【转】文件下载之断点续传(客户端与服务端的实现)
前面讲了文件的上传,今天来聊聊文件的下载。
老规矩,还是从最简单粗暴的开始。那么多简单算简单?多粗暴算粗暴?我告诉你可以不写一句代码,你信吗?直接把一个文件往IIS服务器上一扔,就支持下载。还TM么可以断点续传(IIS服务端默认支持)。
在贴代码之前先来了解下什么是断点续传(这里说的是下载断点续传)?怎么实现的断点续传?
断点续传就是下载了一半断网或者暂停了,然后可以接着下载。不用从头开始下载。
很神奇吗,其实简单得很,我们想想也是可以想到的。
首先客户端向服务端发送一个请求(下载文件)。然后服务端响应请求,信息包含文件总大小、文件流开始和结束位置、内容大小等。那具体是怎么实现的呢?
HTTP/1.1有个头属性Range。比如你发送请求的时候带上Range:0-199,等于你是请求0到199之间的数据。然后服务器响应请求Content-Range: bytes 0-199/250 ,表示你获取了0到199之间的数据,总大小是250。(也就是告诉你还有数据没有下载完)。
我们来画个图吧。
是不是很简单?这么神奇的东西也就是个“约定”而已,也就是所谓的HTTP协议。
然而,协议这东西你遵守它就存在,不遵守它就不存在。就像民国时期的钱大家都信它,它就有用。如果大部分人不信它,也就没卵用了。
这个断点续传也是这样。你服务端遵守就支持,不遵守也就不支持断点续传。所以我们写下载工具的时候需要判断响应报文里有没有Content-Range,来确定是否支持断点续传。
废话够多了,下面撸起袖子开干。
文件下载-服务端
使用A标签提供文件下载
利用a标签来下载文件,也就是我们前面说的不写代码就可以实现下载。直接把文件往iis服务器上一扔,然后把链接贴到a标签上,完事。
<a href="/新建文件夹2.rar">下载</a>简单、粗暴不用说了。如真得这么好那大家也不会费力去写其他下载逻辑了。这里有个致命的缺点。这种方式提供的下载不够安全。谁都可以下载,没有权限控制,说不定还会被人文件扫描(好像csdn就出过这档子事)。
使用RESPONSE.TRANSMITFILE提供文件下载
上面说直接a标签提供下载不够安全。那我们怎么提供相对安全的下载呢。asp.net默认App_Data文件夹是不能被直接访问的,那我们把下载文件放这里面。然后下载的时候我们读取文件在返回到响应流。
//文件下载
public void FileDownload5()
{
//前面可以做用户登录验证、用户权限验证等。
string filename = "大数据.rar"; //客户端保存的文件名
string filePath = Server.MapPath("/App_Data/大数据.rar");//要被下载的文件路径
Response.ContentType = "application/octet-stream"; //二进制流
Response.AddHeader("Content-Disposition", "attachment;filename=" + filename);
Response.TransmitFile(filePath); //将指定文件写入 HTTP 响应输出流
}
其他方式文件下载
在网上搜索C#文件下载一般都会搜到所谓的“四种方式”。其实那些代码并不能拿来直接使用,有坑的。
第一种:(Response.BinaryWrite)
public void FileDownload2()
{
string fileName = "新建文件夹2.rar";//客户端保存的文件名
string filePath = Server.MapPath("/App_Data/新建文件夹2.rar");//要被下载的文件路径
Response.ContentType = "application/octet-stream";//二进制流
//通知浏览器下载文件而不是打开
Response.AddHeader("Content-Disposition", "attachment; filename=" + HttpUtility.UrlEncode(fileName, System.Text.Encoding.UTF8));
//以字符流的形式下载文件
using (FileStream fs = new FileStream(filePath, FileMode.Open, FileAccess.Read))
{
Response.AddHeader("Content-Length", fs.Length.ToString());
//这里容易内存溢出
//理论上数组最大长度 int.MaxValue 2147483647
//(实际分不到这么多,不同的程序能分到值也不同,本人机器,winfrom( 2147483591 相差56)、iis(也差不多2G)、iis Express(只有100多MB))
byte[] bytes = new byte[(int)fs.Length];
fs.Read(bytes, 0, bytes.Length);
Response.BinaryWrite(bytes);
}
Response.Flush();
Response.End();
}首先数组最大长度为int.MaxValue,然后正常程序是不会分这么大内存,很容易搞挂服务器。(也就是可以下载的文件,极限值最多也就2G不到。)【不推荐】
第二种:(Response.WriteFile)
public void FileDownload3()
{
string fileName = "新建文件夹2.rar";//客户端保存的文件名
string filePath = Server.MapPath("/App_Data/新建文件夹2.rar");//要被下载的文件路径
FileInfo fileInfo = new FileInfo(filePath);
