解读SwinTrack
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解读SwinTrack相关的知识,希望对你有一定的参考价值。
参考技术A 解读SwinTrack: A Simple and Strong Baseline for Transformer Tracking论文地址: https://arxiv.org/abs/2112.00995
目标跟踪是在一个视频的后续帧中找到在当前帧中定义的感兴趣物体的过程,依据跟踪的对象数目,分为单目标和多目标跟踪任务。其有着广泛的应用,如:视频监控,人机交互, 无人驾驶等。
目标跟踪的主流深度网络模型,按时间轴排列,分两个阶段,在2020年之前,视觉目标追踪的主干网络以CNN为主,用于目标跟踪的有SiamRCNN、Ocean等。2020年以后,基于tranformer主干网络逐渐发展起来,包括STARK、SwinTrack等。
谷歌于2017年提出的transformer网络,因其在NLP方向取得了重大进展,将Transformer架构引入CV领域尝试,思路可分为两种。
将transformer与常见的CNN架构结合,采用一种混合架构,即将注意力机制与卷积网络结合起来,试图利用两者各自的优势。
如图1为思路一框架,主要思想是先用CNN主干网络学习低分辨率特征图,再用transformer网络做特征学习,最后使用FFN(前馈神经网络)进行CV领域的任务预测。主流的网络结构有DETR[1],CoAtNet[2]。
DETR网络设计分为4步:
step1: 采用CNN主干来学习输入图像的2D表示,,,通过1*1的卷积将降为更小的维度,形成新的特征图;
step2: 将 z 0压缩为单个维度,生成 d*HW 个特征图,结合位置编码,输入到transformer的encoder中,每个encoder层包含multi-head自注意模块和FFN;
step3: encoder的输出,输入到decoder解码器中,与transformer的典型decoder不同之处:在每个解码层,采用并行解码N个输出(要求N设定大于图像中的目标种类数M);
step4: 最后解码器的输出,输入到FFN网络中,FFN由3层到ReLU激活函数的感知机组成,负责预测检测框及类别,每个FFN分支负责预测一种目标。
效果: 在COCO对象检测数据集上,精确度和速度性能与主流的Faster-RCNN效果相当。
优点:
(1) 将目标检测看做是直接的集合预测问题,移除了一些手工设计的组件,如非极大值抑制(NMS,Non-Maximum Suppression),anchor生成;
(2)适用于全景分割任务。
缺点:
(1)小物体检测效果不佳;
(2)训练时间长。
设计动机:将CNN和transformer各自的优点结合起来。
(1)CNN因卷积+池化,具备平移不变性(Translation Equivariance);
(2)Self-attention具备全局感受野,以及注意力计算随输入动态变化。
如图3为CoAtNet网络结构,构建了一个5级(S0, S1, S2, S3和S4)的网络,空间分辨率从S0到S4逐渐降低。在每个阶段的开始,我们总是将空间大小减小2倍,增加通道数量。
S0是一个普通的2层卷积块,S1是具有squeeze-excitation (SE)的MBConv块,从S2到S4,依次是MBConv,Transformer块,Transformer块。
如图4为带squeeze-excitation (SE)的MBConv块结构,内部包括1x1升维 + Depthwise Convolution + SENet + 1x1降维 + add操作。
效果: 在图像分类任务上,CoAtNet达到86.0% ImageNet top-1的精度;使用ImageNet-21K的13M图像进行预训练时, CoAtNet能达到88.56%的top-1准确率,与ViT-huge网络在JFT-300M数据集预训练的效果相当。CoAtNet在JFT-3B数据上进行预训练,可在ImageNet上获得90.88% top-1的准确率。
使用transformer完全替代CNN架构,致力于探索一个完全的注意力模型,相信在不久的将来,transformer可以打败CNN,注意力机制会作为下一代视觉网络的基本组成部分。
如图5为思路二框架,主流的网络结构有ViT[3],网络结构如图6。
