BI主要掌握啥?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了BI主要掌握啥?相关的知识,希望对你有一定的参考价值。
BI是什么 主要掌握哪些技术,如何学起、
商业智能也称作BI,是英文单词Business Intelligence的缩写。商业智能的概念最早在1996年提出。当时将商业智能定义为一类由数据仓库(或数据集市)、查询报表、数据分析、数据挖掘、数据备份和恢复等部分组成的、以帮助企业决策为目的技术及其应用。目前,商业智能通常被理解为将企业中现有的数据转化为知识,帮助企业做出明智的业务经营决策的工具。这里所谈的数据包括来自企业业务系统的订单、库存、交易账目、客户和供应商等来自企业所处行业和竞争对手的数据以及来自企业所处的其他外部环境中的各种数据。而商业智能能够辅助的业务经营决策既可以是操作层的,也可以是战术层和战略层的决策。为了将数据转化为知识,需要利用数据仓库、联机分析处理(OLAP)工具和数据挖掘等技术。因此,从技术层面上讲,商业智能不是什么新技术,它只是数据仓库、OLAP和数据挖掘等技术的综合运用。BI 是一个工厂:>> BI 的原材料是海量的数据;
>> BI 的产品是由数据加工而来的信息和知识;
>> BI 将这些产品推送给企业决策者;
>> 企业决策者利用 BI 工厂的产品做出正确的决策,促进企业的发展;
这就是 Business Intelligence,即商业智能——连接数据与决策者,变数据为价值。
BI 应用的两大类别是信息类应用 和 知识类应用,其特征如下表所示:
信息类 BI 应用:
指由原始数据加工而来的数据查询、报表图表、多维分析、数据可视化等应用,这些应 用的共同特点是:将数据转换为决策者可接受的信息,展现给决策者。
例如将银行交易数据加工为银行财务报表。
仅负责提供信息,而不会主动去分析数据。
例如,银行财务报表工具没有深入分析客户流失和银行利率之间关系的能力,而只能靠决策者结合信息,通过人的思考,得出知识。
知识类 BI 应用:
指通过数据挖掘技术和工具,将数据中隐含的关系发掘出来,利用计算机直接将数据加工为知识,展现给决策者。
会主动去数据中探查数据关联关系,发掘那些决策者人脑无法迅速发掘的隐含知识,并将其以可理解的形式呈现在决策者面前。
(3) BI 初级应用模式概览——数据查询(Querying)
数据查询是最简单的 BI 应用,属于 MIS 系统遗产,虽然出身比较老土,但是目前仍然是决策者获取信息的最直接的方法。
如今,数据查询界面已经彻底摆脱了传统 SQL 命令行,大量的下拉菜单、输入框、列表框等元素甚至是鼠标拖拽界面将后台干苦力的 SQL 语句包装成一个妖艳无比的数据获取系统,而本质仍然没有离开数据查询的几大要素:
>> 查什么
>> 从哪儿查
>> 过滤条件
>> 展示方法
目前国外比较流行的数据查询应用已经完全释放了数据查询的灵活性,如右图所示的是 Cognos ReportNet 的数据查询界面 Query Studio,允许用户通过纯浏览器界面,以鼠标拖拽操作定义数据查询要素,并以报表和图表等多种方式展现数据。
(4) BI 初级应用模式概览——报表(Reporting)
报表是国内最热衷的 BI 应用之一,这与报表在我国企事业单位中的历史地位是分不开的。我国的报表以其格式诡异、数据集中、规则古怪等特征著称于世,曾经让无数国外报表工具和 BI 工具捶胸顿足。
报表的两大要素是数据和格式,如果没有格式,则报表应用几乎等同于数据查询应用。可以说,报表就是将查询出来的数据按照指定的格式展现。
报表应用包含了报表展现和报表制作两大模块。报表展现就是让决策者看到报表,并允许决策者通过条件定义来选择报表数据,例如选择报表年度、部门、机构等等;报表制作面向报表的开发人员,其格式定义灵活性、数据映射灵活性、计算方法的丰富程度等均影响了 BI 报表应用的质量。
