Glove 原理详细解读
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Glove 原理详细解读相关的知识,希望对你有一定的参考价值。
参考技术A 本文主要对《GloVe: Global Vectors for Word Representation》进行解读。尽管word2vector在学习词与词间的关系上有了大进步,但是它有很明显的缺点:只能利用一定窗长的上下文环境,即利用局部信息,没法利用整个语料库的全局信息。鉴于此,GloVe诞生了,它的全称是global vector,很明显它是要改进word2vector,利用语料库的全局信息。
什么是 共现 ?
单词 出现在单词 的环境中(论文给的环境是以为中心的左右10个单词区间)叫共现。
什么是 共现矩阵 ?
共现矩阵是单词对共现次数的统计表。我们可以通过大量的语料文本来构建一个共现统计矩阵。
例如,有语料如下:
I like deep learning.
I like NLP.
I enjoy flying.
以窗半径为1来指定上下文环境,则共现矩阵就应该是:
X01:它表示like出现在I的环境(I like区间)中的次数(在整个语料库中的总计次数),此处应当为2次,故第一行第二列应当填2。还应当发现,这个共现矩阵它是对称阵,因为like出现在I的环境中,那么必然I也会出现在like的环境中,所以X10= 2。
共现矩阵有以下3个特点:
·统计的是单词对在给定环境中的共现次数;所以它在一定程度上能表达词间的关系。
·共现频次计数是针对整个语料库而不是一句或一段文档,具有全局统计特征。
·共现矩阵它是对称的。
共现矩阵的生成步骤:
·首先构建一个空矩阵,大小为V×V,即词汇表×词汇表,值全为0。矩阵中的元素坐标记为 。
·确定一个滑动窗口的大小(例如取半径为 m )
·从语料库的第一个单词开始,以1的步长滑动该窗口,因为是按照语料库的顺序开始的,所以中心词为到达的那个单词即 。
·上下文环境是指在滑动窗口中并在中心单词 两边的单词。
·若窗口左右无单词,一般出现在语料库的首尾,则空着,不需要统计。
·在窗口内,统计上下文环境中单词出现的次数,并将该值累计到 位置上。
·不断滑动窗口进行统计即可得到共现矩阵。
什么是叫 共现概率 ?
定义X为共现矩阵,共现矩阵的元素 为词 出现在词 环境的次数,令 ,为任意词出现在 的环境的次数(即共现矩阵第 行的和),那么:
为词 出现在词环境中的概率(这里以频率计算概率),这一概率被称为词 和词 的共现概率。共现概率是指在给定的环境下出现(共现)某一个词的概率。 注意 :在给定语料库的情况下,我们是可以事先计算出任意一对单词的共现概率的。
接下来阐述为啥作者要提共现概率和共现概率比这一概念。下面是论文中给的一组数据:
先看一下第一行数据,以 ice 为中心词的环境中出现 solid 固体的概率是大于 gas、fashion 而且小于 water 的,这是很合理的,对吧,因为现实语言使用习惯就是这样的。同理可以解释第二行数据。我们来重点考虑第三行数据: 共现概率比 。我们把共现概率相比,我们发现:
1.看第三行第一列:当 ice 的语境下共现 solid 的概率应该很大,当 stream 的语境下共现 solid 的概率应当很小,那么比值就>1。
2.看第三行第二列:当 ice 的语境下共现 gas 的概率应该很小,当 stream 的语境下共现 gas 的概率应当很大,那么比值就<1。
3.看第三行第三列:当 ice 的语境下共现 water 的概率应该很大,当 stream 的语境下共现 water 的概率也应当很大,那么比值就近似=1。
4.看第三行第四列:当 ice 的语境下共现 fashion 的概率应该很小,当 stream 的语境下共现 fashion 的概率也应当很小,那么比值也是近似=1。
因为作者发现用共现概率比也可以很好的体现3个单词间的关联(因为共现概率比符合常理),所以glove作者就大胆猜想, 如果能将3个单词的词向量经过某种计算可以表达共现概率比就好了(glove思想) 。如果可以的话,那么这样的 词向量就与共现矩阵有着一致性 ,可以体现词间的关系。
