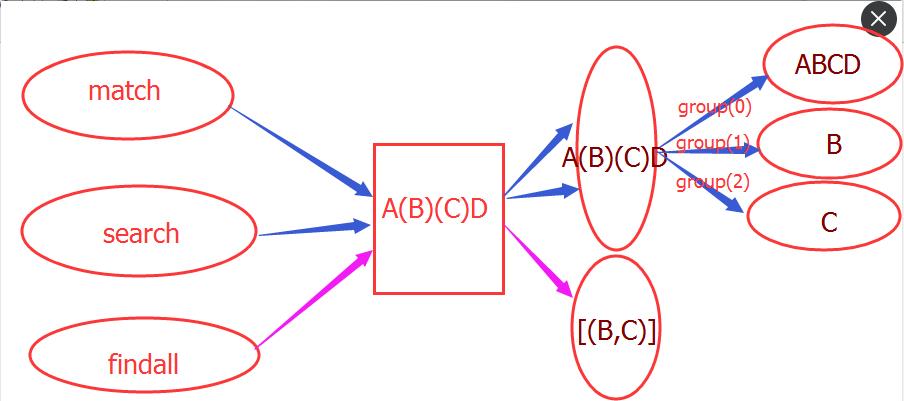
match (search) object的方法: 1、group() 返回re整体匹配的字符串,可以一次输入多个组号,对应组号匹配的字符串,获取匹配到的所有结果(无论是否有组)
import re
a="hello alex asd hello"
b=re.match("(h)\\w+",a).group()
print(b)
hello
2、start() 返回匹配开始的位置
3、end() 返回匹配结束的位置
4、span() 返回一个元组包含匹配 (开始,结束) 的位置
5、groups() 获取已经匹配到的结果中的分组结果放到元祖中,从group结果中提取分组结果
import re
a="hello alex asd hello"
b=re.match("(h)(e)\\w+",a).groups()
print(b)
(\'h\', \'e\')
6、groupdict() (?p<name>h) 给分组中的元素一个key值组成一个字典
import re
a="hello alex asd hello"
b=re.match("(?P<n1>h)(?P<n2>e)\\w+",a).groupdict() #其中P为大写
print(b)
{\'n2\': \'e\', \'n1\': \'h\'}
3、findall(pattern, string, flags=0):
从起始位置开始根据模型规则去字符串中匹配指定内容,能全部匹配,如果匹配成功以列表形式返回所有匹配的字符串,没匹配到返回None
findall匹配时,如果规则中是匹配集合"a()b",则只输出()中的内容、search和match不是,如果想输出全部内容,在分组内加"?:"
import re
a="hello alex asd hello"
b=re.findall("a(?:l)ex",a)
print(b)
[\'alex\']
匹配规则(此处是小坑)
正则中匹配规则是从前往后匹配,一个一个找,但如果匹配到内容后,继续再往后匹配的时候是从上一次匹配的结尾开始重新匹配
import re
a="1a2s3d4f5"
b=re.findall("\\d\\w\\d",a)
print(b)
[\'1a2\', \'3d4\']
匹配规则(此处tmd又是一个小坑)
正则中如果用空("")来匹配内容时,匹配到的空内容会比其长度多一位
import re
a="12345"
b=re.findall("",a)
print(b)
[\'\', \'\', \'\', \'\', \'\', \'\'] #里面6个空
匹配组中组(太tm绕了)
import re
a="asd alex 123 alex"
b=re.findall("(a)(\\w(e))(x)",a) #先提取第一个组中a,再提取第二组中le 再提取组中组e再提取组x
print(b)
[(\'a\', \'le\', \'e\', \'x\'), (\'a\', \'le\', \'e\', \'x\')] #从左到右,从外到内的提取
又一个坑来了(有几个组提取几个内容,看表象就是看我问看到几个组"()")
import re
a="alex"
b=re.findall("(\\w)(\\w)(\\w)(\\w)",a) #有几个组提取几个内容
c=re.findall("(\\w){4}",a) #一个组里面的内容出现四次,默认去最后一个内容
print(b)
print(c)
[(\'a\', \'l\', \'e\', \'x\')]
[\'x\']
4、sub(pattern, repl, string, max=0):
subn(pattern, repl, string):结果能显示到底被替换了几次
pattern:表示匹配规则
repl:替换对象(用什么替换)
string:被替换对象
max:替换的个数
import re
re.sub("g.t","have",\'I get A, I got B ,I gut C\',2)
I have A, I have B ,I gut C
import re
print(re.subn("g.t","have",\'I get A, I got B ,I gut C\'))
(\'I have A, I have B ,I have C\', 3)
5、compile(strPattern[, flag]):
strPattern:将字符串形式的正则表达式编译为Pattern对象
flag:是匹配模式,取值可以使用按位或运算符\'|\'表示同时生效,比如re.I | re.M
把一套规则利用compile方法封装在一个对象中,再利用对象调用方法,适用于多次匹配情况
import re text = "JGood is a handsome boy,he is cool, clever, and so on..." regex = re.compile(r\'\\w*oo\\w*\') print (regex.findall(text) ) #查找所有包含\'oo\'的单词 [\'JGood\', \'cool\']
6、split(pattern, string, maxsplit=0, flags=0):