需要澄清一下的是,Microsoft Excel 不算是一个 BI 报表工具,因为 Excel 没有连接数据源的能力,充其量是一个 Spread Sheet。但是 Excel 强大的格式功能让报表制作人员竟折腰,乃至到后来,几乎所有 BI 厂商都提供了面向 Microsoft Excel 的插件,通过插件,Excel 可以连接到 BI 的数据源上,摇身一变为 BI 报表工具,丑小鸭变天鹅。
5) BI 高级应用模式概览——在线分析(OnLine Analytical Processing,OLAP)
OLAP ,即联机分析处理,是 BI 带来的一种全新的数据观察方式,是 BI 的核心技术之一。
我们知道,数据在数据库中是以数据表来存储的,比如某商店的销售数据存储在如下所示的一张数据表中:
销售时间
销售地点
产品
销售数量
销售金额
2004-11-1
北京
肥皂
10
342.00
2004-11-6
广州
桔子
30
123.00
2004-12-3
北京
香蕉
20
12.00
2004-12-13
上海
桔子
50
189.00
2005-1-8
北京
肥皂
10
342.00
2005-1-23
上海
牙刷
30
150.00
2005-2-4
广州
牙刷
20
100.00
决策者希望知道的往往是分布、占比、趋势之类的宏观信息,比如下列问题:
>> 北京地区的销售数量虽时间的变化趋势?
>> 哪种产品在 2005 年销售比 2004 年销售增幅最大?
>> 2004 年各产品销售额的比例分布? ……
面对这种需求,必须用 SQL 语句进行大量的 SUM 操作,每得出一个问题的结果,就需要 SQL SUM。面对上面的 7 条记录,我们可以很容易的得出结果,但是当我们面对百万级甚至亿级的记录条数时,例如移动公司通话数据,每次 SQL SUM 都需要消耗大量的时间来计算,决策者经常是在第一天提出分析需求,等到第二天才能拿到计算结果,这种分析方式是“脱机分析”,效率很低。
为了提高数据分析效率,OLAP 技术彻底打破以记录为单位的数据浏览方式,而将数据分离为“维度(Dimension)”和“度量(Measure)”:
>> 维度是观察数据的角度,例如上面示例中的“销售时间”、“销售地点”、“产品”;
>> 度量是具体考察的数量值,例如上例中的“销售数量”和“销售金额”;
这样一来,我们就可以将上面这张平版的数据列表转换为一个拥有三个维度的数据立方体( Cube ):
而探查数据的过程,就是在这个立方体中确定一个点,然后观察这个点的度量值:
当然,数据立方体并不局限于三个维度,这里采用三个维度来说明问题,只是因为通过图形可以表现出来的极限就是三个维度。
维度可以划分层次,例如时间上可以从日向上汇总为月和年,产品可以向上汇总为食品和日用品,地点可以向上汇总为华北和华南,用户可以沿着维度的层次任意向下钻取(Drill Down)和向上汇总(Roll Up):
通过这种方式,我们就可以摆脱 SQL SUM 对速度的制约,快速定位符合不同条件的细节数据,更可以迅速得到某一层次的汇总数据。OLAP 技术为决策者提供了多角度、多层次、高效率的数据探查方式,决策者的思维不再被固定的下拉菜单、查询条件所束缚,而是由决策者的思维带领数据的获取,任意组合分析角度和分析目标,这种打破传统的互动性分析和高效率使 OLAP 成为 BI 系统的核心应用。
(*) 第四喷:BI 高级应用模式 —— 数据可视化与数据挖掘
(6) BI 应用模式概览——数据可视化(Visualization)
数据可视化应用致力于将信息以尽可能多的形式展现出来,目的是使决策者通过图形这种直观的表现方式迅速获得信息中蕴藏的知识,如趋势、分布、密度等要素。 值得一提的是,以 MapInfo 公司为代表的 GIS 软件商,目前也正在努力结合 BI 应用。MapInfo 率先提出了 Location Intelligence 概念,依托于地理信息系统,展现各地区的属性值,例如人口密度,工业产值,人均医院数量等等,这种可视化应用部分与 BI 数据可视化应用重合,并形成有力补充,有时可以在一个项目中互相搭配。