网络学习过程:将图像分割成固定大小的小块,对每个小块进行线性嵌入,添加位置嵌入,并将得到的矢量序列输入标准Transformer编码器进行特征学习,最后接MLP预测图像类别。
效果: 对大量数据进行预训练,并将其传输到多个中小型图像识别基准(ImageNet、CIFAR-100、VTAB等)时,与最先进的卷积网络相比,Vision Transformer(ViT)获得了优异的结果,而训练所需的计算资源却大大减少。
缺点:
(1)在中小规模数据上直接训练,效果较差;
(2)复杂度随着图像大小呈二次增长,不适合高分辨率图像输入;
对于思路一采用的混合架构,如DETR[1],CoAtNet[2]网络,组合效果超过CNN架构,但发展趋于饱和,效果提升空间有限。
对于思路二采用transformer梯度CNN结构,发展较为缓慢,首个视觉注意力模型ViT,以及它的很多后继者,在性能上都不如卷积神经网络,直到Swin-Transformer网络[4]的提出,在目标检测、实例分割等任务上性能远超CNN。
SwinTrack论文作者基于思路二,充分利用Swin-Transformer主干网的能力,结合目标跟踪Siamese经典框架,提出 SwinTrack框架,在LaSOT公开数据集上以0.717的SUC刷新记录,同时仍以45帧/秒的速度运行。
如图7,SwinTrack的三种变体网络(红色虚线圆内)性能>Transformer结合CNN的混合架构>CNN为主干网络,验证了SwinTrack实现目标跟踪任务的先进性。
Swin-Transformer作为一种新的视觉transformer, 采用了基于注意的分层窗口架构解决了transformer结构从语言迁移到视觉的两大挑战性问题:1)视觉元素变化规模大;2)图像中像素分辨率高。网络设计创新之处,总结为两点:
(1)引入非重叠窗口划分,将自注意力计算限制在局部窗口内,降低计算复杂度为图像大小的线性关系,并提出错位窗口方案,增加跨窗口连接。
Layer1到Layer1+1之间的跨窗口连接,通过对layer1层的切分线分别上下左右移动窗口长度/2的位置。
(2)网络由浅到深层,下一层的特征图通过逐渐合并上一层的邻域窗口来构建分层特征图,形成特征金子塔,用于密集预测任务(如像素级分割)。
如图10为Swin-Tansformer的网络结构图,整个Swin Transformer架构,和CNN架构非常相似,构建了4个stage,每个stage中都是类似的重复单元。和ViT类似,通过patch partition将输入图片HxWx3划分为不重合的patch集合,其中每个patch尺寸为4x4,那么每个patch的特征维度为4x4x3=48,patch块的数量为H/4 x W/4;stage1部分,先通过一个linear
embedding将输划分后的patch特征维度变成C,然后送入Swin Transformer Block;stage2-stage4操作相同,先通过一个patch merging,将输入按照2x2的相邻patches合并,这样子patch块的数量就变成了H/8 x W/8,特征维度就变成了4C。
每个Swin Transformer Block包括多个注意力层(偶数个),图11为两个连续的注意力层。其中W-MSA为基于窗口的多头注意力模块,SW-MSA为窗口错位划分,引入跨窗口连接。
SwinTrack目标跟踪框架设计参考全卷积Siamese跟踪网络[12]。
思路: 将搜索图像和目标图像用相同的CNN网络进行提取特征,然后再将目标图像的特征作为卷积核和整个搜索图片求卷积。最后生成的是一层的Feature Map,将置信度最高的地方这个区域看作是目标。
本文选择了一个挑战性的目标任务:视觉目标追踪,该任务至今仍有许多问题没有很好地解决,包括在遮挡或视线之外的重新定位,相似物体之间的区分。
SwinTrack论文作者基于思路二,充分利用Swin-Transformer主干网的能力,结合目标跟踪Siamese经典框架,提出 SwinTrack框架,在LaSOT公开数据集上以0.717的SUC刷新记录,同时仍以45帧/秒的速度运行。
SwinTrack网络如图13所示。从左到右依次是:1)特征抽取:Swin-Transformer主干网络,2)特征融合:基于注意力的编码器-解码器,3)分类预测和位置回归层。