Response.Clear();
Response.ClearContent();
Response.ClearHeaders();
Response.AddHeader("Content-Disposition", "attachment;filename=\\"" + HttpUtility.UrlEncode(fileName, System.Text.Encoding.UTF8) + "\\"");
Response.AddHeader("Content-Length", fileInfo.Length.ToString());//文件大小
Response.AddHeader("Content-Transfer-Encoding", "binary");
Response.ContentType = "application/octet-stream";
Response.WriteFile(fileInfo.FullName);//大小参数必须介于零和最大的 Int32 值之间(也就是最大2G,不过这个操作非常耗内存)
//这里容易内存溢出
Response.Flush();
Response.End();
}问题和第一种类似,也是不能下载大于2G的文件。然后下载差不多2G文件时,机器也是处在被挂的边缘,相当恐怖。【不推荐】
第三种:(Response.OutputStream.Write)
public void FileDownload4()
{
string fileName = "大数据.rar";//客户端保存的文件名
string filePath = Server.MapPath("/App_Data/大数据.rar");//要被下载的文件路径
if (System.IO.File.Exists(filePath))
{
const long ChunkSize = 102400; //100K 每次读取文件,只读取100K,这样可以缓解服务器的压力
byte[] buffer = new byte[ChunkSize];
Response.Clear();
using (FileStream fileStream = System.IO.File.OpenRead(filePath))
{
long fileSize = fileStream.Length; //文件大小
Response.ContentType = "application/octet-stream"; //二进制流
Response.AddHeader("Content-Disposition", "attachment; filename=" + HttpUtility.UrlEncode(fileName, System.Text.Encoding.UTF8));
Response.AddHeader("Content-Length", fileStream.Length.ToString());//文件总大小
while (fileSize > 0 && Response.IsClientConnected)//判断客户端是否还连接了服务器
{
//实际读取的大小
int readSize = fileStream.Read(buffer, 0, Convert.ToInt32(ChunkSize));
Response.OutputStream.Write(buffer, 0, readSize);
Response.Flush();//如果客户端 暂停下载时,这里会阻塞。
fileSize = fileSize - readSize;//文件剩余大小
}
}
Response.Close();
}
}这里明显看到了是在循环读取输出,比较机智。下载大文件时没有压力。【推荐】
第四种:(Response.TransmitFile)
也就上开始举例说的那种,下载大文件也没有压力。【推荐】
public void FileDownload5()
{
//前面可以做用户登录验证、用户权限验证等。
string filename = "大数据.rar"; //客户端保存的文件名
string filePath = Server.MapPath("/App_Data/大数据.rar");//要被下载的文件路径
Response.ContentType = "application/octet-stream"; //二进制流
Response.AddHeader("Content-Disposition", "attachment;filename=" + filename);
Response.TransmitFile(filePath); //将指定文件写入 HTTP 响应输出流
}文件下载-客户端
上面实现了文件下载的服务端实现,接下来我们实现文件下载的客户端实现。客户端的下载可以直接是浏览器提供的下载,也可以是迅雷或者我们自己写的下载程序。这里为了更好的分析,我们来用winfrom程序自己写个下载客户端。
直接下载
private async void button1_ClickAsync(object sender, EventArgs e)
{
using (HttpClient http = new HttpClient())
{
var httpResponseMessage = await http.GetAsync("http://localhost:813/新建文件夹2.rar");//发送请求 (链接是a标签提供的)
var contentLength = httpResponseMessage.Content.Headers.ContentLength;//读取文件大小
using (var stream = await httpResponseMessage.Content.ReadAsStreamAsync())//读取文件流
{