上图所示的是 Cognos Visualizer 产品,这家伙用几近哗众取宠的丰富形式展现数据和信息,包含了地图、饼图、瀑布图等近五十种展现图形,并提供了二维和三维两种展现方式。所有的图形元素都是可活动的,例如用户可以通过点击地图上的某一个省,钻取到这个省各个城市的信息,这种可交互性是 BI 与普通图片生成软件的显著差异。
(7) BI 应用模式概览——数据挖掘(Data Mining)
数据挖掘是最高级的 BI 应用,因为它能代替部分人脑功能。
数据挖掘隶属于知识发现(Knowledge Discovery)在结构化数据中的特例。
数据挖掘的目的是通过计算机对大量数据进行分析,找出数据之间潜藏的规律和知识,并以可理解的方式展现给用户。
数据挖掘的三大要素是:
>> 技术和算法:目前常用的数据挖掘技术包括——
自动类别侦测(Auto Cluster Detection)
决策树(Decision Trees)
神经网络(Neural Networks)
>> 数据:由于数据挖掘是一个在已知中挖掘未知的过程,
因此需要大量数据的积累作为数据源,数据积累
量越大,数据挖掘工具就会有更多的参考点。
>> 预测模型:也就是将需要进行数据挖掘的业务逻辑由
计算机模拟出来,这也是数据挖掘的主要任务。
与信息类 BI 应用相比,以数据挖掘为代表的知识类 BI 应用目前还不成熟,但是从另一个角度来看,数据挖掘可发展的空间还很大,是今后 BI 发展的重点方向,SAS,SPSS 等知识类 BI 应用厂商形象逐渐高大,悄悄占据了新的利润增长点。
上图中是著名的 IBM Intelligent Miner 在分析客户的消费行为。它能对大量的客户数据进行分析,然后自动将客户划分为若干群体(自动类别侦测),并将每个群体的消费特征显示出来,这样决策者就能一目了然的针对不同客户的消费习惯,制定促销计划或广告计划。
上述功能如果单靠信息类 BI 应用来实现,则需要决策者根据经验进行大量的 OLAP 分析、数据查询工作,而且还不一定能发现数据中隐藏的规律。例如上述客户分类,对于一个拥有 400 万用户的银行来说,如果没有数据挖掘工具,会把人活活累死的。
(8) BI 底座——数据仓库技术(Data Warehouse)
在开始喷这个主题之前,让我们先看看数据仓库的官方定义:
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策。以上是数据仓库的官方定义。
“操作型数据库”如银行里记账系统数据库,每一次业务操作(比如你存了5元钱),都会立刻记录到这个数据库中,长此以往,满肚子积累的都是零碎的数据,这种干脏活累活还不得闲的数据库就叫“操作型数据库”,面向的是业务操作。
“数据仓库”用于决策支持,面向分析型数据处理,不同于操作型数据库;另外,数据仓库是对多个异构的数据源有效集成,集成后按照主题进行了重组,并包含历史数据,而且存放在数据仓库中的数据一般不再修改。
操作型数据库、数据仓库与数据库之间的关系,就像 C:、D: 与硬盘之间的关系一样,数据库是硬盘,操作型数据库是 C:,数据仓库是 D:,操作型数据库与数据仓库都存储在数据库里,只不过表结构的设计模式和用途不同。
那么为什么要在操作型数据库和 BI 之间加这么一层“数据仓库”呢?
一是因为操作型数据库日夜奔忙,以快速响应业务为主要目标,根本没精力伺候 BI 这边的数据需求,而且 BI 这边的数据需求通常是汇总型的,一个 select sum(xx) group by xx 就能让操作型数据库耗费大量资源,业务处理跟不上趟,麻烦就大了,比如你存了 5000 元钱,发现十分钟后钱还没到账,作何感想?一定是该银行的领导在看饼图?
