深入浅出RNN
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入浅出RNN相关的知识,希望对你有一定的参考价值。
参考技术ARNN是深度学习在自然语言处理领域中的元老级神经网络,它奠定了神经网络技术在NLP领域的发展方向,其名声仅此于CNN,虽然近年来它已经鲜少露面,但江湖地位不减,就连当红明星GRU和LSTM都是它的变种。
RNN(Recurrent Neural Networks),循环神经网络,指的是模型循环处理每个input,每次循环迭代称为time(在公式中简称“t”)。Figure 1中,等号右侧部分就是RNN的展开图:input, ( ~ )经过隐藏层循环处理,每个time会生成一个output, ( ~ ),此外还会生成一个hidden state, ,它是隐藏层对input的学习成果,hidden state会和下一个input一起作为参数传入隐藏层(红色箭头)。
我在 深入浅出全连接层 中提过,RNN是由全连接层(Linear layer)组成的,准确地说,RNN中的input layer、hidden layer、output layer,就是Figure 1中的那些箭头,它们都是全连接层。
本文将会以重写RNN的方式来由浅入深剖析RNN,点击【 这里 】可以查看完整源码。
除了使用 Fastai Library 外,还会用它的轻量级NLP数据集: http://files.fast.ai/data/examples/human_numbers.tgz 。数据集是从0到9999的英文数字:“one, two, three, four, five, ......, nine thousand nine hundred ninety eight, nine thousand nine hundred ninety nine”。
我们的任务就是创建一个RNN N-gram语言模型来学习数数,比如说,看到“one, two, three, four, five, ”这10个连续token(","也是一个token),就能预测出第11个token是"six"。关于token、N-gram、语言模型、embedding以及nlp mini-batch等内容,可以回看以前的文章 自己动手开发AI影评写作机器人 ,这里不再赘述。
如Figure 1所示,Model1通过一个for循环来(递归)处理每个input(token),并将hidden state传递到下一个循环,等到N个(x.shape[1])token都学习完之后,用第N个hidden state来生成一个output。这就是RNN根据前面N个token来预测第N+1个token的过程。
之所以RNN可以预测第N+1个token,是因为hidden state包含了前面N个token的信息。 h = h + F.relu(self.input(self.emb(x[:, i]))) ,为RNN预测提供了前文的信息。
Learner是Fastai提供用于模型训练的library,“acc_f”这栏显示的是模型的预测准确率:45.9%。
Model1的hidden state只保留了同一个mini-batch内的token信息,一旦开始学习新的mini-batch,hidden state就会清零: h = torch.zeros(x.shape[0], nh).to(device=x.device) 。
