Spark弹性分布式数据集RDD
Posted 异想天开
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark弹性分布式数据集RDD相关的知识,希望对你有一定的参考价值。
RDD(Resilient Distributed Dataset)是Spark的最基本抽象,是对分布式内存的抽象使用,实现了以操作本地集合的方式来操作分布式数据集的抽象实现。RDD是Spark最核心的东西,它表示已被分区,不可变的并能够被并行操作的数据集合,不同的数据集格式对应不同的RDD实现。RDD必须是可序列化的。RDD可以cache到内存中,每次对RDD数据集的操作之后的结果,都可以存放到内存中,下一个操作可以直接从内存中输入,省去了MapReduce大量的磁盘IO操作。这对于迭代运算比较常见的机器学习算法, 交互式数据挖掘来说,效率提升比较大。
RDD的理解可以简化为:
- 数据集:故名思议RDD是数据集合的抽象,从外部来看,RDD的确可以被看待成经过封装,带扩展特性(如容错性)的数据集合;
- 分布式:数据的计算并非只局限于单个节点,而是多个节点之间协同计算是到;
- 弹性:在计算处理过程中,机器的内存不够时,它会和硬盘进行数据交换,某种程度上会减低性能,但是可以确保计算得以继续进行
可以把RDD理解为Scala集合的分布式版本,Scala集合位于单个JVM,而RDD通过分区分布在多个JVM,这些JVM可能跨越不同的物理机器节点。下图是RDD的一个示意图:

一、编程模型
在Spark中,RDD被表示为对象,通过这些对象上的方法(或函数)调用转换。
定义RDD之后,程序员就可以在动作(注:即action操作)中使用RDD了。动作是向应用程序返回值,或向存储系统导出数据的那些操作,例如,count(返回RDD中的元素个数),collect(返回元素本身),save(将RDD输出到存储系统)。在Spark中,只有在动作第一次使用RDD时,才会计算RDD(即延迟计算)。这样在构建RDD的时候,运行时通过管道的方式传输多个转换。
程序员还可以从两个方面控制RDD,即缓存和分区。用户可以请求将RDD缓存,这样运行时将已经计算好的RDD分区存储起来,以加速后期的重用。缓存的RDD一般存储在内存中,但如果内存不够,可以写到磁盘上。
另一方面,RDD还允许用户根据关键字(key)指定分区顺序,这是一个可选的功能。目前支持哈希分区和范围分区。例如,应用程序请求将两个RDD按照同样的哈希分区方式进行分区(将同一机器上具有相同关键字的记录放在一个分区),以加速它们之间的join操作。在Pregel和HaLoop中,多次迭代之间采用一致性的分区置换策略进行优化,我们同样也允许用户指定这种优化。
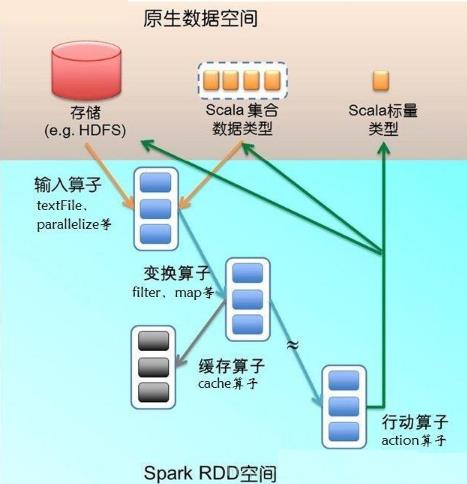
对于RDD,有两种类型的动作,一种是Transformation,一种是Action。它们本质区别是:
- Transformation返回值还是一个RDD。它使用了链式调用的设计模式,对一个RDD进行计算后,变换成另外一个RDD,然后这个RDD又可以进行另外一次转换。这个过程是分布式的
- Action返回值不是一个RDD。它要么是一个Scala的普通集合,要么是一个值,要么是空,最终或返回到Driver程序,或把RDD写入到文件系统中
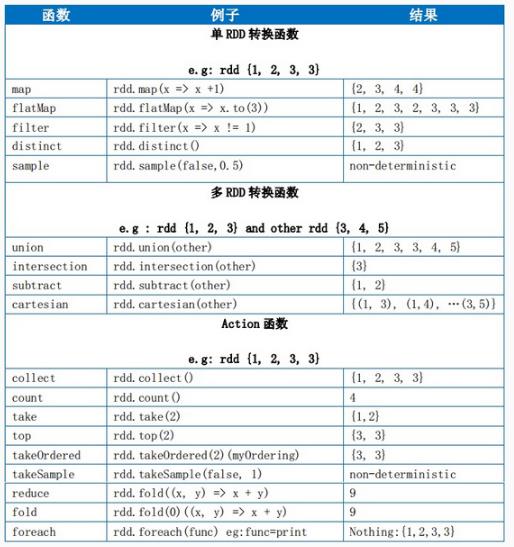
Transformations转换操作,返回值还是一个 RDD,如 map、 filter、 union
Actions行动操作,返回结果或把RDD持久化起来,如 count、 collect、 save
A=>B表示以=>操作符左边的部分作为输入,对其执行一个函数,并以=>操作符右边代码的执行结果作为输出

参见:http://blog.jasonding.top/2015/07/08/Spark/【Spark】弹性分布式数据集RDD
http://www.jianshu.com/p/0b75ddd66999和https://www.zybuluo.com/BrandonLin/note/448121
以上是关于Spark弹性分布式数据集RDD的主要内容,如果未能解决你的问题,请参考以下文章