掀开断点续传那一层面纱(下载篇)
Posted 那一叶随风
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了掀开断点续传那一层面纱(下载篇)相关的知识,希望对你有一定的参考价值。
1、简介
这一篇文章主要介绍的是http协议下载时的断点续传,详细到各个步骤。主要步骤有:DNS查找、TCP三次握手、http请求发送、TCP协议数据传输、暂停后的状态、继续下载、TCP三次握手、http请求发送、数据传输、。。。、下载成功发送http响应信息、TCP四次握手断开连接。
2、原理知识
2.1、问答问答
问:什么是断点续传?断点续传的原理是什么?
答:断点续传就是信号中断后(掉线或关机等),下次能够从上次的地方接着传送(一般指下载或上传),不支持断点续传就意味着下次下载或上传必须从零开始。http协议中的断点续传是基于Http头Range以及Content-Range。HTTP头中一般断点下载时才用到Range和Content-Range实体头,Range用户请求头中,指定第一个字节的位置和最后一个字节的位置,如( Range:200-300或者Range:200- );Content-Range用于响应头。通俗的来讲就是文件大小为10,这次下载了3,被中断了,下次继续下载时则将指针移到3位置,从3开始下载,最终将整个文件下载下来。
2.2、简单http下载文件
请求下载整个文件:
GET /test.rar HTTP/1.1
Connection: close
Host: 192.168.95.11
Range: bytes=0-801 //一般请求下载整个文件是bytes=0- 或不用这个头
一般正常回应 :
HTTP/1.1 200 OK
Content-Length: 801
Content-Type: application/octet-stream
Content-Range: bytes 0-800/801 //801:文件总大小
2.3、重要的几个头
响应头:
Content-type:Content-type 告诉浏览器文件的MIME 类型,这是非常重要的一个响应头了,MIME种类繁多。很可能会在程序中漏掉一些MIME类型,表示全部为 content-type:application/octet-stream(字节流)
Content-Disposition:是 MIME 协议的扩展,MIME 协议指示 MIME 用户代理如何显示附加的文件。当 Internet Explorer 接收到头时,它会激活文件下载对话框,它的文件名框自动填充了头中指定的文件名。 嗯,就是这个头哟,激活弹出提示下载框,一般这样写content-disposition:attachment; filename=name
Content-Range:字段说明服务器返回了文件的某个范围及文件的总长度。这时Content-Length字段就不是整个文件的大小了,而是对应文件这个范围的字节数,这一点一定要注意。一般格式,Content-Range: bytes 500-999/1000
响应头:
Range:可以请求实体的一个或者多个子范围。
例如:
表示头500个字节:bytes=0-499
表示第二个500字节:bytes=500-999
表示最后500个字节:bytes=-500
表示500字节以后的范围:bytes=500- 【下载断点续传(一般range格式为500-)】
第一个和最后一个字节:bytes=0-0,-1
同时指定几个范围:bytes=500-600,601-999
但是服务器可以忽略此请求头,如果无条件GET包含Range请求头,响应会以状态码206(PartialContent)返回而不是以200(OK)。【206表示服务器已经完成get的部分请求,即表示断点续传】
3、支持断点续传的文件下载类
类中含有注释,这里不再多解释了
FileDownload.class.php
1 <?PHP 2 #文件下载(支持断点续传) 3 class FileDownload 4 { 5 #下载速度 6 private $_speed = 512; 7 8 /** 9 * @desc 下载文件 10 * 11 * @param $file string 下载的文件路径 12 * @param $name string 保存文件时的文件名,不写则最终下载文件默认为原文件名 13 * @param $reload bool 是否使用断点续传方式下载 14 */ 15 public function download($file, $name=\'\', $reload=false) 16 { 17 if(file_exists($file)) #判断文件是否存在 18 { 19 if($name == \'\') #判断命名参数是否存在 20 { 21 $name = basename($file); #采用原文件名进行存储 22 } 23 $fHandle = fopen($file, \'rb\'); #只读方式打开;为移植性考虑,使用b标记打开文件(不同系统有不同换行符) 24 $fileSize = filesize($file); #文件大小 25 $ranges = $this->getRange($fileSize); #断点续传时,先查看下载的区间范围 26 header(\'cache-control:public\'); #可以被任何缓存所缓存 27 header(\'content-type:application/octet-stream\'); #告诉浏览器响应的对象的类型(字节流、浏览器默认使用下载方式处理) 28 header(\'content-disposition:attachment; filename=\'.