分布式深度学习之DC-ASGD
Posted StJay
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式深度学习之DC-ASGD相关的知识,希望对你有一定的参考价值。
本篇笔记是听刘铁岩老师做Distributed Deep Learning:New Driving Force of Artificial Intelligence报告整理而成
深度学习梯度下降公式如下
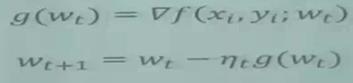
常用的深度学习训练方法为:
Full batch -> SGD -> min-batch SGD
Stochastic Gradient Descent (SGD)
其中:
- full batch是将所有的样本过一遍再更新参数,更新的效率较低。
- SGD每一个样本更新一次参数,更新频率非常快。但是每一个样本对应的目标函数和整个数据集对应的目标函数是有差别的,因为这是一个随机抽样。可以证明,在随机抽样的时候SGD的目标函数对整个神经网络学习的目标函数来说是一个无偏估计,但这个无偏估计可能会有很大的方差,所以在学习的过程中会引入许多因方差导致的噪声,所以学习的收敛率不是很好。
- mini-batch是在这两者之间达到一个平衡,一方面希望比较频繁地更新参数,另一方面希望mini-batch降低单个样本带来的方差。
以上是标准的神经网络的训练方法。
challenges of training deep networks
- Overfitting: Too many parameters to learn from limited number of training examples 当一个网络变深的时候,该网络作为一个函数的容量程指数级增大,即当网络很深的时候,该网络的表达能力非常强。
- Gradient vanishing or exploding

上图是sigmoid导数的图像,该最大值为0.25,因此当级联导数时就会造成梯度消失。




在每一个隐节点做白化,并且是带参数的白化。做白化,让一批样本的均值为0。


The Deeper, The Better ?

训练数据越大,最优层数越深。
大量数据如何训练?
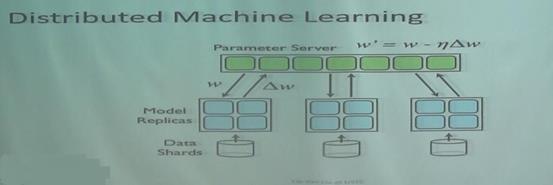


异步,每个机器算完自己的梯度就扔到服务器上,并不管服务器有没有来得及把大家加在一起更新模型,结果推送上去之后就继续往下走了,不去等别的机器,但过了一段时间觉得希望等别的机器的信息的时候,就把当时那个点上服务器上的模型拽下来,更新一下自己的起点,然后再往下走。每一台机器都这样走。
这个策略更新很快,而且不用担心服务器宕掉。但它的缺点是它的过程有点out of control,已经不是任何一种标准的Gradient Descent操作。一般称这种问题为delayed gradients。
Asynchronous data parallelization is fast due to no waiting time, but will suffer from delayed grandients(even if all machines have the same speed), which usually slows down the convergence.
有人证明过,因为有delayed gradients,虽然每一轮迭代的次数很快,但是整体的收敛的轮数变大了很多。
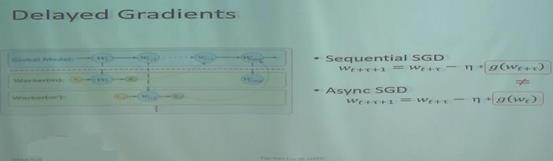
一台机器算得的g(W_(t))准备更新到服务器上的模型时,由于其他机器更新了模型,此时服务器上的W已经是W_(t+tao)。因为有delayed gradients,W_(t+tao)本来需要更新g(W_(t+tao)),而现在更新了g(W_(t))。
于是想到了泰勒展开。用g(W_(t))去表示g(W_(t+tao))。

一次项已经有了。二次项需要去计算。g(W_(t))是梯度,二次项就是梯度的梯度……这样就需要计算hessian matrix,而这个矩阵的计算复杂度远大于一次项梯度的计算。


Is there any efficient way of computing the hissian matrix?

这样就可以把异步的梯度下降做一个改进。

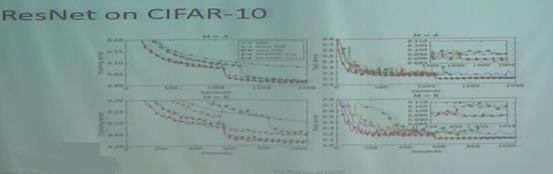
有了这样的思路后就可以做实验对比,通常单机版是收敛到最好的精度,一旦做多机并行,精度总会有所损失。如果做同步的多机并行,因为增大了batchsize所以会有精度损失,如果做异步的多机并行,因为其过程中会有gradient delay所以也会有精度损失。
实验效果:

类似的一些研究

后面总结一下


以上是关于分布式深度学习之DC-ASGD的主要内容,如果未能解决你的问题,请参考以下文章