想要表达共现概率比,这里涉及到的有三个词即 ,它们对应的词向量用 表示,那么我们需要找到一个映射 ,使得: ,等式的右边的比值可以通过统计得到。这个比值可以作为标签,我们需要设计一个模型通过训练的方式让映射值逼近这个确定的共现概率比。很明显这是个回归问题,我们可以用均方误差作为loss。当然,设计这个函数或者这个模型当然有很多途径,我们来看看作者是怎么设计的。
下面将从如何构造 展开讨论,首先声明以下的内容 更多的是体现作者构造模型的思路, 而 不是严格的数学证明。
为了让 左右两边相等,很容易想到用两者的均方差做代价函数:
但是里面含有3个单词,这意味这要在V*V*V的复杂度上计算,太复杂了。
为了简化计算 ,作者是这样思考的:
1. 为了考虑单词 和单词 之间的关系,那么 是一个合理的选择
2. 是标量,而 均为向量,为了将向量转为标量,可以将两个向量做内积,于是有了
3. 接着,作者在 外面加了指数运算exp(),得到:
即:
即:
即:
这样,便可以 发现简化方法 了:只需要上式分子对应相等,分母对应相等即可。
即: 并且
考虑到 和 形式是相同的,于是进行统一考虑,即:
本来我们追求的是:
现在只需要追求:
两边取对数:
那么代价函数可简化为:
现在只需要在V*V的复杂度上进行计算。
4.仔细观察 和 可以发现: 不等于 但是 和 是相等的。即等式左侧不具有对称性而右侧有对称性。这在数学上出现问题,有可能会导致模型无法训练优化。
为了解决这个问题将 中的 按照条件概率展开,即为:
将其变为:
即添加一个偏置项 ,将 吸收到偏置项 中。
于是代价函数变成了:
5.在代价函数中添加权重项,于是代价函数进一步进化为:
是怎样的呢?有什么作用呢?为什么要添加权重函数?
我们知道在一个语料库中,肯定存在很多单词他们在一起出现的次数是很多的,那么我们希望:
1.这些单词的权重须大于那些很少在一起出现的单词,所以这个函数要是非递减函数;
2.但我们也不希望这个权重过大,当到达一定程度之后应该不再增加;
3.如果两个单词没有在一起出现,也就是 ,那么他们应该不参与到loss function的计算当中去,也就是 要满足
满足以上条件的函数有很多,作者采用了如下形式的分段函数:
函数图像:
这篇glove论文中的所有实验,的取值都是 为0.75,而 为100
也就是说词对共现次数越多的,有更大的权重将被惩罚得更厉害些;次数少,有更小的惩罚权重,这样就可以使得不常共现的词对对结果的贡献不会太小,而不会过分偏向于常共现的词对。
那么总结下,glove的优化目标为:
Q uestion&Answer
Question1: GloVe是如何训练的?
Answer1: 虽然很多人声称GloVe是一种无监督的学习方式(因为它确实不需要人工标注label),但其实它还是有label的,这个label就是优化目标中的 。而优化目标中的 就是要不断更新/学习的参数,所以本质上它的训练方式跟监督学习的训练方法没什么不一样,都是基于梯度下降的。具体地,这篇论文里的实验是这么做的:采用了AdaGrad的梯度下降算法,对矩阵中的所有非零元素进行随机采样,学习率(learning rate)设为0.05,在vector size小于300的情况下迭代了50次,其他大小的vectors上迭代了100次,直至收敛。最终学习得到的是两个vector是 ,因为X是对称的,所以从原理上讲 也是对称的,他们唯一的区别是初始化的值不一样,而导致最终的值不一样。所以这两者其实是等价的,都可以当成最终的结果来使用。但是为了提高鲁棒性,最终会选择两者之和作为最终的vector(两者的初始化不同相当于加了不同的随机噪声,所以能提高鲁棒性)。
三千多字,码字不易,如果大家发现我有地方写得不对或者有疑问的,麻烦评论, 我会回复并改正 。对于重要问题,我会持续更新至 Question&Answer。
参考
Pennington J , Socher R , Manning C . Glove: Global Vectors for Word Representation[C]// Conference on Empirical Methods in Natural Language Processing. 2014.