$name); #不打开此文件,刺激浏览器弹出下载窗口 29 #判断是否使用续传方式进行下载 30 #且请求头ranges不能为null(为null表示第一次请求下载) 31 if($reload && $ranges!=null) 32 { 33 header(\'HTTP/1.1 206 Partial Content\'); #发送自定义报文 206续传状态码 34 header(\'Accept-Ranges:bytes\'); #表明服务器支持Range请求,所支持的单位是字节 35 # 剩余长度 36 header(sprintf(\'content-length:%u\',$ranges[\'end\']-$ranges[\'start\'])); 37 # range信息 38 header(sprintf(\'content-range:bytes %s-%s/%s\', $ranges[\'start\'], $ranges[\'end\'], $fileSize)); 39 # fHandle指针跳到断点位置 40 fseek($fHandle, sprintf(\'%u\', $ranges[\'start\'])); 41 } 42 else 43 { 44 header(\'HTTP/1.1 200 OK\'); 45 header(\'content-length:\'.$fileSize); 46 } 47 while(!feof($fHandle)) 48 { 49 echo fread($fHandle, round($this->_speed*1024,0)); 50 ob_flush(); #把数据从PHP的缓冲中释放出来 51 //sleep(2); // 用于测试,减慢下载速度 52 } 53 ($fHandle!=null) && fclose($fHandle); 54 } 55 else 56 { 57 #没文件 58 header("HTTP/1.1 404 Not Found"); 59 return false; 60 } 61 } 62 63 /** 64 * @desc 获取请求头部range信息 65 * 66 * @param $fileSize int 该文件的大小 67 * 68 * @return array|null 返回range信息或者null 69 */ 70 public function getRange($fileSize) 71 { 72 if(isset($_SERVER[\'HTTP_RANGE\']) && !empty($_SERVER[\'HTTP_RANGE\'])) 73 { 74 #请求头部range信息 Range: bytes=41078-\\r\\n 75 $range = $_SERVER[\'HTTP_RANGE\']; 76 $range = preg_replace(\'/[\\s|,].*/\', \'\', $range); 77 $range = explode(\'-\', substr($range, 6)); #只需将41078-进行分割变成数组 78 #断点续传头部range信息都是为 4444- 这种形式 ,因此切割后形成的数组就只有两个元素 79 $range = array_combine(array(\'start\',\'end\'), $range); 80 if(empty($range[\'start\'])) 81 { 82 $range[\'start\'] = 0; 83 } 84 if(empty($range[\'end\'])) 85 { 86 $range[\'end\'] = $fileSize; 87 } 88 return $range; 89 } 90 return null; #第一次请求没有range信息 91 } 92 93 /** 94 * @desc 设置文件下载速度 95 * 96 * @param $speed int 下载速度 97 */ 98 public function setSpeed($speed) 99 { 100 if(is_numeric($speed) && $speed>16 && $speed<4096) 101 { 102 $this->_speed = $speed; 103 } 104 } 105 106 } 107 108 ?>
4、测试并分析其中的步骤
4.1、前提准备工作
- 将上面类文件中第六行下载速度更改为10
- 去掉上面类文件第51行的注释,使它有延迟
- 使用火狐浏览器进行下载测试
- 使用Wireshark抓包工具进行抓包分析
- test.php文件
1 <?php 2 include \'FileDownload.class.php\'; 3 $a=new FileDownload(); 4 #不支持断点续传 5 #$b=$a->download(\'./aa.txt\',\'bb.txt\'); 6 #支持断点续传 7 #$b=$a->download(\'./aa.txt\',\'bb.txt\',1); 8 ?>
开始测试:
4.2、测试支持断点续传下载
执行步骤:
1、打开抓包工具进行监控
2、用火狐浏览器进行访问,Enter下载
3、确认下载
4、中途暂停两次,最后下载成功
成功下载!