在目标跟踪过程中,首先主干网络利用共享的权值分别抽取target template 图像块和Search Region图像块特征;然后将target template和Search Region的特征串联融合,输入到编码网络,通过注意力机制逐层增强串联的特征符号;位置编码有助于区分不同来源和位置的特征符号;最后,解码网络生成search image的最终特征图,送入到分类预测和位置回归层,分两个分支,一个是前景-背景分类预测;另一个是目标位置回归预测。
特征融合通过构建基于注意力的编码-解码器实现,目的是实现target
template和Search Region特征的交互以进行跟踪。
特征融合- 编码器: 在主干网络分别输出template image和search image的图像块特征之后,特征表示为z, x,可沿着空间维度将两种图像的特征串联起来,生成联合的特征表示U,将联合特征表示U输入编码器中,对于编码器的每个网络块,MSA负责在U上计算自注意力,FFN对MSA生成的特征进行提炼,编码器输出的时候,对特征执行分解操作,恢复出template image和search image各自的特征表示。该特征融合方式可称为 基于连接的融合 ,公式表示如下:
编码器中的网络块(注意力模块)结构如图14所示。其中MSA为多头自注意力机制,LN为层归一化,FFN为前馈神经网络。
特征融合- 解码器 由一个多头交叉注意模块和前馈网络组成,输入为编码器的输出,即template image的特征zL和search image的特征xL,输出通过计算xL和Concat(xL,zL)L的交叉注意获得最后的特征图。
解码器网络结构见图15,其中MCA为多头交叉注意力机制。
作者解释了为什么采用基于连接的融合方法:
为了融合处理多个分支的特征,直观的做法是分别对每个分支的特征做自注意力计算,完成特征提取,然后计算跨不同分支特征的Cross Attention,完成特征融合。作者称这种方法为 基于交叉注意力的融合。 考虑因transformer是Seq2seq结构,自然支持多模态信息的输入,通过串联操作,相比于Cross Attention,可以节省计算,通过权重共享,而不是对每个分支单独进行自注意力计算,可以减少模型参数量。
作者为什么不采用端到端的框架来预测目标跟踪任务?
原因是通过实验验证,当采用transformer-style编码器直接预测目标任务,需要更长的时间收敛,且跟踪性能较差。文章通过一些后处理的步骤来提升模型性能,如通过密集预测,可以向模型提供更丰富的监督信号,从而加快训练过程。此外,可以使用更多的领域知识来帮助提高跟踪性能,例如在响应图上应用Hanning penalty window来引入smooth movement assumption。此外,在我们的实验中发现,传统transformer decoder很难恢复2D位置信息。
作用是为了给模型提供词序信息,本文采用TUPE[8]提出的untied positional encoding,并将其推广到任意维度,以适用本文提出跟踪器的其他组件。对于单头的自注意力模块,自注意力函数表示:
其中 xi 为单头的自注意力模块输入, zi 为单头的自注意力模块输出。区别于untied positional encoding,Tranformer网络原来自带的位置编码策略,是在自注意模块中加入一个可学习的位置编码 p ,其中 x 为词嵌入,公式如下:
上式包含四项:token-to-token, position-to-token,
token-to-position,position-to-token.论文[9]指出公式中存在的问题,因词嵌入 x 和绝对位置嵌入 p 的信息为异构的,直接相加本身不合理,因此提出untied
positional encoding,去除了公式(7)中红框里的两项,公式表示如下:
其中 pi 和 pj 分别是位置 i 和 j 处的位置嵌入, UQ 和 UK 是位置嵌入向量的可学习的投影矩阵, l 为网络层数。同时因 p 为绝对位置嵌入,论文[10]提出引入相对位置偏差作为互补,公式如下:
将位置编码扩展到多维空间。 方法是为每个维数分配一个位置嵌入矩阵,然后将不同维数的嵌入向量在相应的索引处相加,得到最终的嵌入向量。加上相对位置偏差,对于n维情况,我们有:
在特征融合阶段,为了区分不同来源的图像特征,分别对两种来源的绝对位置编码进行连接,并在相对位置偏差上增加一对索引,以区分query和key向量的不同来源。
其中g和h为encoder输出各自图像特征的query和key索引,1来自于template
image,2来自于search image.
