布隆过滤器(Bloom Filter)
Posted cbkj-xd
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了布隆过滤器(Bloom Filter)相关的知识,希望对你有一定的参考价值。
布隆过滤器(Bloom Filter)是一种基于Hash的高效查找数据结构,它能够快速答复“某个元素是否存在”的问题。布隆过滤器只能用于添加元素与查询元素,不能够用于删除元素。
在布隆过滤器之前,使用的是基于Hash的快速查找算法。Hash可以将一个元素进行哈希,然后根据哈希值映射到数组的某一个位置。并且根据Hash算法的优劣,不同元素映射到相同位置的可能性不同。但是如果基于Hash的快速查找算法的数组大小被限制在一定的范围内,那么发生哈希冲突的概率将会变大。并且数组范围越小,冲突概率将越大。因此布隆过滤器采用了使用多个hash函数进行运算来提高空间利用率。
Bloom过滤器原理
布隆过滤器是由一个可变长度为N的二进制数组与一组数量可变M的哈希函数构成。其中,哈希函数为确定性函数,所有哈希函数的输出值都在1~N之间,与二进制数组相对应。因此,每一个元素使用布隆过滤器的哈希函数进行运算都将会得到相同的结果。
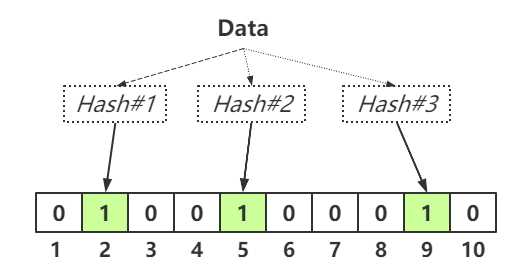
插入一个元素
假设我们需要插入一个元素到布隆过滤器中,我们需要使用不同的哈希函数进行运算生成不同的哈希值,并且根据生成的哈希值将二进制数组对应的Bit位置为1.例如插入字符串"Bloom"到过滤器中,使用三种哈希函数进行计算所得到的哈希值分别为1,3,7,那么布隆过滤器的二进制数组则会变为:
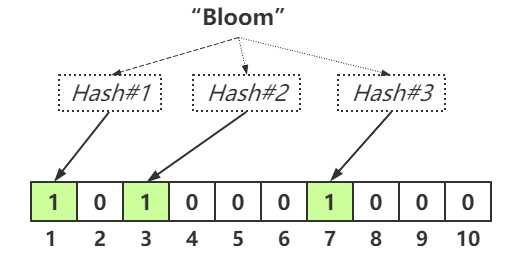
假设我们插入第二个字符串"Filter"到过滤器中,同样,我们使用相同的哈希函数进行运算,假设哈希值分别为2,4,7,那么二进制数组则会变为:
因为在插入第一个字符串时,哈希值为7的Bit位置已经被置为1,因此不需要更改,只需要将Bit位为2,4置为1即可。
查询元素
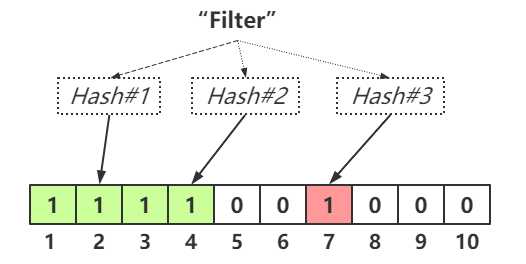
假设需要查询某个元素是否存在,只需要使用相同的哈希函数进行运算,然后与二进制数组进行Bit值匹配即可。比如,我们需要查询字符串"hash"是否存在,使用之前的哈希函数进行运算,假设输出的哈希值为4,5,7,由于Bit位为5的位置仍然为0,所以对于字符串"hash"并不存在。
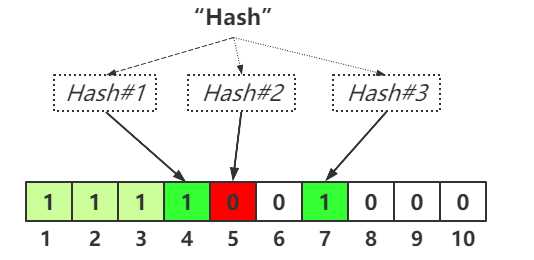
但是如果运算的哈希值为2,3,7,我们也只能说该字符串有可能存在。因为随着存储的数组越多,将会有越多的Bit位被置为1,即使某个字符串没有存储,但是有可能该字符串的哈希值与其他被存储的数据哈希值重复,仍然可能误判为该字符串存在。
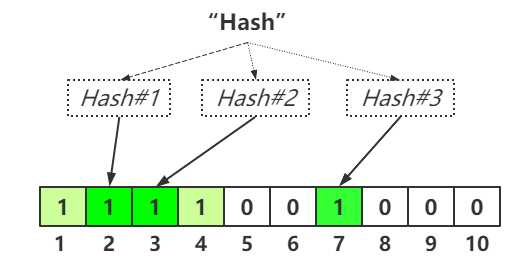
因此,对于查询某个元素,只能判定某个元素一定不存在或者有可能存在,并不能判定某个元素一定存在。
选择合适的数组长度与哈希函数数量
因此需要设置合适的数组长度与哈希函数数量。
- 数组越短则更容易所有的位置被置为1,那么可能查询任何值都会被判断可能存在,过滤的效率将大大降低。
- 数组越长则会增加过滤效率,但是过长则会耗费大量空间。
哈希函数数量也会影响过滤效率.
- 哈希函数越多则二进制位置1的次数越多,效率也会变低
- 但是数量过少的话误判率将会变高。
可以通过以下公式计算合适的数组长度与哈希函数数量:
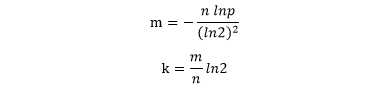
其中k为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率。
Hash与布隆过滤器
实际上,无论是 Hash,还是布隆过滤器,基本思想是一致的,
- 都是基于内容的编址。
- Hash 函数存在冲突,布隆过滤器也存在冲突。
- 都可能误报,但绝对不会漏报。
参考文献: https://github.com/yeasy/blockchain_guide/blob/master/05_crypto/bloom_filter.md
以上是关于布隆过滤器(Bloom Filter)的主要内容,如果未能解决你的问题,请参考以下文章