CS224N Winter 2019
Glove模型---词向量模型
GloVe详解
详解GloVe词向量模型
详细解读SpringMVC工作原理,附加视频教程!
有趣有内涵的内容,第一时间送达!
SpringMVC的工作原理图:
SpringMVC流程
用户发送请求至前端控制器DispatcherServlet。
DispatcherServlet收到请求调用HandlerMapping处理器映射器。
处理器映射器找到具体的处理器(可以根据xml配置、注解进行查找),生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet。
DispatcherServlet调用HandlerAdapter处理器适配器。
HandlerAdapter经过适配调用具体的处理器(Controller,也叫后端控制器)。
Controller执行完成返回ModelAndView。
HandlerAdapter将controller执行结果ModelAndView返回给DispatcherServlet。
DispatcherServlet将ModelAndView传给ViewReslover视图解析器。
ViewReslover解析后返回具体View。
DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)。
DispatcherServlet响应用户。
组件说明:
DispatcherServlet:作为前端控制器,整个流程控制的中心,控制其它组件执行,统一调度,降低组件之间的耦合性,提高每个组件的扩展性。
HandlerMapping:通过扩展处理器映射器实现不同的映射方式,例如:配置文件方式,实现接口方式,注解方式等。
HandlAdapter:通过扩展处理器适配器,支持更多类型的处理器。
ViewResolver:通过扩展视图解析器,支持更多类型的视图解析,例如:jsp、freemarker、pdf、excel等。
组件:
1、前端控制器DispatcherServlet(不需要工程师开发),由框架提供
作用:接收请求,响应结果,相当于转发器,中央处理器。有了dispatcherServlet减少了其它组件之间的耦合度。
用户请求到达前端控制器,它就相当于mvc模式中的c,dispatcherServlet是整个流程控制的中心,由它调用其它组件处理用户的请求,dispatcherServlet的存在降低了组件之间的耦合性。
2、处理器映射器HandlerMapping(不需要工程师开发),由框架提供
作用:根据请求的url查找Handler
HandlerMapping负责根据用户请求找到Handler即处理器,springmvc提供了不同的映射器实现不同的映射方式,例如:配置文件方式,实现接口方式,注解方式等。
3、处理器适配器HandlerAdapter
作用:按照特定规则(HandlerAdapter要求的规则)去执行Handler
通过HandlerAdapter对处理器进行执行,这是适配器模式的应用,通过扩展适配器可以对更多类型的处理器进行执行。
4、处理器Handler(需要工程师开发)
注意:编写Handler时按照HandlerAdapter的要求去做,这样适配器才可以去正确执行Handler
Handler 是继DispatcherServlet前端控制器的后端控制器,在DispatcherServlet的控制下Handler对具体的用户请求进行处理。
由于Handler涉及到具体的用户业务请求,所以一般情况需要工程师根据业务需求开发Handler。
一般情况下需要通过页面标签或页面模版技术将模型数据通过页面展示给用户,需要由工程师根据业务需求开发具体的页面。
6、视图View(需要工程师开发jsp...)
View是一个接口,实现类支持不同的View类型(jsp、freemarker、pdf...)