包含两个分支:分类预测和边框回归预测。每个分支是三层感知机,其中分类是对前景和背景的分类预测。分类训练目标采用IoU-aware classification score(IACS), 即为预测边框与其ground truth之间的IoU, IACS可以帮助模型从候选池中选择一个更精确的包围框。分类损失函数为varifocal loss,公式如下:
其中 p 为预测的IACS, q 为目标得分。对于正样本,即前景点,q为预测边框与地ground-truth边框之间的IoU。对于负样本,q = 0。于是,分类损失函数为:
其中,b为预测的边框,表示ground-truth边框。
解决正负样本不平衡: 通过修改 p γ ,可减少背景点(负样本的损失),而不影响前景点损失,同时用训练目标 q 对正样本进行加权,即IoU越大,对损失的贡献越大,促使模型关注高质量正样本。
对于边框回归预测,我们采用GIoU损失[11],取值范围[-1,1],对目标物体的scale不敏感。回归损失函数可以表示为:
采用概率 p 对GIoU损失进行加权,以强调高分类得分的样本。
SwinTrack在LaSOT上以0.717的SUC刷新了记录,在45帧/秒的情况下,超过了STARK[6] 4.6%。此外,它在其他具有挑战性的LaSOText、TrackingNet和GOT-10k数据集上实现了0.483 SUC、0.832 SUC和0.694 AO的最先进性能。
参考文献
[1]Zihang Dai, Hanxiao Liu,Quoc V Le, and Mingxing Tan. Coatnet: Marrying convolution and attention forall data sizes. arXiv, 2021.
[2]NicolasCarion,FranciscoMassa,GabrielSynnaeve,Nicolas Usunier, AlexanderKirillov, and Sergey Zagoruyko. End-to- end object detection with transformers.In ECCV, 2020.
[3] Alexey Dosovitskiy, LucasBeyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, ThomasUnterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vainGelly, et al. An image is worth 16x16 words: Trans- formers for imagerecognition at scale. In ICLR, 2021.
[4] Ze Liu, Yutong Lin, YueCao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swintransformer: Hierarchical vision transformer using shifted windows. In-ternational Conference on Computer Vision (ICCV), 2021.
[5]XinChen,BinYan,JiawenZhu,DongWang,XiaoyunYang, and Huchuan Lu. Transformertracking. In CVPR, 2021.
[6] Bin Yan, Houwen Peng,Jianlong Fu, Dong Wang, and Huchuan Lu. Learning spatio-temporal transformerfor visual tracking. In ICCV, 2021.
[7] JaneBromley,JamesWBentz,LéonBottou,IsabelleGuyon, Yann LeCun, Cliff Moore, Eduard Sa ̈ckinger, andRoopak Shah. Signature verification using a “siamese” time delay neuralnetwork. International Journal of Pattern Recognition and ArtificialIntelligence, 7(04):669–688, 1993.
[8] Guolin Ke, Di He, andTie-Yan Liu. Rethinking positional encoding in language pre-training. InInternational Confer- ence on Learning Representations, 2021.
[9] Guolin Ke, Di He, andTie-Yan Liu. Rethinking positional encoding in language pre-training. InInternational Confer- ence on Learning Representations, 2021.
[10] Peter Shaw, JakobUszkoreit, and Ashish Vaswani. Self- attention with relative positionrepresentations. arXiv, 2018.
[11] Hamid Rezatofighi, NathanTsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, and Silvio Savarese. Generalizedin- tersection over union. 2019.