二是因为企业中一般存在有多个应用,对应着多个操作型数据库,比如人力资源库、财务库、销售单据库、库存货品库等等,BI 为了提供全景的数据视图,就必须将这些分散的数据综合起来,例如为了实现一个融合销售和库存信息的 OLAP 分析,BI 工具必须能够高效的取得两个数据库中的数据,这时最高效的方法就是将数据先整合到数据仓库中,而 BI 应用统一从数据仓库里取数。
将分散的操作型数据库中的数据整合到数据仓库中是一门大学问,催生了数据整合软件的市场。这种整合并不是简单的将表叠加在一起,而是必须提取出每个操作型数据库的维度,将共同的维度设定为共用维度,然后将包含具体度量值的数据库表按照主题统一成若干张大表(术语“事实表”,Fact Tables),按照维度-度量模型建立数据仓库表结构,然后进行数据抽取转换。后续的抽取一般是在操作性数据库负载比较小的时候(如凌晨),对新数据进行增量抽取,这样数据仓库中的数据就会形成积累。
大多数 BI 应用并不要求获取实时的数据,比如决策者,只需要在每周一看到上周的周报就可以了,95% 的 BI 应用都不要 求实时性,允许数据有 1 小时至 1 个月不等的滞后,这是决策支持系统的应用特点,这个滞后区间就是数据抽取工具工作的时间。当然,BI 应用中通常还将包含极少的对实时数据的要求,这时仅需针对这些特殊需求,将 BI Querying 软件直接连接在业务数据库上就可以了,但是必须限制负载,禁止做复杂查询。
目前的数据库产品都对数据仓库提供有专门优化,例如在安装 mysql 的高版本时,安装成序会询问你是想让数据库实例作为 Transaction-Oriented ,还是 Decision Support ,前者就是操作型数据库,后者就是数据仓库(决策支持么,再振臂高呼一遍),针对这两种形式,数据库将提供针对性的优化。
(9) BI 花边
BI 的相关知识大致就是这样了,写一些花边作为结束语吧。
BI 要害:BI 无法处理非结构化数据,只能处理数字信息,但是在企业中,还存在有大量像文本、流媒体、图片等非结构化的数据,这些数据同样蕴藏有大量价值,但是面对这些数据,目前的 BI 工具无能为力。比较靠谱的是 IBM Intelligent Miner for Text,但是它在处理中文方面似乎十分薄弱。
BI 厂商和产品:
首先让我们认识一下国外大人物!数据仓库方面,有 IBM DB2,Oracle,Sybase IQ,NCR Teradata 等等;BI 应用方面,有 Cognos,Business Objects,MicroStrategy,Hyperion,IBM 等等;数据挖掘方面,有 IBM,SAS,SPSS 等等。巨无霸 Microsoft 也在 BI 领域插了一腿,推出了 SQL Server Analysis Server、Reporting Services 等 BI 相关产品抢占山头!