核心架构的具体流程步骤如下:
首先用户发送请求:DispatcherServlet,前端控制器收到请求后自己不进行处理,而是委托给其他的解析器进行处理,作为统一访问点,进行全局的流程控制;
DispatcherServlet:HandlerMapping, HandlerMapping 将会把请求映射为HandlerExecutionChain 对象(包含一个Handler 处理器(页面控制器)对象、多个HandlerInterceptor 拦截器)对象,通过这种策略模式,很容易添加新的映射策略;
DispatcherServlet:HandlerAdapter,HandlerAdapter 将会把处理器包装为适配器,从而支持多种类型的处理器,即适配器设计模式的应用,从而很容易支持很多类型的处理器;HandlerAdapter:处理器功能处理方法的调用,HandlerAdapter 将会根据适配的结果调用真正的处理器的功能处理方法,完成功能处理;并返回一个ModelAndView 对象(包含模型数据、逻辑视图名);
ModelAndView的逻辑视图名: ViewResolver, ViewResolver 将把逻辑视图名解析为具体的View,通过这种策略模式,很容易更换其他视图技术;
View:渲染,View会根据传进来的Model模型数据进行渲染,此处的Model实际是一个Map数据结构,因此很容易支持其他视图技术;
返回控制权给DispatcherServlet,由DispatcherServlet返回响应给用户,到此一个流程结束。
下边两个组件通常情况下需要开发:
Handler:处理器,即后端控制器用controller表示。
View:视图,即展示给用户的界面,视图中通常需要标签语言展示模型数据。
在说SpringMVC之前我们先来看一下什么是MVC模式
MVC的原理图:
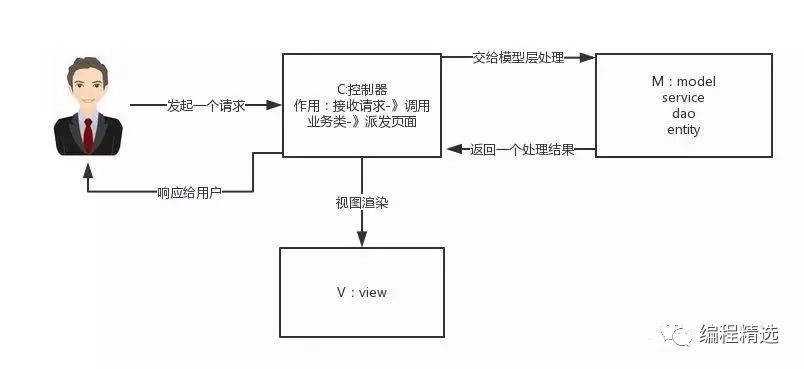
分析:
M-Model 模型(完成业务逻辑:有javaBean构成,service+dao+entity)
V-View 视图(做界面的展示 jsp,html……)
C-Controller 控制器(接收请求—>调用模型—>根据结果派发页面)
SpringMVC是什么:
springMVC是一个MVC的开源框架,springMVC=struts2+spring,springMVC就相当于是Struts2加上sring的整合,但是这里有一个疑惑就是,springMVC和spring是什么样的关系呢?
这个在百度百科上有一个很好的解释:意思是说,springMVC是spring的一个后续产品,其实就是spring在原有基础上,又提供了web应用的MVC模块,可以简单的把springMVC理解为是spring的一个模块(类似AOP,IOC这样的模块),网络上经常会说springMVC和spring无缝集成,其实springMVC就是spring的一个子模块,所以根本不需要同spring进行整合。
SpringMVC的原理图:
看到这个图大家可能会有很多的疑惑,现在我们来看一下这个图的步骤:(可以对比MVC的原理图进行理解)
用户发起请求到前端控制器(DispatcherServlet)
前端控制器请求处理器映射器(HandlerMappering)去查找处理器(Handle):通过xml配置或者注解进行查找
找到以后处理器映射器(HandlerMappering)像前端控制器返回执行链(HandlerExecutionChain)
前端控制器(DispatcherServlet)调用处理器适配器(HandlerAdapter)去执行处理器(Handler)
处理器适配器去执行Handler
Handler执行完给处理器适配器返回ModelAndView
处理器适配器向前端控制器返回ModelAndView
前端控制器请求视图解析器(ViewResolver)去进行视图解析
视图解析器像前端控制器返回View
前端控制器对视图进行渲染
前端控制器向用户响应结果
看到这些步骤我相信大家很感觉非常的乱,这是正常的,但是这里主要是要大家理解SpringMVC中的几个组件:
前端控制器(DispatcherServlet):接收请求,响应结果,相当于电脑的CPU。
处理器映射器(HandlerMapping):根据URL去查找处理器
处理器(Handler):(需要程序员去写代码处理逻辑的)
处理器适配器(HandlerAdapter):会把处理器包装成适配器,这样就可以支持多种类型的处理器,类比笔记本的适配器(适配器模式的应用)
视图解析器(ViewResovler):进行视图解析,多返回的字符串,进行处理,可以解析成对应的页面。
获取视频教程资料
后台回复:005
往期精选推荐:
-END-
欢迎关注订阅号编程精选,加小编微信获取更多资源!
以上是关于Glove 原理详细解读的主要内容,如果未能解决你的问题,请参考以下文章