pattern:表示匹配规则
string:表示字符串
maxsplit:表示分割的位数(用几个规则分割)
flags:表示编译标志位,用于修改正则表达式的匹配方式,如:是否区分大小写,多行匹配等等
import re print(re.split(\'\\d+\',\'one12two2three3four4\')) [\'one\', \'two\', \'three\', \'four\', \'\']
import re print(re.split(\'a\',\'1A1a2a3\',flags=re.I)) #如果直接写re.I 默认把其放到第三位,不能起到作用 [\'1\', \'1\', \'2\', \'3\']
用正则分割出来的列表中不含有分割部分,如果需要把拿什么分割出来的部分显示在列表中的话就需要在表达式中加入组
import re
a="asd123asd156asd"
c=re.split("(1)(\\d+)",a)
print(c)
[\'asd\', \'1\', \'23\', \'asd\', \'1\', \'56\', \'asd\']
7、finditer(pattern, string, flags=0):
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器
import re
iterator = re.finditer(r\'\\d+\',\'2g3g4g5g6g\')
iterator1 = re.findall(r\'\\d+\',\'2g3g4g5g6g\')
print(iterator)
print(iterator1)
for match in iterator:
print(match.group(), match.span())
<callable_iterator object at 0x0000008310911128>
[\'2\', \'3\', \'4\', \'5\', \'6\']
2 (0, 1)
3 (2, 3)
4 (4, 5)
5 (6, 7)
6 (8, 9)
8、数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。但当前后都有限定条件时,非贪婪模式失效。
9、返斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\\\"表示。同样,匹配一个数字的"\\\\d"可以写成r"\\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
小结:
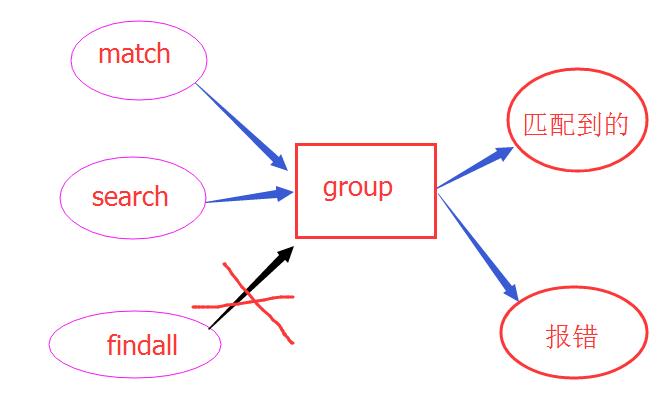
group是match和search的方法,findall没有group方法,如果march和search匹配成功,则返回一个 "Match object"对象,没有匹配成功则返回一个None,只有匹配成功才有group方法,否则会报错
如果前后均有限定条件,则非贪婪模式失效
import re print(re.findall(r"a(\\d+)", "a23b")) #贪婪模式 print(re.findall(r"a(\\d+?)", "a23b")) # 非贪婪模式 print(re.findall(r"a(\\d+?)b","a23b")) #前后有限定条件 非贪婪模式失效 [\'23\'] [\'2\'] [\'23\']
findall匹配时,如果规则中是匹配集合"a()b",则只输出()中的内容、search和match不是,如果也想输出括号外的内容在括号前面加"?:"
import re print(re.findall(r"a(\\d+)b", "a23b")) #获取组()中的文件 print(re.search(r"a(\\d+)b", "a23b").group())
print(re.match(r"a(\\d+)b", "a23b").group()) [\'23\'] a23b
a23b
import re
a=re.findall(r"(?:123)(?:asd)123","123asd123") print(a) [\'123asd123\']
match和search在匹配有集合()的时候,会把括号内外的字符都输出出来,而且可以通过组号来调取不同组中的内容,而findall只会通过列表输出括号内的内容
import re print(re.search(r"m(alex)(eric)com\\2m","mmalexericcomericmmm").group()) #默认group中参数为0 print(re.search(r"m(alex)(eric)com\\2m","mmalexericcomericmmm").group(1)) #调取第一个组的内容 print(re.search(r"m(alex)(eric)com\\2m","mmalexericcomericmmm").group(2)) #调取第二个组的内容 print(re.match(r"m(alex)(eric)com\\2m","malexericcomericmmm").group()) #其中\\2只是代表了第二组的内容,而没有括号 print(re.match(r"m(alex)(eric)com\\2m","malexericcomericmmm").group(1)) print(re.match(r"m(alex)(eric)com\\2m","malexericcomericmmm").group(2)) print(re.findall(r"m(alex)(eric)com(eric)m","malexericcomericmmm")) malexericcomericm alex eric malexericcomericm alex eric [(\'alex\', \'eric\', \'eric\')]