[12] Bertinetto L , Valmadre J, Henriques J F , et al. Fully-Convolutional Siamese Networks for ObjectTracking. 2016.
YOLOV7详细解读网络架构解读
YOLOV7详细解读
网络架构解读
前言
继美团发布YOLOV6之后,YOLO系列原作者也发布了YOLOV7。
YOLOV7主要的贡献在于:
1.模型重参数化
YOLOV7将模型重参数化引入到网络架构中,重参数化这一思想最早出现于REPVGG中。
2.标签分配策略
YOLOV7的标签分配策略采用的是YOLOV5的跨网格搜索,以及YOLOX的匹配策略。
3.ELAN高效网络架构
YOLOV7中提出的一个新的网络架构,以高效为主。
4.带辅助头的训练
YOLOV7提出了辅助头的一个训练方法,主要目的是通过增加训练成本,提升精度,同时不影响推理的时间,因为辅助头只会出现在训练过程中。
一、YOLOV7是什么?
YOLO算法作为one-stage目标检测算法最典型的代表,其基于深度神经网络进行对象的识别和定位,运行速度很快,可以用于实时系统。
YOLOV7是目前YOLO系列最先进的算法,在准确率和速度上超越了以往的YOLO系列。
了解YOLO是对目标检测算法研究的一个必须步骤。
二、网络架构
1、架构图总览
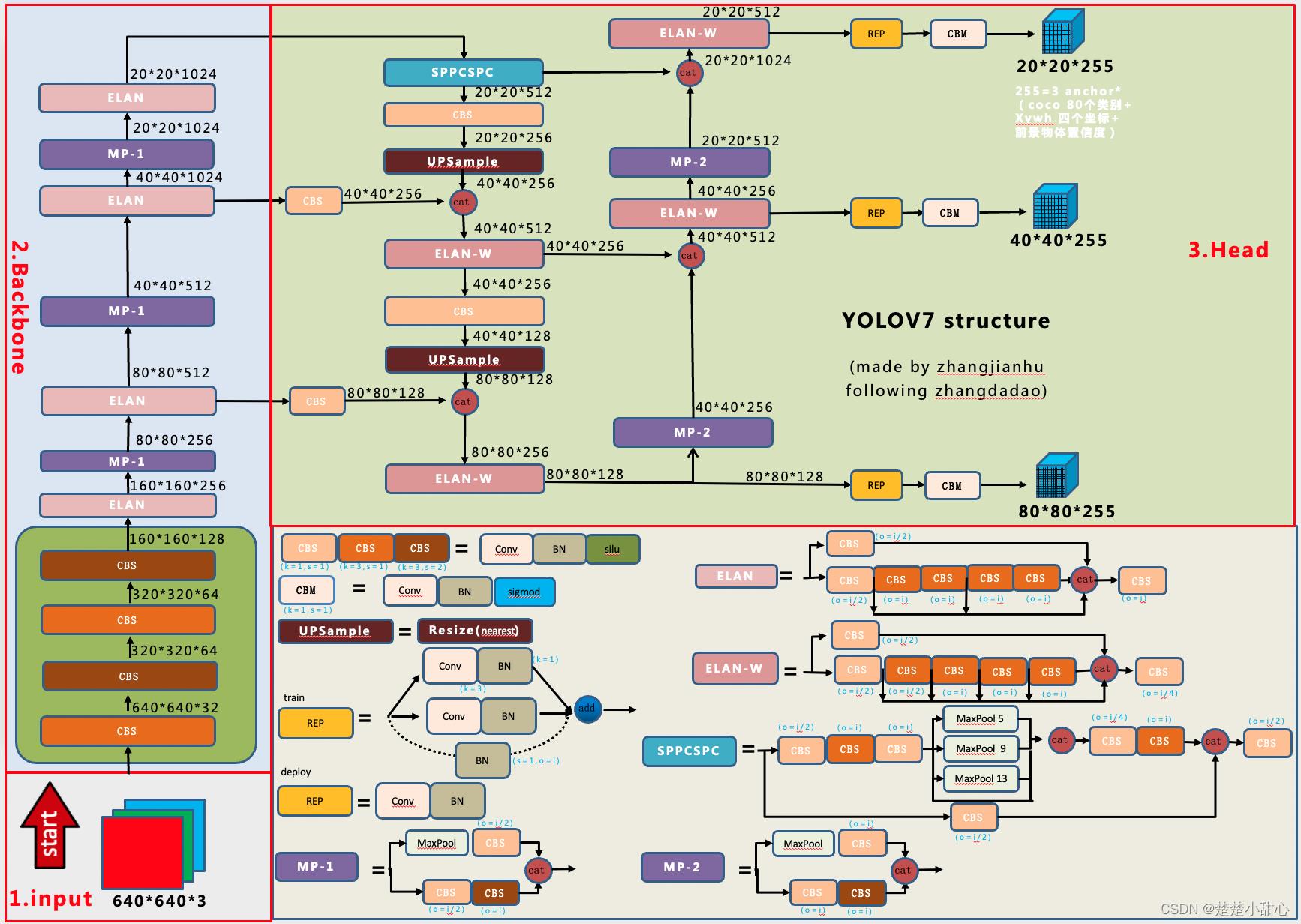
2、CBS模块解读
