Softmax与Sigmoid函数的联系
Posted Shuzi_rank
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Softmax与Sigmoid函数的联系相关的知识,希望对你有一定的参考价值。
译自:http://willwolf.io/2017/04/19/deriving-the-softmax-from-first-principles/
本文的原始目标是探索softmax函数与sigmoid函数的关系。事实上,两者的关系看起来已经是遥不可及:一个是分子中有指数!一个有求和!一个分母中有1!。当然,最重要的是两个的名称不一样。
推导一下,很快就可以意识到,两者的关系可以回溯到更为泛化的条件慨率原理的建模框架(back out into a more general modeling framework motivated by the conditional probability axiom)。本文首先探索了sigmoid函数是一种特殊的softmax函数,以及各自在Gibbs distribution, factor products和概率图模型方面的理论支撑。接下来,我们继续展示概框架如何自然的扩展到canonical model class,如softmax回归,条件随机场(Conditional Random Fields),朴素贝叶斯(Naive Bayes)以及隐马尔科夫模型(Hidden Markov Model)。
目标(Our Goal)
下图是一个预测模型(predictive model),其中菱形表示接收输入,并产生输出。输入向量 ,有3种可能的输出
,有3种可能的输出 :。模型的目标在于在输入的条件下产生各种输出的概率:
:。模型的目标在于在输入的条件下产生各种输出的概率:,P(b|\\mathbf{x}),P(c|\\mathbf{x})") 。概率是位于闭区间[0,1]的一个实数值。
。概率是位于闭区间[0,1]的一个实数值。
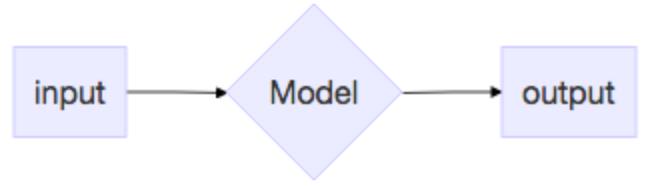
输入对输出的影响(How does the input affect the output?)
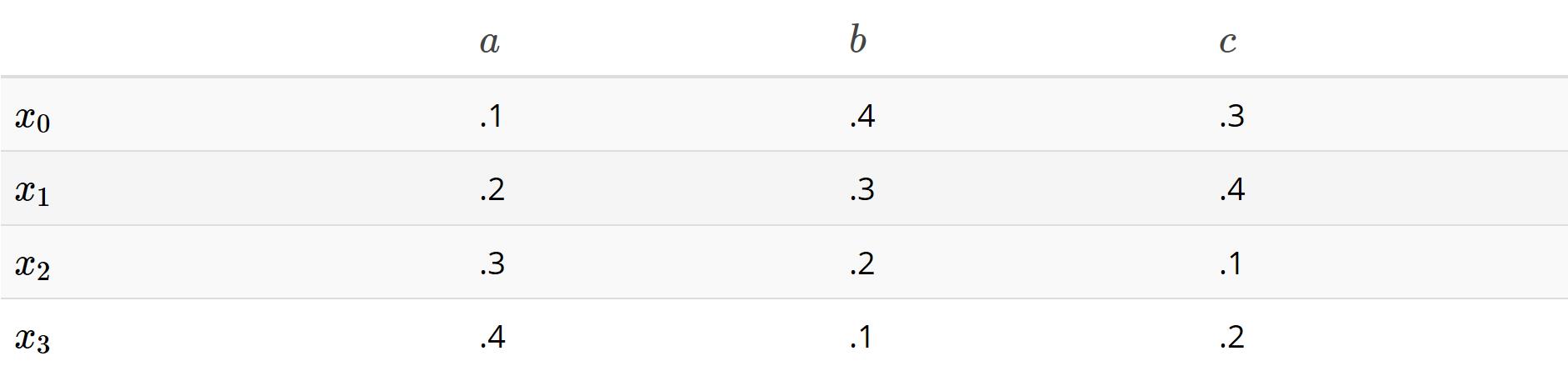
每个输入是4个数的列表(输入向量是4维),每一维度对各个可能的输出影响程度不同,这里我们称它为权重(weight)。4个输入数据乘以3个输出,代表了12个不同的权重。可能如下表所示:
生成输出(Producing an Output)
给定一个输入向量 ,我们的模型将使用上述权重来生成输出。这里假设每个输入元素的影响是加性的(The effect of each input element will be additive.)。至于原因留待后续解释。
,我们的模型将使用上述权重来生成输出。这里假设每个输入元素的影响是加性的(The effect of each input element will be additive.)。至于原因留待后续解释。

这些求和公式会对模型的输出结果产生贡献。最大的数将会胜出。例如 ,若上式得到的结果是,则我们的模型会得到结论:最大可能产生c。