计算器
计算表达式:a = " 1 - 2 * ( (60-30 +(-40.0/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )"
 View Code
View Code模块的调用
import + 模块 相当于把模块中所有功能都导入进来,然后再调用 模块.方法
form 模块 import 方法 相当于把模块中指定的方法拿过来用
内置模块是Python自带的功能,在使用内置模块相应的功能时,需要【先导入】再【使用】
内置模块是Python自带的功能,在使用内置模块相应的功能时,需要【先导入】再【使用】
一、sys
用于提供对Python解释器相关的操作:
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.maxint 最大的Int值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称 sys.stdin 输入相关 sys.stdout 输出相关 sys.stderror 错误相关
二、os
用于提供系统级别的操作:
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: (\'.\')
os.pardir 获取当前目录的父目录字符串名:(\'..\')
os.makedirs(\'dir1/dir2\') 可生成多层递归目录
os.removedirs(\'dirname1\') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir(\'dirname\') 生成单级目录;相当于shell中mkdir dirname
os.rmdir(\'dirname\') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir(\'dirname\') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","new") 重命名文件/目录
os.stat(\'path/filename\') 获取文件/目录信息
os.sep 操作系统特定的路径分隔符,win下为"\\\\",Linux下为"/"
os.linesep 当前平台使用的行终止符,win下为"\\t\\n",Linux下为"\\n"
os.pathsep 用于分割文件路径的字符串
os.name 字符串指示当前使用平台。win->\'nt\'; Linux->\'posix\'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
三、hashlib
用于加密相关的操作,代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import hashlib # ######## md5 ######## hash = hashlib.md5() # help(hash.update) hash.update(bytes(\'admin\', encoding=\'utf-8\')) print(hash.hexdigest()) print(hash.digest()) ######## sha1 ######## hash = hashlib.sha1() hash.update(bytes(\'admin\', encoding=\'utf-8\')) print(hash.hexdigest()) # ######## sha256 ######## hash = hashlib.sha256() hash.update(bytes(\'admin\', encoding=\'utf-8\')) print(hash.hexdigest()) # ######## sha384 ######## hash = hashlib.sha384() hash.update(bytes(\'admin\', encoding=\'utf-8\')) print(hash.hexdigest()) # ######## sha512 ######## hash = hashlib.sha512() hash.update(bytes(\'admin\', encoding=\'utf-8\')) print(hash.hexdigest())
以上是关于初识正则表达式的主要内容,如果未能解决你的问题,请参考以下文章