var readLength = 1024000;//1000K 每次读取大小
byte[] bytes = new byte[readLength];
int writeLength;
while ((writeLength = stream.Read(bytes, 0, readLength)) > 0)//分块读取文件流
{
using (FileStream fs = new FileStream(Application.StartupPath + "/temp.rar", FileMode.Append, FileAccess.Write))//使用追加方式打开一个文件流
{
fs.Write(bytes, 0, writeLength);//追加写入文件
contentLength -= writeLength;
if (contentLength == 0)//如果写入完成 给出提示
MessageBox.Show("下载完成");
}
}
}
}
}看着这么漂亮的代码,好像没问题。可现实往往事与愿违。
我们看到了一个异常“System.Net.Http.HttpRequestException:“不能向缓冲区写入比所配置最大缓冲区大小 2147483647 更多的字节。”,什么鬼,又是2147483647这个数字。因为我们下载的文件大小超过了2G,无法缓冲下载。
可是“缓冲下载”下又是什么鬼。我也不知道。那我们试试可以关掉这个东东呢?答案是肯定的。
var httpResponseMessage = await http.GetAsync("http://localhost:813/新建文件夹2.rar");//发送请求改成下面就可以了
var httpResponseMessage = await http.GetAsync("http://localhost:813/新建文件夹2.rar",HttpCompletionOption.ResponseHeadersRead);//响应一可用且标题可读时即应完成的操作。 (尚未读取的内容。)
我们看到枚举HttpCompletionOption的两个值。一个是响应读取内容,一个是响应读取标题(也就是Headers里的内容)。
异步下载
我们发现在下载大文件的时候会造成界面假死。这是UI单线程程序的通病。当然,这么差的用户体验是我们不能容忍的。下面我们为下载开一个线程,避免造成UI线程的阻塞。
/// <summary>
/// 异步下载
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private async void button2_ClickAsync(object sender, EventArgs e)
{
//开启一个异步线程
await Task.Run(async () =>
{
//异步操作UI元素
label1.Invoke((Action)(() =>
{
label1.Text = "准备下载...";
}));
long downloadSize = 0;//已经下载大小
long downloadSpeed = 0;//下载速度
using (HttpClient http = new HttpClient())
{
var httpResponseMessage = await http.GetAsync("http://localhost:813/新建文件夹2.rar", HttpCompletionOption.ResponseHeadersRead);//发送请求
var contentLength = httpResponseMessage.Content.Headers.ContentLength; //文件大小
using (var stream = await httpResponseMessage.Content.ReadAsStreamAsync())
{
var readLength = 1024000;//1000K
byte[] bytes = new byte[readLength];
int writeLength;
var beginSecond = DateTime.Now.Second;//当前时间秒
while ((writeLength = stream.Read(bytes, 0, readLength)) > 0)
{
//使用追加方式打开一个文件流
using (FileStream fs = new FileStream(Application.StartupPath + "/temp.rar", FileMode.Append, FileAccess.Write))
{
fs.Write(bytes, 0, writeLength);
}
downloadSize += writeLength;
downloadSpeed += writeLength;
progressBar1.Invoke((Action)(() =>
{
var endSecond = DateTime.Now.Second;
if (beginSecond != endSecond)//计算速度
{
downloadSpeed = downloadSpeed / (endSecond - beginSecond);
label1.Text = "下载速度" + downloadSpeed / 1024 + "KB/S";
beginSecond = DateTime.Now.Second;
downloadSpeed = 0;//清空
}
progressBar1.Value = Math.Max((int)(downloadSize * 100 / contentLength), 1);
}));
}
label1.Invoke((Action)(() =>
{
label1.Text = "下载完成";
}));
}
}