因此,Model3会保留前一个mini-batch训练得到的hidden state,换句话说,此时的hidden state保留了整个dataset的信息。不仅如此,Model3不只是预测第N+1个token,它会预测所有token的下一个token。
Model3实现了RNN的基本功能,它的预测准确率达到72.2%。除此之外,用tanh替代relu,准确率会提升到75.4%,标准RNN的默认激活函数就是tanh。
Model4是Model3的对标模型,用Pytorch官方提供的RNN实现,从训练结果来看,它准确率比Model3要低不少,因此,这里温馨提醒,不要把官方code当作圣旨。实践表明,relu+batchnorm的组合应用到RNN中卓有成效,可惜,它无法作用于nn.RNN。
虽然nn.RNN的表现不如自己手撸的好,但并不是鼓励大家自己造轮子,而且本人也很反对像自己造轮子这种几乎不输出价值的工作方式。事实上,当我们使用2层RNN之后,Model4的表现就优于Model3了。
2层RNN的结构如下图所示,2个隐藏层虽然比1个隐藏层效果更好,但计算量也翻倍了,由于全连接层的参数数量比卷积层的要多得多,深层RNN的训练时间要远远长于相同深度的CNN,因此,RNN层数不宜过多。
RNN虽然通过hidden state来保留各token的信息,但它并不能有效地处理和使用这些信息,它会将所有训练得来的信息都一股脑地塞进hidden state,并用它来影响后续每个token的学习,而且这种影响不管是好是坏都会随着训练的深入,像滚雪球一样有增无减地将越多越多的信息裹胁进来。
显然RNN缺乏对新老信息(hidden state和token)的调控,这样一来,当要学习的token较多时,起始部分的token信息在hidden state中的占比就会越来越小,换句话说,文本起始部分的内容很容易会被忘记。
GPU和LSTM就是专门为了应对长文本训练而设计的,它们为RNN中增加了input gate、output gate、forget gate、update gate等机制,对进出信息进行筛选,丢弃过时的、无用的信息,调控输入信息对模型训练的影响力等。
Model5用GRU替代了RNN后,在相同情况下,模型准确率又有了提升,达到了83.8%。关于GRU的分析留待下一篇博文,这里不作展开。
本文通过重构RNN的方式详解了RNN模型的构成,通过分析它的缺陷,进一步介绍了GRU和LSTM的工作原理。
深入理解RNN与LSTM
文章目录
循环神经网络(Recurrent Neural Network)基础
在深度学习领域,神经网络已经被用于处理各类数据,如CNN在图像领域的应用,全连接神经网络在分类问题的应用等。随着神经网络在各个领域的渗透,传统以统计机器学习为主的NLP问题,也逐渐开始采用深度学习的方法来解决。如由Google Brain提出的Word2Vec模型,便将传统BoW等统计方法的词向量方法,带入到了以深度学习为基础的Distribution Representation的方法中来,真正地将NLP问题带入了深度学习的练兵场。当然,RNN的模型并非局限于NLP领域,而是为了解决一系列序列化数据的建模问题,如视频、语音等,而文本也只是序列化数据的一种典型案例。