我们往往容量只把眼光放在国外的BI大佬们而忽略国内渐渐突起的BI新军,如今国内比较出名的BI有奥威智动的Power-BI,尚南的BlueQuery 及润乾报表等,特别值得一提的是奥威智动的Power-BI是一款标准化BI,在国内已经具有一定的市场占有率。
中国的 BI 市场发展:
时间段
国内 BI 应用情况
2002 年以前
大量 BI 软件被看作是能从多个数据源中抽取数据的报表工作,满眼全是报表。
一开始,公司的销售在推销产品时都向用户介绍:“我们是 BI 领域最强的……”效果不好;后来那些销售终于找到了窍门,上来就说:“我们什么报表都能做!”然后订单不断。
2002-2003
OLAP 的价值终于被某些慧眼发现,一些竞争压力大的企业为了提高竞争力,迫切需要从历史数据中挖掘价值,迅速发现了 OLAP 的优势,这时销售终于不用再说“我们什么报表都能做”了。但是国家机关、垄断型企业,仍旧是报表,并且以为 BI 就是报表。
2004
随着越来越多成功 BI 项目的实施,OLAP 终于得以见天日,这时国内才形成数据查询+报表展示+OLAP分析的合理 BI 应用结构。一些数据可视化的需求也时常被用户提出,在一些竞争激烈、数据量大的企业,已经出现了数据挖掘应用。
2005
信息提供已经无法满足很多企业的要求,特别是银行、通信、证券等竞争激烈、风险密集的行业,大量涌现对数据挖掘的需求,BI 应用终于形成信息+知识的整体。
BI 工具在中国遇到的难题:
* 复杂表样:中国是世界上报表最复杂的国家。中国的表样设计思想与西方不同,西方报表倾向于仅用一张报表说明一个问题,而中国的报表倾向于将尽可能多的问题集中在一张报表中,这种思路直接导致了中国报表的复杂格式和诡异风格。
* 大数据量:中国是世界上人口最多的国家。以中国移动公司为例,仅我国一个省的用户数量,就相当于欧洲一个中等国家的人口,是真正的海量数据!国外数据库、数据仓库和 BI 应用软件,都在中国经受着大数据量承载能力的考验。对于美国,可能一个客户分析应用两秒钟就能出结果,但是在中国这样的数据量下,可就不是两秒钟的问题了。
* 数据回写:中国是世界上对 BI 系统要求最奇特的国家。本来 BI 系统是以忠实再现源数据为原则,但这个原则在中国遇到了难题,许多领导都提出了数据修改需求,“报表里数字不好看,就要能改啊,而且有时候也需要调整啊,这样上级领导看着就好嘛! ”一个领导如是说。目前能满足此要求的 BI 产品,仅有 Microsoft 和 MicroStrategy 两家。微软对中国市场算是吃透了。 参考技术A 其实BI中有很多道理或原理在内,而上面的这些都只是数据的呈现方式。
请大虾能够介绍一下BI原理相关的名词,至少弄懂这些名词再看这些表象的东西不会一头雾水。
如果有高手也请给大家介绍一个学习的方向。
最起码搞明白BI,ETL,ODS,DW,DM,OLAP,OLTP这些名词的含义以及之间的关系;google一搜就明白了!
你想学哪一套啊?BI的话还是要有关系数据库基础的。如果你有这基础的话可以从微软的那套开始。我是从研究ETL入门的。
维度和量度是olap cube中的概念,具体的话可以如下理解
维度就相当于坐标系上就坐标轴,比如时间,部门;
度量就是能在报表里面反应出来的数据,比如销售额;
那么OLAP要这些维度和量度干什么呢?其实简单点来说对于不同的业务需求使用不同的维度,比如说要展现2009年第一季度公司的销售额,那么我们就需要从时间维度上分析销售额这个量度;如果要展现某个部门的销售额,则从部门这个维度上来分析销售额。当然,也有业务会是这样:展现2009年第一季度部门A的销售额,那就需要从两个维度上一起来分析了。
联机丛书很好很强大~如果你完整的安装所有的SQL SERVER组件,一切尽在其中~
ODS---ODS(Operational Data Store)是数据仓库体系结构中的一个可选部分,ODS具备数据仓库的部分特征和OLTP系统的部分特征,它是“面向主题的、集成的、当前或接近当前的、不断变化的”数据。
DW---数据仓库,英文名称为Data Warehouse,可简写为DW