,若上式得到的结果是,则我们的模型会得到结论:最大可能产生c。
转换为概率(Converting to Probabilities)
之前说过,我们的目标在于获得概率:。其中 为黑体,为了表示任意的输入向量。当给定一个具体的输入向量时,我们用花体
为黑体,为了表示任意的输入向量。当给定一个具体的输入向量时,我们用花体 表示,这样我们的目标可以更精确的表示为:
表示,这样我们的目标可以更精确的表示为:,P(b|x),P(c|x)") 。至此,我们已经获得。为了将这些值转换成一个概率,也就是闭区间[0,1]之间的一个实数值,我们只需要用这些值的和去除原始值。
。至此,我们已经获得。为了将这些值转换成一个概率,也就是闭区间[0,1]之间的一个实数值,我们只需要用这些值的和去除原始值。 &=\\frac{5}{5+7+9}&=\\frac{5}{21}\\\\ P(b|x)&=\\frac{7}{5+7+9}&=\\frac{7}{21}\\\\ P(c|x)&=\\frac{9}{5+7+9}&=\\frac{9}{21}\\\\ \\end{aligned}") 最后我们得到一个合理的概率分布,所有值的和相加为1.
最后我们得到一个合理的概率分布,所有值的和相加为1.

如果我们得到的值是负数怎么办?(What if our values are negative?)
如果其中的一个未经正则化的概率的值为负数,例如, ,那么所有的都会被破坏。该值对应的概率值也不会是一个合理的概率,
,那么所有的都会被破坏。该值对应的概率值也不会是一个合理的概率, &=\\frac{-5}{-5+7+9}&=\\frac{-5}{11}\\\\ P(b|x)&=\\frac{7}{-5+7+9}&=\\frac{7}{11}\\\\ P(c|x)&=\\frac{9}{-5+7+9}&=\\frac{9}{11}\\\\ \\end{aligned}") 因为
因为 它不能落在[0,1]闭区间之内。
它不能落在[0,1]闭区间之内。
为了保证所有没有正则化的概率值为正数,我们必须用一个函数对这些值进行处理,以保证能够产生一个严格的正实数。简单来说,就是指数函数,我们选额欧拉数e作为底。这种选择的原理有待后续解释。

这样我们正则化后的概率,也就是合法的概率,如下式所示:
&=\\frac{e^{-5}}{e^{-5}+e^7+e^9}\\\\ P(b|x)&=\\frac{e^{7}}{e^{-5}+e^7+e^9}\\\\ P(c|x)&=\\frac{e^{9}}{e^{-5}+e^7+e^9}\\\\ \\end{aligned}")
泛化表示为:=\\frac{e^{\\tilde{y}}}{\\sum_ye^{\\tilde{y}}}\\text{ for }y=a,b,c") ,也就是softmax函数。
,也就是softmax函数。
与Sigmoid函数的联系(Relationship to the sigmoid)
如果说Softmax可以得到在多于两个( )不同的输出上的一个合理的概率分布,那么sigmoid可以得到针对两种输出(
)不同的输出上的一个合理的概率分布,那么sigmoid可以得到针对两种输出( )的一个合理的概率分布。也就是说,sigmoid仅仅是softmax的一个特例。用定义来表示,假设模型只能产生两种不同的输出:
)的一个合理的概率分布。也就是说,sigmoid仅仅是softmax的一个特例。用定义来表示,假设模型只能产生两种不同的输出: 和
和 ,给定输入,我们可以写出sigmoid函数如下:
,给定输入,我们可以写出sigmoid函数如下:
=\\frac{e^{\\tilde{y}}}{\\sum_ye^{\\tilde{y}}}\\text{ for }y=p,q")
然而,值得注意的是,我们只需要计算一种结果的产生概率,因为另外一种结果的产生概率可以由概率分布的性质得到:=1-P(y=p|x)") 。接下来,我们对
。接下来,我们对") 的产生概率的表示进行扩展:
的产生概率的表示进行扩展:
=\\frac{e^{\\tilde{p}}}{e^{\\tilde{p}}+e^{\\tilde{q}}}")
然后,对该分式的分子和分母都同时除以,得到:
&=\\frac{e^{\\tilde{p}}}{e^{\\tilde{p}}+e^{\\tilde{q}}}\\\\ &=\\frac{\\frac{e^{\\tilde{p}}}{e^{\\tilde{p}}}}{\\frac{e^{\\tilde{p}}}{e^{\\tilde{p}}}+\\frac{e^{\\tilde{q}}}{e^{\\tilde{p}}}}\\\\ &=\\frac{1}{1+e^{\\tilde{q}-\\tilde{p}}}\\\\ \\end{aligned}")
最后,我们可以用该式代入求另一种结果的产生概率的式子中得到:

该等式是欠定的(underdetermined),由于等式中有多于1个的未知变量。如此说来,我们的系统可以有无穷多组解") 。因此,我们对上式进行简单的修改,直接固定其中一个值。例如:
。因此,我们对上式进行简单的修改,直接固定其中一个值。例如:
=\\frac{1}{1+e^{-\\tilde{p}}}")
这就是sigmoid函数,最终,我们得到:
为什么这些未正则化概率值是求和得到(影响是加性的)?(Why is the unnormalized probability a summation?)
我们理所当然的认为canonical线性组合的语义是 。但是为什么先求和?
。但是为什么先求和?
为了回答这个问题, 我们先复述一下我们的目标:给定输入,预测各种可能结果的产生概率,即") 。接下来,我们重新看一下条件概率的定义式:
。接下来,我们重新看一下条件概率的定义式:
=\\frac{P(A,B)}{P(A)}")
发现这个式子很难解释,我们对这个式子重新变化一下,以或则某些直觉:
=P(A)P(B|A)")
得到的信息是:同时观测到A与B的值的概率,也就是A与B的联合概率,等于观测到A的概率乘以给定A观测到B的概率。
例如,假设生一个女孩的概率是0.55,而女孩喜欢数学的概率是0.88,因此,我们得到:
=0.55*0.88=0.484")
现在,我们对原始的模型输出,利用条件概率的定义式,进行重写:
=\\frac{P(y,x)}{P(x)}=\\frac{e^{\\tilde{y}}}{\\sum_ye^{\\tilde{y}}}=\\frac{e^{(\\sum_iw_ix_i)_{\\tilde{y}}}}{\\sum_ye^{(\\sum_iw_ix_i)_{\\tilde{y}}}}")