分析抓包:
1、首先Enter,第一步当然是进行DNS查找啦。这里就不展开讲了,可以参考这里的内容http://www.cnblogs.com/phpstudy2015-6/p/6810130.html#_label18
2、拿到域名对应的IP后,浏览器向服务器80端口发起TCP的连接请求,请看下面的抓包图-1,一到三行尾TCP连接,即TCP三次握手。具体可以参考我写的这篇文章http://www.cnblogs.com/phpstudy2015-6/p/6810130.html#_label2
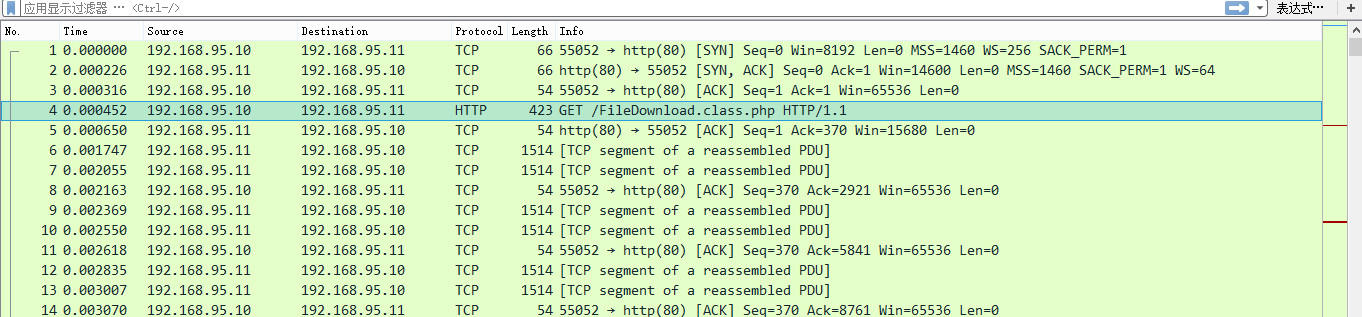
抓包图-1
3、TCP连接后,浏览器发起一个HTTP请求,即抓包图-1中的第4行。下图是该http GET请求。第一次请求不存在信息头range
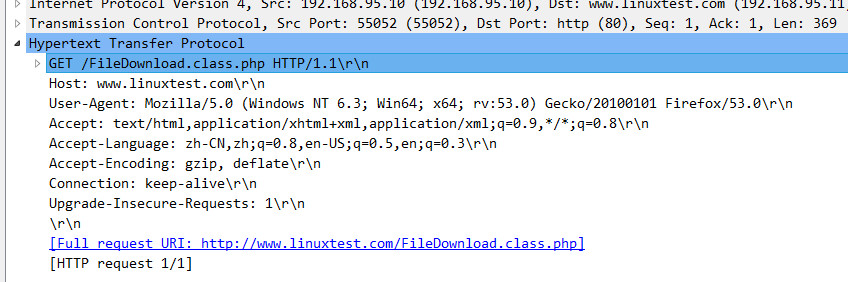
http请求图
4、http请求后,开始TCP数据传输,请看上面的抓包图-1,第5行后就开始有顺序的进行tcp层数据传输(192.168.95.11Web主机连续发送两次数据给192.168.95.10浏览器;浏览器接收并回应一次Web主机,告诉Web主机已经收到数据并且完整无误,可以继续传输!)
5、此时暂停下载,。请看下面的抓包图-2,第72行的时候,暂停下载(即断开与Web服务器的连接)。因为这是突然断开的,Web主机并不知道浏览器已经断开了,所以还一直发送数据给浏览器(73~76),但是Web服务器没有收到浏览器的回应,最后它也不发数据,大家分手了。
这个请求最后是没有收到Web服务器的http响应信息的。按照原本的请求是下载完整个文件后,Web才发送http响应消息的,但是浏览器突然单方面断开,此时数据都没传送完,怎么会给你相应消息呢!