- 对于CBS模块,我们可以看从图中可以看出它是由一个Conv层,也就是卷积层,一个BN层,也就是Batch normalization层,还有一个Silu层,这是一个激活函数。
- silu激活函数是swish激活函数的变体,两者的公式如下所示
silu(x)=x⋅sigmoid(x)
swish(x)=x⋅sigmoid(βx)
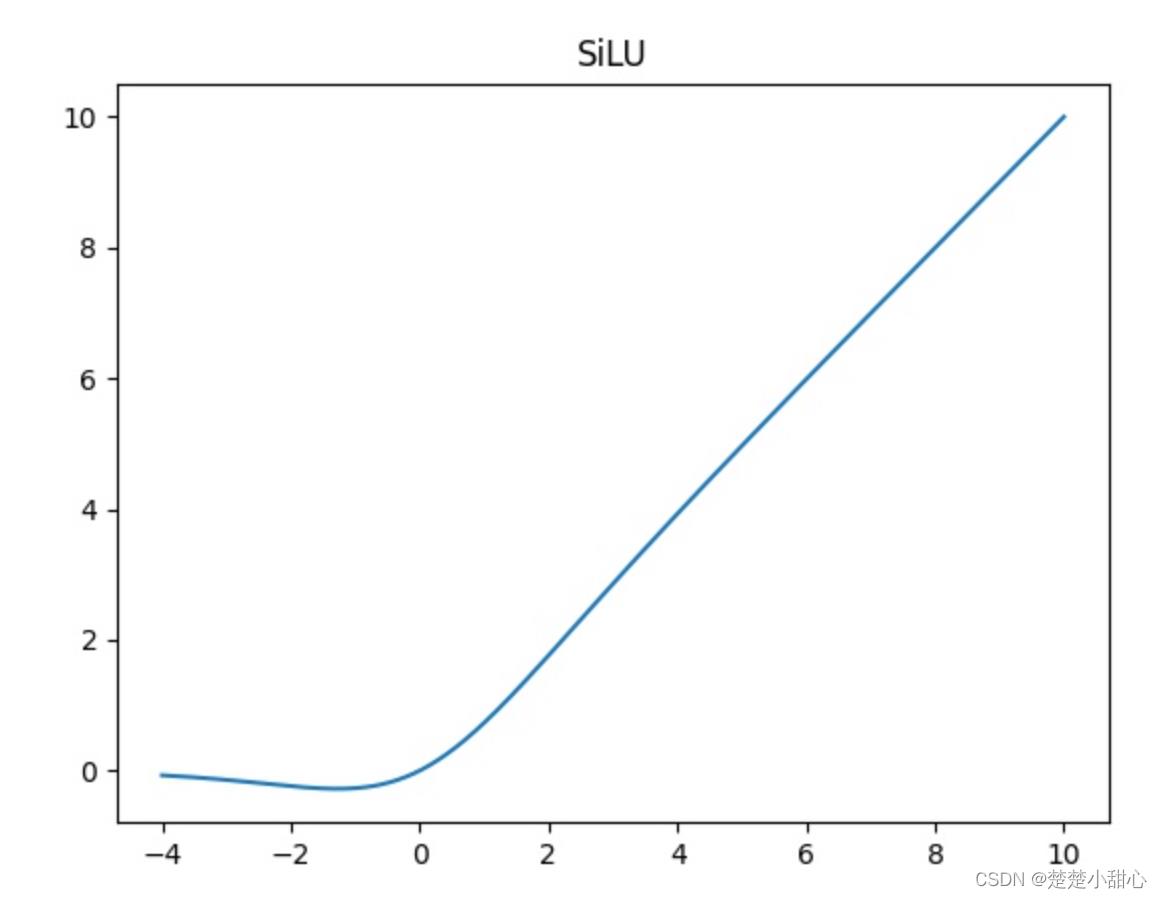
- 从架构图中我们可以看出,CBS模块这里有三种颜色,三种颜色代表它们的卷积核(k)和步长(s)不同。
首先最浅的颜色,也就是第一个CBS模块的颜色,它是一个1x1的卷积,stride(步长为1)。
其次稍浅的颜色,也就是第二个CBS模块的颜色,它是一个3x3的卷积,stride(步长为1)。
最后最深的颜色,也就是第三个CBS模块的颜色,它是一个3x3的卷积,stride(步长为2)。 - 1x1的卷积主要用来改变通道数。
- 3x3的卷积,步长为1,主要用来特征提取。
- 3x3的卷积,步长为2,主要用来下采样。

3、CBW模块解读
- CBW模块和CBS模块,我们可以看出来是基本一致的。
- 由一个Conv层,也就是卷积层,一个BN层,也就是Batch normalization层,还有一个sigmoid层,这是一个激活函数。
- 卷积核为1x1,stride(步长为1)

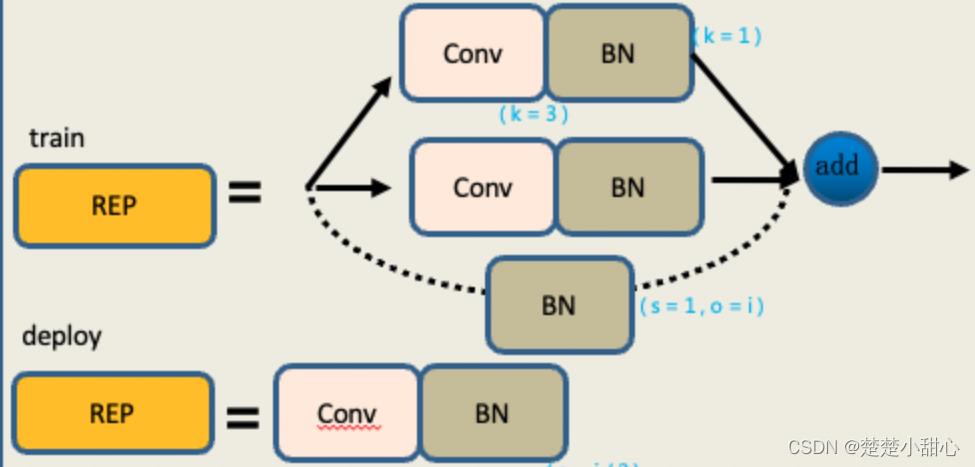
4、REP模块解读
- REP模块分为两个,一个是train,也就是训练,一个deploy,也就是推理。
- 训练模块,它有三个分支。