DM---数据挖掘(Data Minning)
OLAP---联机分析处理,英文名称为On-Line Analysis Processing,简写为OLAP
OLTP---On-Line Transaction Processing联机事务处理系统(OLTP)
简单介绍一下 SQL Server BI 吧(我就懂这个)。
SQL Server企业版中附带了三个服务:SQL Server Integration Service, SQL Server Analysis Service,SQL Server Reporting Service。这三种服务都是为 BI 服务的,既可以单独使用,又可以配合使用。
三个服务一般都围绕一个数据仓库(Dateware House,简称DW)进行工作。
一般的数据仓库实质就是一个普通的关系数据库,只是针对 BI 的特性进行了特殊的设计。一般都是由事实表与维度表组成。例如,一个普通的电子商务网站中,每一次的购买行为形成一条事实数据,而事实数据所关联的产品(大类别、小类别、价格等等)、客户(联系方式、地理位置等)等就是维度。这种由事实表与维度表组成的数据库,能够大为方便将来的查询与分析,并且性能较高(当然,仍然取决于设计)。
SQL Server Integration Service,主要用来从原始数据库(SQL Server/Oracle/MySql/XML/Excel等都可以)中增量提取数据,经过清理、整合、计算后,加载到数据仓库中。Integration 项目可以运行在 SQL Server 代理中作为一个作业定期执行。
SQL Server Analysis Service,主要用来对数据仓库中的数据进行既定的分析。进行 Analysis 开发主要是建立多维数据模型,模型建立后其元数据可以存储到 SQL Server Analysis Service 中或者其他地方。
SQL Server Reporting Service,链接上数据源后可以生成报表(表格/矩阵/图表)。可以使用 Analysis Service 作为数据源,也可以直接使用任意数据库作为数据源。
其实这三个服务的应用很灵活,我只是描述了我应用的一个方式。
跟所有其它技术一样,摸不着头脑的时候,觉得很麻烦,不知从哪入手。而只要循序渐进的学习,要入门也很简单,一旦学会了,你就发现用这个开发统计系统,真是太简单了!而且生成的报表样式非常灵活,报表还能导出为多种常用格式(Excel,PDF,XML,Word,Tiff等等)。
BI需要的技术:
1.数据库:Oracle, DB2, SQL SERVER,最好也懂点Sybase, My SQL
包括,SQL,PLSQL,备份,恢复,调优
2.ETL: Informatica, Datastage, 手工ETL
3.报表:Cognos, BO, BIEE, Hyperion.....
4.操作系统, UNIX或者Linux,AIX, Solaris之类,SHELL脚本
5.外语,英语等,全会更好
6.html, JAVA, JS, CSS 多多益善
7.熟悉了解一些ERP系统,SAP,Sieble,Salesforce
当然了,要想深入,还是需要大量的学习和琢磨的。可以用一下亿信BI之类的BI工具会很有帮助。 参考技术B 商业智能通常被理解为将企业中现有的数据转化为知识,帮助企业做出明智的业务经营决策的工具。商务智能系统中的数据来自企业其他业务系统。例如商贸型企业,其商务智能系统数据包括业务系统的订单、库存、交易账目、客户和供应商信息等,以及企业所处行业和竞争对手的数据、其他外部环境数据。而这些数据可能来自企业的CRM、SCM等业务系统。写的太多了,楼主你不妨下个finebi试一试,蛮不错的。 参考技术C Finebi很不错,你上百度搜商业智能软件就看到了。首先我试用体会最大的就是界面风格简单明了,逻辑清晰,数据字段自动转义关联,甚至还可以从已经绑定字段的excel里面选字段。另外数据展现的很快,不用等,我这种没耐心的最怕看到“加载中”……orz。
现在啥软件都有开源,BI 呢?