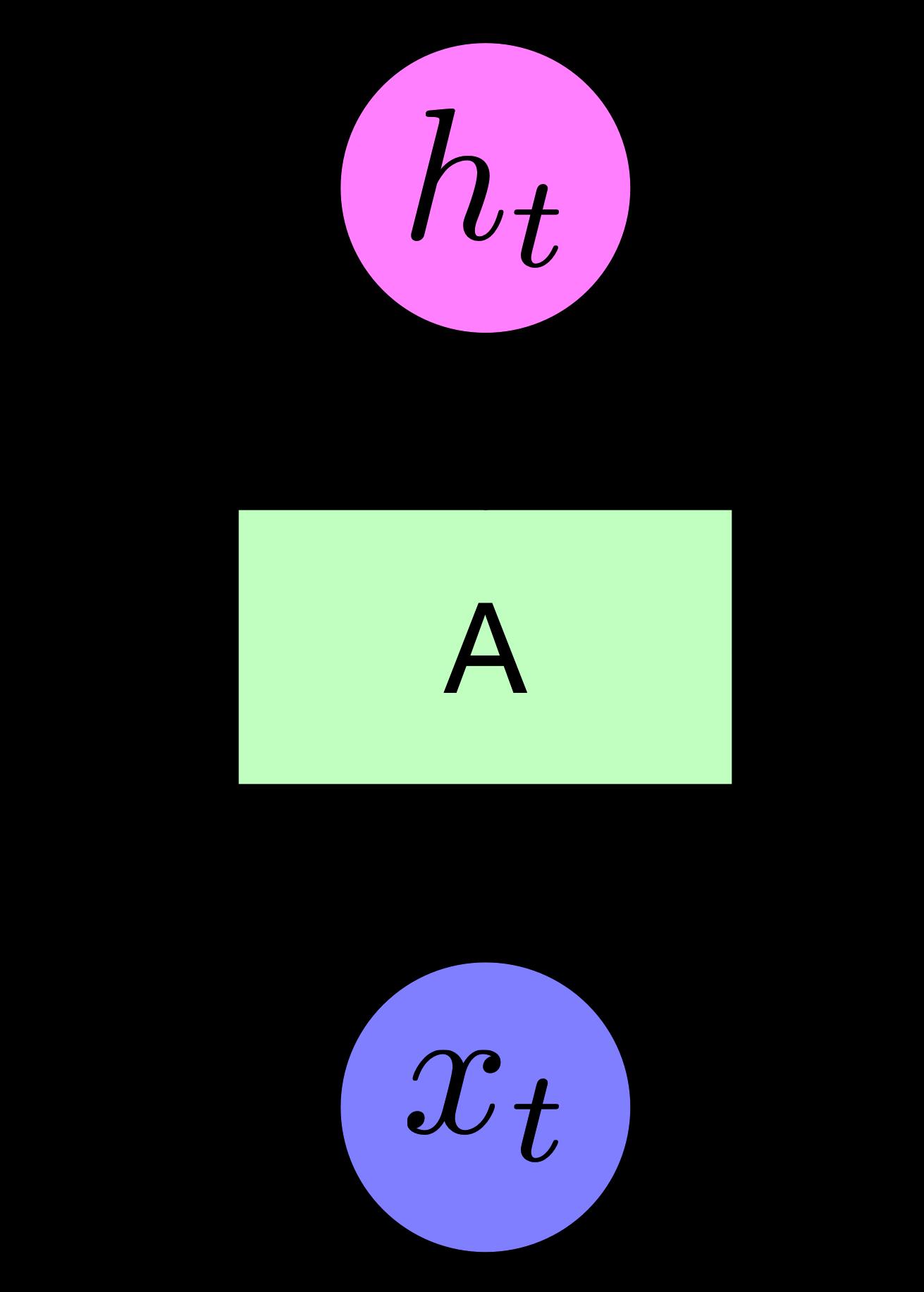
RNN的特征在于,对于每个RNN神经元,其参数始终共享,即对于文本序列,任何一个输入都经过相同的处理,得到一个输出。在传统的全连接神经网络的结构中,神经元之间互不影响,并没有直接联系,神经元与神经元之间相互独立。而在RNN结构中,隐藏层的神经元开始通过一个隐藏状态所相连,通常会被表示为 h t h_t ht。在理解RNN与全连接神经网络时,需要对两者的结构加以区分,通常,FCN会采用水平方式进行可视化理解,即每一层的神经元垂直排列,而不同层之间以水平方式排布。但在RNN的模型图中,隐藏层的不同神经元之间通常水平排列,而隐藏层的不同层之间以垂直方式排列,如图所示,在FCN网络中,各层水平布局,隐藏层各神经元相互独立,在RNN中,各层以垂直布局,而水平方向上布局着各神经元。注意:RNN结构图只是为了使得结构直观易理解,而在水平方向上其实每个A都相同,对于每个时间步其都是采用同一个神经元进行前向传播。

RNN的前向传播
在RNN中,序列数据按照其时间顺序,依次输入到网络中,而时间顺序则表示时间步的概念。在RNN中,隐藏状态极为重要,隐藏状态是连接各隐藏层各神经元的中介值。如上图,在第一层中,在时间步 t t t,RNN隐藏层神经元得到隐藏状态 h t ( 1 ) h_t^(1) ht(1),在时间步 t + 1 t+1 t+1,则接受来自上一个时间步的隐藏层输出 h t ( 1 ) h_t^(1) ht(1),得到新的隐藏状态 h t + 1 ( 1 ) h_t+1^(1) ht+1(1)。而从垂直方向上看,各层之间,也通过隐藏状态所连接,对于 L 1 L_1 L1到 L 2 L_2 L2, L 2 L_2 L2在水平的时间轴上,各神经元通过隐藏状态 h t ( 2 ) h_t^(2) ht(2)连接,而层间还将接受前一层的 h t ( 1 ) h_t^(1) ht(1)的值来作为 x t x_t xt的值,从而获得到该层新的隐藏状态。因此,RNN是一个在水平方向和垂直方向上,均可扩展的结构(水平方向上只是人为添加的易于理解的状态,在工程实践中不存在水平方向的设置)。
根据RNN的定义,可以简单地给出RNN的前向传播过程:
h t = g ( W x t + V h t − 1 + b ) h_t=g\\left(Wx_t+Vh_t-1+b\\right) ht=g(Wxt+Vht−1+b)
如上式,对于某一层, W 、 V 、 b W、V、b W、V、b均为模型需要学习的参数,通过上图RNN结构图的对应,则应为 L 1 L_1 L1层水平方向所有神经元的参数,**同一层的RNN单元参数相同,即参数共享。**若考虑多层RNN,则可将上式改为:
h t [ i ] = g ( W [ i ] h t [ i − 1 ] + V [ i − 1 ] h t − 1 [ i ] + b [ i ] ) h_t^[i]=g\\left(W^[i]h_t^[i-1]+V^[i-1]h_t-1^[i]+b^[i]\\right) ht[i]=g(W[i]ht[i−1]+V[i−1]ht−1[i]+b[i])
为了简化研究,下文统一对单层RNN进行讨论。
值得注意的是,单层RNN前向传播可做如下变换:
W x t + V h t = [ W V ] × [ x t h t − 1 ] Wx_t+Vh_t=\\left[\\beginarrayccW&V\\endarray\\right]\\times\\left[\\beginarraycx_t\\\\h_t-1\\endarray\\right] Wxt+Vht=[WV]×[xtht−1]
为此,我们不妨将参数进行统一表示: W = [ W ; V ] W=\\left[W;V\\right] W=[W;V],其中 [ ⋅ ; ⋅ ] [\\cdot;\\cdot] [⋅;⋅]表示拼接操作,则前向传播变为 h t = g ( W [ h t − 1 ; x t ] ⊤ + b ) h_t=g\\left(W[h_t-1;x_t]^\\top+b\\right) ht=g(W[ht−1;xt]⊤+b)。
再获得隐藏状态后,若需要获得每一个时间步的输出,则需要进一步进行线性变换:
o t = V h t + b o , y t = g ( o t ) o_t=Vh_t+b_o, \\;\\;y_t=g(o_t) ot=Vht+bo,yt=g(ot),其中 V 、 b V、b V、b为参数, g ( ⋅ ) g(\\cdot) g(⋅)为激活函数,如softmax。
针对单层RNN,可采用上述结构进行描述。
RNN的反向传播
为简化分析,选用RNN的最后时间步的隐藏状态(无输出层)直接作为输出层,即 o u t p u t = h t = g ( W [ h t − 1 ; x t ] ⊤ + b ) output=h_t=g\\left(W\\left[h_t-1;x_t\\right]^\\top+b\\right) output=ht=g(W[ht−1;xt]⊤+b),若为分类问题,则 g ( ⋅ ) g(\\cdot) g(⋅)通常为Softmax。定义问题的损失函数为 J ( θ ) = L o s s ( o u t p u t , y ∣ θ ) J(\\theta)=Loss\\left(output,y|\\theta\\right) J(θ)=Loss(output,y∣θ),则在进行反向传播时,需要计算 W 、 b W、b W、b的梯度,可进行如下推导:
Δ W = ∂ J ( θ ) ∂ W = ∂ ∂ W L o s s ( o u t p u t , y ) = L o s s ( o u t p u t , y ) ′ ∂ g ( W [ h t − 1 ; x ] ⊤ + b ) ∂ W = L o s s ( o u t p u t , y ) ′ g ( ⋅ ) ′ [ h t − 1 ; x t ] \\Delta W=\\frac\\partial J(\\theta)\\partial W=\\frac\\partial\\partial W Loss(output,y)=Loss(output,y)'\\frac\\partial g\\left(W\\left[h_t-1;x\\right]^\\top+b\\right)\\partial W=Loss(output,y)'g(\\cdot)'[h_t-1;x_t] ΔW=以上是关于深入浅出RNN的主要内容,如果未能解决你的问题,请参考以下文章