最上面的分支是3x3的卷积,用于特征提取。
中间的分支是1x1的卷积,用于平滑特征。
最后分支是一个Identity,不做卷积操作,直接移过来。
最后把它们相加在一起。 - 推理模块,包含一个3x3的卷积,stride(步长为1)。是由训练模块重参数化转换而来。
在训练模块中,因为第一层是一个3x3的卷积,第二层是一个1x1的卷积,最后层是一个Identity。
在模型从参数化的时候,需要把1x1的卷积啊,转换成3x3的卷积,把Identity也转换成3x3的卷积,然后进行一个矩阵的一个加法,也就是一个矩阵融合过程。
然后最后将它的权重进行相加,就得到了一个3x3的卷积,也就是说,这三个分支就融合成了一条线,里面只有一个3x3的卷积。
它们的权重是三个分支的叠加结果,矩阵,也是三个分支的叠加结果。
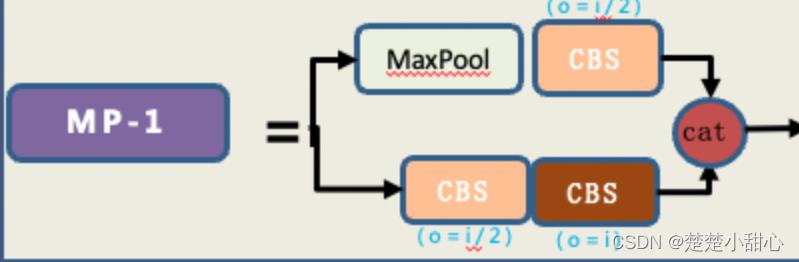
5、MP模块解读
- MP模块有两个分支,作用是进行下采样。
- 第一条分支先经过一个maxpool,也就是最大池化。最大值化的作用就是下采样,然后再经过一个1x1的卷积进行通道数的改变。
- 第二条分支先经过一个1x1的卷积,做通道数的变化,然后再经过一个3x3卷积核、步长为2的卷积块,这个卷积块也是用来下采样的。
- 最后把第一个分支和第二分支的结果加在一起,得到了超级下采样的结果。
6、ELAN模块解读
- ELAN模块是一个高效的网络结构,它通过控制最短和最长的梯度路径,使网络能够学习到更多的特征,并且具有更强的鲁棒性。