英文的不适用
开源现在很流行,从系统级到应用层面,都有各类开源软件供开发者使用,比如 Linux Android Mysql PostgreSQL Hadoop Apache Tamcat Birt等,在国内都很流行
然而,BI似乎是个例外,在国内还很难找到一个使用比较广泛的的开源产品
其实国外的开源BI也很多,比如
Superset Grafana Metabase Redash,这些都是在GitHub上排名靠前的开源BI,功能和外观都做的不错,在国外的用户基础也挺很大

但是,这些东西在中文世界却很难用得起来,小方面的原因是英文文档不全,会增加学习和使用的成本,更重要的原因是BI是一个界面为主导的软件,不像其他开源代码以功能和服务为主
界面为主,那就要求页面功能布局、风格等得吻合用户的需求才行,会涉及到很多需要改造的地方,基本每个页面都得改,但语言不同,修改的难度就会倍增
所以,虽然国外的开源BI功能外观都不差,还免费,在国外也比较流行,但国内大部分的软件开发商和用户还是宁愿去选择收费的商业BI
更详细的国外开源BI评测,可以参考:
中文的有润乾
国外的不合用,国内的有没有呢
国内的开源BI很少,网上搜到的基本都是商用BI放出的烟雾弹广告,点进去看半天问半天,才知道根本没有开源这么一回事,都得收费,还挺贵,好几十万寻找开源的过程,太艰难了
中文世界中功能完备的开源BI,也就是润乾一家,以下这些模块全部开源

润乾这个开源BI的功能怎么样?直接从它的发布学习材料来看:
- BI 前端实践 0:基于润乾报表的开源 BI
- BI 前端实践 1:文件数据源做多维分析
- BI 前端实践 2:SQL 数据源做多维分析
- BI 前端实践 3:较大数据量的 SQL 多维分析
- BI 前端实践 4:自定义多维分析界面
- BI 前端实践 5:自定义多维分析显示风格
- BI 前端实践 6:自定义模板展示多维分析结果
- BI 前端实践 7:预定义语义层改善 SQL 做多维分析
- BI 前端实践 8:关联查询语言──DQL
- BI 前端实践 9:由 DQL 支持的关联多维分析
- BI 前端实践 10:基于语义层的权限控制
- BI 前端实践 11:多维分析使用有层次的维度
- BI 前端实践 12:隐身的汇总表提速多维分析
- BI 前端实践 13:语义层把多库联合起来做多维分析
- BI 前端实践 14:探究润乾多维分析的开源代码
- BI 前端实践 15:基于语义层的自助查询
- BI 前端实践 16:BI 管理系统
- BI 前端实践 17:DBD 实践
- BI 前端实践 18: 集成 DBD 功能及二次开发
- 通用查询控件使用方法
这些是润乾BI前端功能实践案例,选自 润乾报表开源 BI 学习资料
只是这个系列实践系列就有20篇之多,不能不说润乾开源BI的功能确实相当丰富。从连接数据源,到开始多维分析,到自定义修改页面,到语义层,到多表多库关联JOIN,到权限控制,到源码分析,到敏捷看板DBD,到通用查询,覆盖了BI的方方面面,有了这些实践案例,学习和改造也变得容易了,都有实际示例可以参考
我们从这些实践说明里挑一些大家比较关注的功能,重点看下