值得注意的是,这里采用指数函数,以保证将每个未正则的概率值转换为一个严格概率值。技术上来讲,这个数字称为") ,因为可能大于1,所以并非一个严格的概率,我们需要引入另一个项到我们的等式链中:
,因为可能大于1,所以并非一个严格的概率,我们需要引入另一个项到我们的等式链中:
}{P(x)}=\\frac{\\tilde{P}(y,x)}{\\text{normalizer}}")
例如,我们的算术等式:
等式左边的项:
分子是一个严格的联合概率分布。
分母为观测到任意一个x值的概率,为1
等式右边的项:
分子是一个严格的正的未经归一化的概率值
分母是某个常数,以保证和为1。这里归一化项称为partition function。
}{\\text{normalizer}}+\\frac{\\tilde{P}(b,x)}{\\text{normalizer}}+\\frac{\\tilde{P}(c,x)}{\\text{normalizer}}")
知道了这些,我们可以对softmax等式中的分子进一步分解:
}\\\\ &=e^{(w_0x_0+w_1x_1+w_2x_2+w_3x_3)}\\\\ &=e^{(w_0x_0)}e^{(w_1x_1)}e^{(w_2x_2)}e^{(w_3x_3)}\\\\ &=\\tilde{P}(a,x)\\\\ \\end{aligned}")
Lemma:若我们的输出函数softmax函数通过指数函数得到一个多个可能结果上的合理的条件概率分布,那么下述结论肯定成立:该softmax函数的输入( )必须是原始输入元素
)必须是原始输入元素 的加权求和模型。
的加权求和模型。
上述Lemma成立的前提是我们首先接收这样的事实:=\\prod_ie^{w_ix_i}") 。从而引出来Gibbs distribution。
。从而引出来Gibbs distribution。
(二)Gibbs Distribution
Gibbs Distribution给出了一个结果集合上的未归一化的联合概率分布,类似于 ,定义如下:
,定义如下:
=\\prod_{i=1}^k\\phi_i(D_i) \\Phi=\\{\\phi_1(D_1),\\ldots,\\phi_k(D_k)\\}")
其中 定义了一个factor的集合。
定义了一个factor的集合。
Factor本质为满足下面两个条件的函数:(1)将随机变量作为输入,所有输入随机变量构成的列表称为scope;(2)针对每个可能的随机变量的组合值(即scope的叉积空间中的点),返回一个值。例如,scope为 的factor可能如下所示:
的factor可能如下所示:
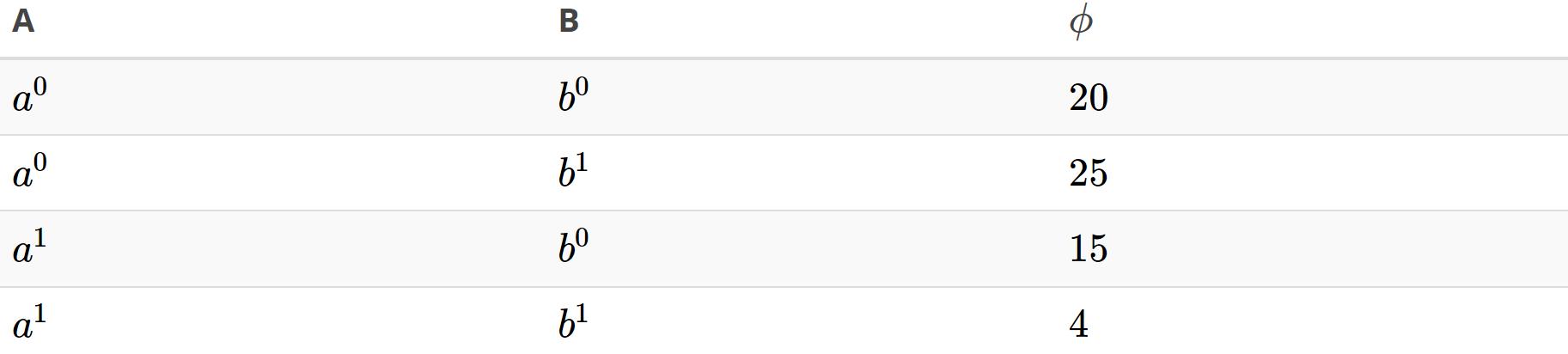
(三)Softmax regression
未完待续
以上是关于Softmax与Sigmoid函数的联系的主要内容,如果未能解决你的问题,请参考以下文章
损失函数softmax_cross_entropybinary_cross_entropysigmoid_cross_entropy之间的区别与联系