- ELAN有两条分支。
- 第一条分支是经过一个1x1的卷积做通道数的变化。
- 第二条分支就比较复杂了。它先首先经过一个1x1的卷积模块,做通道数的变化。然后再经过四个3x3的卷积模块,做特征提取。
- 如图所示,最后把四个特征叠加在一起得到最后的特征提取结果。

7、ELAN-W模块解读
- 对于ELAN-W模块,我们也看到它跟ELAN模块是非常的相似,所略有不同的就是它在第二条分支的时候选取的输出数量不同。
- ELAN模块选取了三个输出进行最后的相加。
- ELAN-W模块选取了五个进行相加。

8、UPSample模块解读
UPSample模块是一个上采样的模块,它使用的上采样方式是最近邻插值。

9、SPPCSPC模块解读
SPP的作用是能够增大感受野,使得算法适应不同的分辨率图像,它是通过最大池化来获得不同感受野。
- 我们可以看到在第一条分支中,经理了maxpool的有四条分支。分别是5,9,13,1,这四个不同的maxpool就代表着他能够处理不同的对象。
- 也就是说,它这四个不同尺度的最大池化有四种感受野,用来区别于大目标和小目标。
比如一张照片中的狗和行人以及车,他们的尺度是不一样的,通过不同的maxpool,这样子就能够更好的区别小目标和大目标。
CSP模块,首先将特征分为两部分,其中的一个部分进行常规的处理,另外一个部分进行SPP结构的处理,最后把这两个部分合并在一起,这样子就能够减少一半的计算量,使得速度变得快,精度反而会提升。

以上是关于解读SwinTrack的主要内容,如果未能解决你的问题,请参考以下文章