抓包图-2
6、继续下载。请看下图的抓包图-3。
点击继续下载时,即再从新发送一个http请求给服务器。
第77~79行是TCP连接(三次握手)
第80行为发送http请求信息
请看下面的http请求信息,这一次含有请求头Range,这是Web重要机制。在暂停下载的时候,浏览器会记住已经已经接受的字节数,待继续下载的时候,在构建http请求信息的时候会增加这一个重要的请求头信息。这也是支持断点续传的一个前提条件。
浏览器携带Range头信息请求Web服务器,此时我们需要在代码层对这个重要信息进行处理。即取出该字节数出,然后在文件中定位指针,然后读文件开始续传。【这是断点续传应用中的逻辑关键】
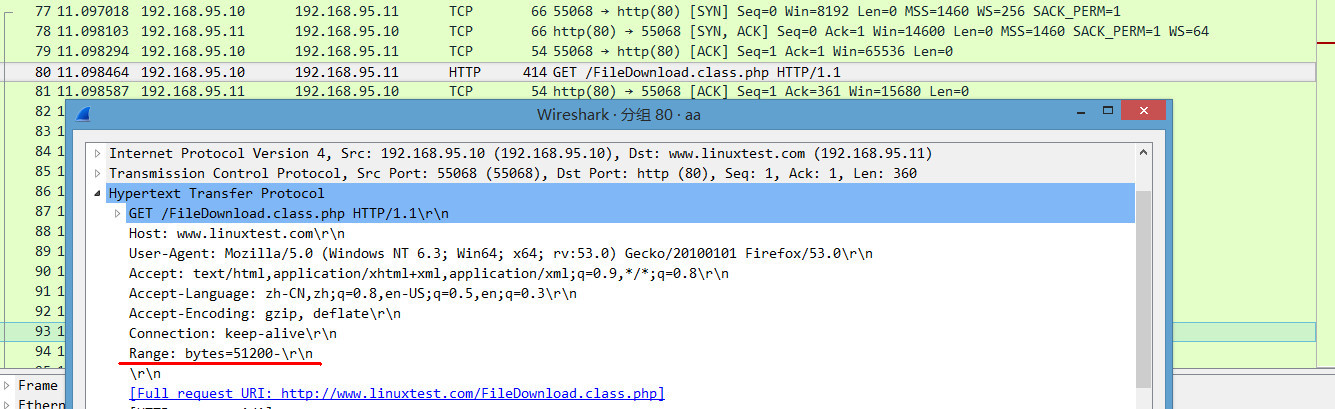
抓包图-3
7、重复暂停一次,在继续下载,观察对比。暂停两次可以从抓包图-1中最右边可以看到两个红色的横线。
8、最后下载成功啦,此时Web服务器会发送http响应信息给浏览器。
第350行尾响应行
看下面的http响应图,响应状态码为206
用红色线标记的是我们代码中自定义的响应头

抓包图-4
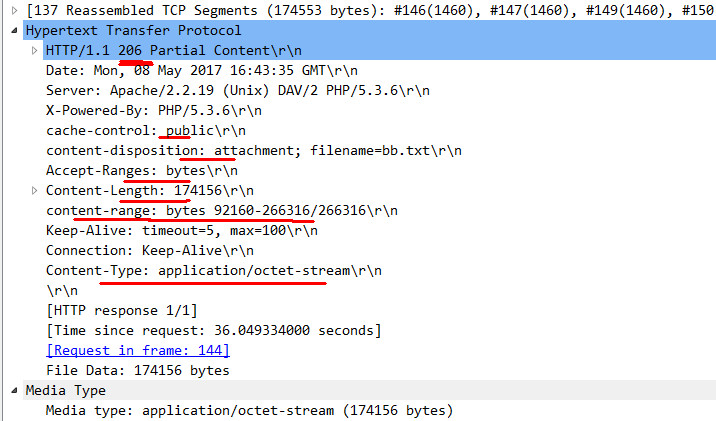
http响应图
9、TCP四次握手,端断开连接。看上面的抓包图-4
第352~354是TCP断开连接。四次握手为什么是只有三次通讯呢?