});
}效果图: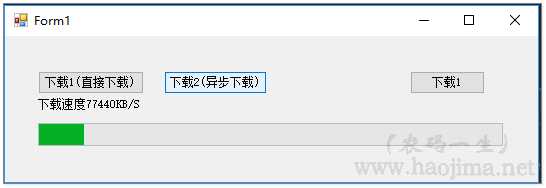
断点续传
上面的方式我们发现,如果下载到一个半断网了下次会重头开始下载。这和我们今天的主题明显不符嘛。下面我们开始正式进入主题文件下载之断点续传。把前面我们说到的头属性Range用起来。
var request = new HttpRequestMessage { RequestUri = new Uri(url) };
request.Headers.Range = new RangeHeaderValue(rangeBegin, null); //【关键点】全局变量记录已经下载了多少,然后下次从这个位置开始下载。
var httpResponseMessage = await http.SendAsync(request, HttpCompletionOption.ResponseHeadersRead);完整代码:
/// <summary>
/// 是否暂停
/// </summary>
static bool isPause = true;
/// <summary>
/// 下载开始位置(也就是已经下载了的位置)
/// </summary>
static long rangeBegin = 0; //(当然,这个值也可以存为持久化。如文本、数据库等)
private async void button3_ClickAsync(object sender, EventArgs e)
{
isPause = !isPause;
if (!isPause)//点击下载
{
button3.Text = "暂停";
await Task.Run(async () =>
{
//异步操作UI元素
label1.Invoke((Action)(() =>
{
label1.Text = "准备下载...";
}));
long downloadSpeed = 0;//下载速度
using (HttpClient http = new HttpClient())
{
var url = "http://localhost:813/新建文件夹2.rar";
var request = new HttpRequestMessage { RequestUri = new Uri(url) };
request.Headers.Range = new RangeHeaderValue(rangeBegin, null); //【关键点】全局变量记录已经下载了多少,然后下次从这个位置开始下载。
var httpResponseMessage = await http.SendAsync(request, HttpCompletionOption.ResponseHeadersRead);
var contentLength = httpResponseMessage.Content.Headers.ContentLength;//本次请求的内容大小
if (httpResponseMessage.Content.Headers.ContentRange != null) //如果为空,则说明服务器不支持断点续传
{
contentLength = httpResponseMessage.Content.Headers.ContentRange.Length;//服务器上的文件大小
}
using (var stream = await httpResponseMessage.Content.ReadAsStreamAsync())
{
var readLength = 1024000;//1000K
byte[] bytes = new byte[readLength];
int writeLength;
var beginSecond = DateTime.Now.Second;//当前时间秒
while ((writeLength = stream.Read(bytes, 0, readLength)) > 0 && !isPause)
{
//使用追加方式打开一个文件流
using (FileStream fs = new FileStream(Application.StartupPath + "/temp.rar", FileMode.Append, FileAccess.Write))
{
fs.Write(bytes, 0, writeLength);
}
downloadSpeed += writeLength;
rangeBegin += writeLength;
progressBar1.Invoke((Action)(() =>
{
var endSecond = DateTime.Now.Second;
if (beginSecond != endSecond)//计算速度
{
downloadSpeed = downloadSpeed / (endSecond - beginSecond);
label1.Text = "下载速度" + downloadSpeed / 1024 + "KB/S";
beginSecond = DateTime.Now.Second;
downloadSpeed = 0;//清空
}
progressBar1.Value = Math.Max((int)((rangeBegin) * 100 / contentLength), 1);
}));
}
if (rangeBegin == contentLength)
{
label1.Invoke((Action)(() =>
{
label1.Text = "下载完成";
}));
}
}
}
});
}
else//点击暂停
{
button3.Text = "继续下载";
label1.Text = "暂停下载";
}
}效果图:
到现在为止,你以为我们的断点续传就完成了吗?