多维分析
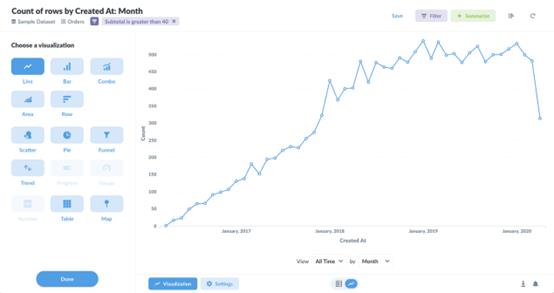
多维分析能力,是BI软件最基础的看家本领,润乾BI不仅可以做基础的切片,钻取,旋转等操作,还可以做更高级的跨行组运算,如同比环比排名,等

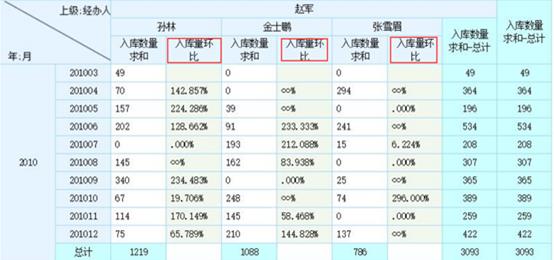
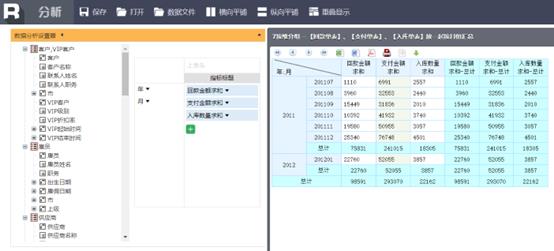
润乾BI的跨行组运算是可以选择两个统计层次(比如在年内按月累计),而很多BI产品只能有一个层次的跨行组运算,甚至根本就不支持。
数据来源
润乾BI支持各类型的数据来源,给一句SQL能分析,给个Excel也可以,来个程序算出来的结果集也行,给常见的和不常见的各类数据库更可以,避免了分析只能针对特定的数据源,给个其他的就分析不了的窘境
一句SQL
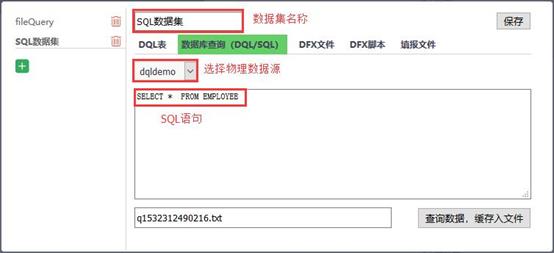
一个Excel
JavaAPI和WebService

语义权限
除了能分析上面的临时性、即时性数据外,润乾BI还有语义层可以定义使用频度较高的数据源,设置中文名称,做JOIN,增加指标等,让分析更轻松方便
还可以设置权限,可以精细的控制哪些人可以看到哪个表,哪个字段的数据
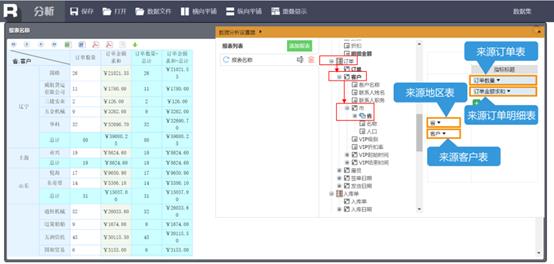
关联查询
这是润乾BI独有的功能,涉及JOIN的关联查询就连卖的很贵的商业BI一般都处理的不好
润乾的DQL引擎可以让多表关联查询不再错、不再晕,根据拖拽实时关联查询数据,轻松实现关联分析
至于 BI 软件大都解决不好关联分析的的难题,详情可以参考:
敏捷看板
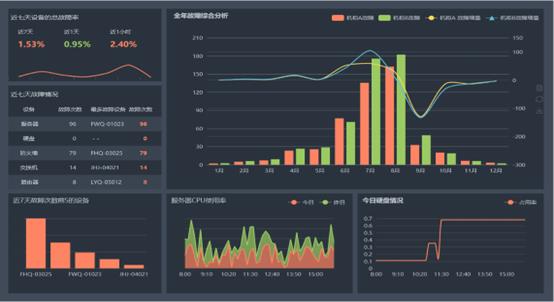
业务人员可以在分析页面快速制作DashBaord,敏捷看板,生成可视化报告
通用查询

业务人员可以灵活的在页面上拖拽设置查询条件,分组汇总等
系统平台
润乾BI虽然是开源的,可以被集成的软件,但他同时也提供了全面的系统管理功能,人员机构管理、资源管理、权限控制、任务调度等都有,没有系统的用户可以拿来直接用,改改就是自己的系统,有系统的可以忽略这些,还是只集成BI部分就可以
除了这些重点功能外,润乾BI还有很多其他细微独特的功能,篇幅原因我们就不一一列举了,从上面提到的这些重点功能已经可以看出,润乾的BI,功能已经非常齐全,还有其他商用BI没有的特色和亮点,相对于国外的开源BI,更具有中文页面好改造的优势,完整的文档和实践示例也更便于用户使用和学习
总结
一直以来国内的同学想找一个方便好用的开源BI都不是一件易事,国外的页面不好修改,国内的基本都收费,现在有了润乾开源BI了,同学们可以去试一下了,润乾是做报表起家,是报表行业的领头羊,报表功能好,BI功能也不差,还天然弥补了BI缺少报表能力的短板
润乾报表的新老用户,遍布各行各业,已经有很多在用润乾的开源BI了,因为报表自带BI,直接集成到系统里,改改页面,就成了自己系统的BI模块了
润乾报表资料
以上是关于BI主要掌握啥?的主要内容,如果未能解决你的问题,请参考以下文章