Bloom Filter 算法具体解释
Posted lcchuguo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Bloom Filter 算法具体解释相关的知识,希望对你有一定的参考价值。
Bloom Filter 算法
Bloom filter是由Burton Bloom 在1970年提出的,其后在P2P上得到了广泛的应用。Bloom filter 算法可用来查询某一数据是否在某一数据集合中。其长处是查询效率高、可节省空间。但其缺点是会存在一定的错误。因此Bloom filter 算法仅仅能应用于那些同意有一定错误的场合。可使用Bloom filter 算法的场合包含字典软件、分布式缓存、P2P网络和资源路由等等。
使用Bloom Filter我们能够推断一个元素是否在某一个集合中。假设这个集合是使用线性结构存储的话。其查找的时间复杂度是O(n);使用像二叉树或B-tree这种树形结构存储的话其查找的时间复杂度是O(logn)。而使用Bloom Filter在能够容忍一定错误率的情况下,其时间复杂度是O(1)。因此,与传统的权衡空间或时间的算法不同,Bloom Filter 极其巧妙。通过引入一定的错误率来换取时间和空间,在某些应用大大提高了性能。
Bloom Filter 算法应用
使用Bloom Filter算法查找某个元素是否属于某个集合是常数时间,并且Bloom Filter使用的是位数组,大大降低了空间。
尽管有一定的错误率。但对于那些同意有一定错误的场合则十分有效。
使用Bloom Filter还能够进行垃圾邮件过滤。由于垃圾邮件的数量是很巨大的。假设将所有的垃圾邮件的地址都存到数据库再进行垃圾邮件过滤,则其性能会很低下。
此时假设通过垃圾邮件的地址创建Bloom Filter,并把Bloom Filter的位数组放到内存中,那么在进行垃圾邮件过滤时就很高效了。
在HTTP缓存server中。能够使用Bloom Filter来加快推断Url是否在代理server的缓存中。
在代理server中,首先用缓存页面的Url通过哈希算法创建一个Bloom Filter的位数组。
假设有多个代理server。还能够将自己的位数组传送给其他代理server,以加快缓存查询速度。当有HTTP请求来时。就先在代理server中查看是否有此Url的缓存,假设没有,则查看是否在其他代理server中。再没有的话才会去主server提取页面。能够看出,使用Bloom Filter查询某Url是否在缓存中很快,假设出现错误的情况则最多到主server提取页面。并且由于Bloom Filter大大降低了空间的使用,使其在网络上传输更加高速。
在web爬虫中,也可使用Bloom Filter。当web爬虫处理了一个页面时,首先会通过Bloom Filter推断这个页面是否已经处理过,假设没处理过就对其进行处理并将其加到Bloom Filter中。在web爬虫假设出现误判,则最多对同一个Url多处理几次,并不影响web爬虫的性能。通过Bloom Filter反而大大提高了web爬虫的性能。
总而言之。Bloom Filter近些年来得到了广泛的应用,通过使用Bloom Filter能够加快对海量数据的查询,提高应用的性能。
Bloom Filter算法思想
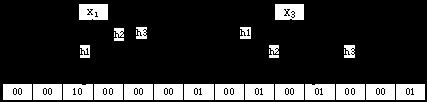
Bloom Filter算法就是对于有n个元素的集合S={x1, x2,……,xn},我们用k个哈希函数(h1,h2,……,hn),分别将S中的每一个元素映射到一个m位的位数组(bm-1bm-2……b1b0)中。该位数组在初始化时所有置为0,每当用哈希函数映射到该位时则将该位置为1。对于已经置为1的位则不在反复置1。
比如。将S={x1,x2,x3}这个集合用3个哈希函数映射到一个14位的位数组中,如图所看到的:
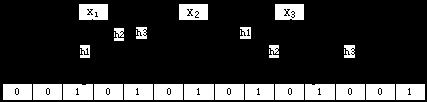
能够看出。假设要查找一个元素是否在这个集合中。则仅仅要将该元素进行k次哈希。假设其相应的位所有为1的话则说明该元素在这个集合中。否则,仅仅要有当中一位为0。则说明该元素不在这个集合中。
如图所看到的,x2在集合中,而x4不在集合中。
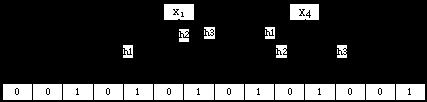
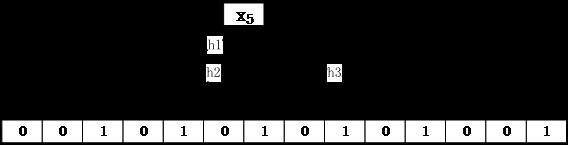
Bloom Filter会产生错误也就是由于对某个元素进行k次哈希后相应的位所有为1,因此错误地将这个元素判定为在这个集合中,但实际上这个元素并不在这个集合中。如图所看到的。x5实际并非这个集合的元素:
要将一个元素增加这个集合很easy,仅仅要将这个元素进行k次哈希后将相应的位置1即可了。
但假设要从这个集合中删除一个元素,那么使用上面的位数组就不行了。由于假设仅仅是简单地将k次哈希后相应的位置0,而其他在这个集合中的元素也可能会映射到该位,这样这个集合就出错了。
因此,对于要进行删除的情况,则应该使用Bloom Filter的变体算法:计数Bloom Filter。
计数Bloom Filter位数组的每一个元素并非仅仅有1位。而可能是2位或很多其他位(视情况而定)。如图就是使用2位位数组的样例:
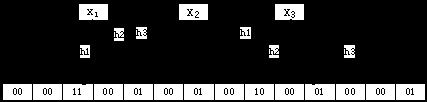
在这种情况下,假设要删除一个元素,则仅仅要将相应位的计数减1即可了。
删除了x2之后如图所看到的:
Bloom Filter算法分析
如今来分析一下标准的Bloom Filter的错误率。
刚開始时,m位的位数组初化为0,进行一次哈希并设某一位为1后位数组中某一位为0的概率为:(m-1)/m。而当对n个元素进行k次哈希后位数组中某一位为0的概率为:
p = ((m-1)/m)kn = (1 – 1/m)kn,
一个不在集合中的元素进行k次哈希后相应的位都为1。因此,Bloom Filter的错误率为:
f = (1 – (1 - 1/m)kn)k ,
由于

因此:
p = (1 – 1/m)kn = e-kn/m
即 k = -m·ln(p)/n,
f = (1 – e-kn/m)k
= exp(ln(1-e-kn/m)k)
= exp(kln(1-e-kn/m))
= exp(-m·ln(p)·ln(1-p)/n)
由于exp(x)是一个递增函数,为了使错误率f最小。那么-m·ln(p)·ln(1-p)/n就应该取最小值。
依据对称性法则能够看出。当p = 1/2时-m·ln(p)·ln(1-p)/n取得最小值,即k = -m·ln(p)/n = m·ln2 / n。
所以当哈希函数的个数k = m·ln2 / n时,能够使得错误率最小。
又由于p=1/2是对n个元素进行k次哈希后位数组中某一位为0的概率,此时位数组中0和1各占一半。即当让位数组有一半是空的时,能够使错误率最低。
以上是关于Bloom Filter 算法具体解释的主要内容,如果未能解决你的问题,请参考以下文章