错,你有没有发现我们使用的下载链接是a标签的。也就是我们自己写服务端提供的下载链接是不是也可以支持断点续传呢?下面我换个下载链接试试便知。
断点续传(服务端的支持)
测试结果如下: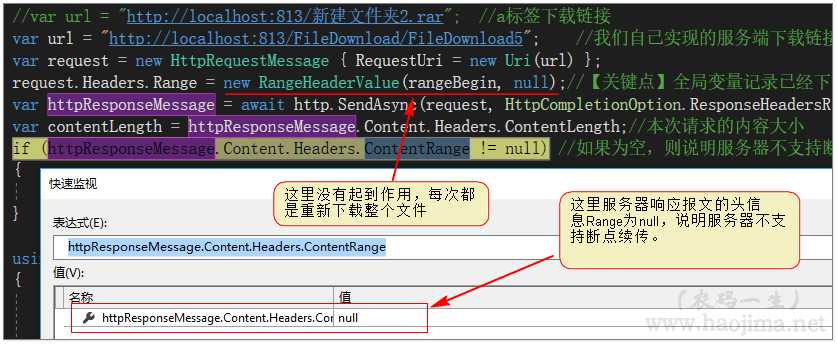
发现并不支持断点续传。为什么a标签链接可以直接支持,我们写的下载却不支持呢。
a标签的链接指向的直接是iis上的文件(iis默认支持),而我们写的却没有做响应报文表头Range的处理。(没想象中的那么智能嘛 >_<)
前面我们说过,断线续传是HTTP的一个协议。我们遵守它,它就存在,我们不遵守它也就不存在。
那下面我们修改前面的文件下载代码(服务端):
public void FileDownload5()
{
//前面可以做用户登录验证、用户权限验证等。
string filename = "大数据.rar"; //客户端保存的文件名
string filePath = Server.MapPath("/App_Data/大数据.rar");//要被下载的文件路径
var range = Request.Headers["Range"];
if (!string.IsNullOrWhiteSpace(range))//如果遵守协议,支持断点续传
{
var fileLength = new FileInfo(filePath).Length;//文件的总大小
long begin;//文件的开始位置
long end;//文件的结束位置
long.TryParse(range.Split(‘=‘)[1].Split(‘-‘)[0], out begin);
long.TryParse(range.Split(‘-‘)[1], out end);
end = end - begin > 0 ? end : (fileLength - 1);// 如果没有结束位置,那我们读剩下的全部
//表头 表明 下载文件的开始、结束位置 和文件总大小
Response.AddHeader("Content-Range", "bytes " + begin + "-" + end + "/" + fileLength);
Response.ContentType = "application/octet-stream";
Response.AddHeader("Content-Disposition", "attachment;filename=" + filename);
Response.TransmitFile(filePath, begin, (end - begin));//发送 文件开始位置读取的大小
}
else
{
Response.ContentType = "application/octet-stream";
Response.AddHeader("Content-Disposition", "attachment;filename=" + filename);
Response.TransmitFile(filePath);
}
}然后再测试断点续传,完美支持。
多线程同时下载(分片下载)
文件的断点续传已经分析完了。不过中间有些细节的东西你可以根据实际需求去完善。如:文件命名、断点续传的文件是否发生了改变、下载完成后验证文件和服务器上的是否一致。
还有我们可以根据表头属性Range来实现多线程下载,不过这里就不贴代码了,贴个效果图吧。和上一篇文件上传里的多线程上传同理。您也可以根据提供的demo代码下载查看,内有完整实现。
参考资料
demo