TCP断开具体也可以参考我之前写的文章。
第一次,浏览器发送FIN包(表示要断开)、ACK(确认序列号)。seq=361
第二、三次,Web服务器接受到浏览器发来的包,并回复FIN包(我也要要断开)、ACK(确认序列号)。seq=174554、ack=362 【Web将浏览器发来的seq=361+1=362,转变成ack=362发给浏览器,表示我已经知道了】【此时浏览器并一起发送seq=174554,告诉浏览器说我要关闭连接啦】
第四次,浏览器回复Web服务器,ack=174555 【浏览器将Web服务器发来的seq=174554+1,转变换成ack=174555发给Web主机,表示我已经知道了】
TCP一直说是四次握手断开,我认为这应该是逻辑上的四次握手,从抓包上来看的话,第二、三次合并为一次通讯了。
4.3、测试不支持断点续传下载
执行步骤:
1、打开抓包工具进行监控
2、用火狐浏览器进行访问,Enter下载
3、暂停下载
4、继续下载。突然不行了,下载失败!为什么会这样呢!下面我们来分析分析
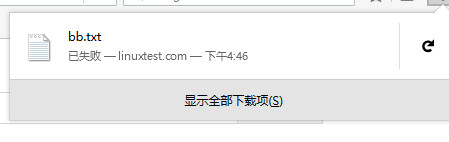
抓包分析:
1、TCP连接、http get请求无异常

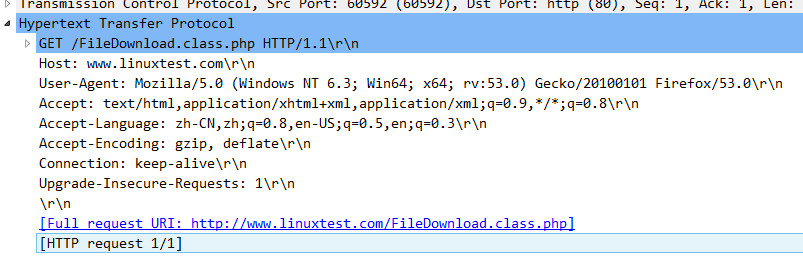
2、从抓包分析在断开前都无任何异常
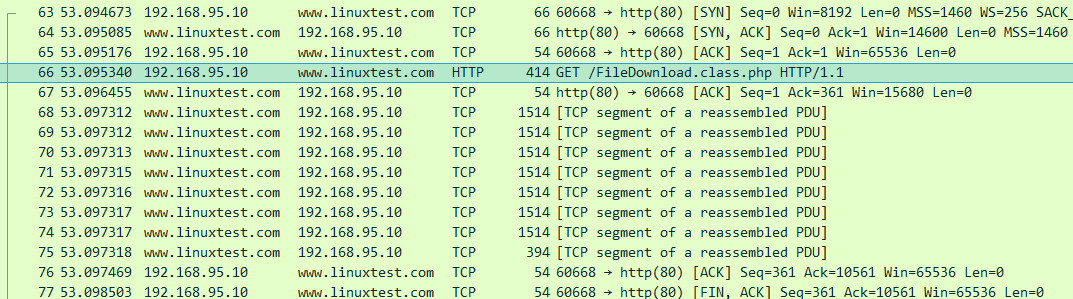
3、继续下载抓包分析
TCP连接正常
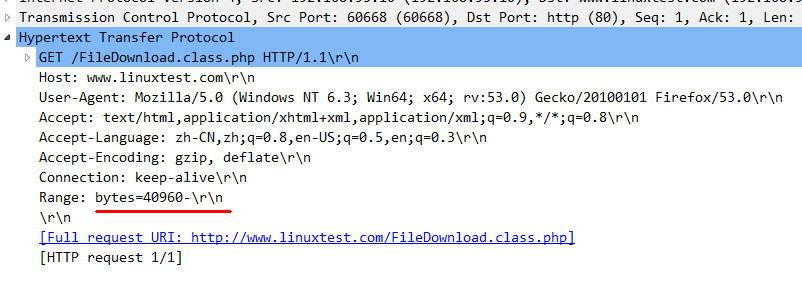
http请求信息,看上去是正常的,但是相对于我们所写的程序就不对劲了。请求信息中含有Range请求头,他需要的是数据该该Range范围内的,而我们程序定义的是非断点续传,即每次访问都是重写下载,因此Web传输的数据对不上浏览器之前的数据,最终出错啦!
5、总结
从学习OSI网络模型、TCP/IP网络模型到深入了解TCP传输、http协议、DNS查找、以及http URL访问具体细节步骤,最后到这个HTTP协议应用--断点续传,收获还是挺丰厚的。 以上是自己对断点续传的理解,以及做的相应测试,若有不对的地方,希望大家指出,好让我改正改正。
(以上是自己的一些见解,若有不足或者错误的地方请各位指出)
作者:那一叶随风 http://www.cnblogs.com/phpstudy2015-6/
原文地址:http://www.cnblogs.com/phpstudy2015-6/p/6821478.html
声明:本博客文章为原创,只代表本人在工作学习中某一时间内总结的观点或结论。转载时请在文章页面明显位置给出原文链接
以上是关于掀开断点续传那一层面纱(下载篇)的主要内容,如果未能解决你的问题,请参考以下文章