Spark MLlib数据类型
Posted dabokele
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark MLlib数据类型相关的知识,希望对你有一定的参考价值。
MLlib支持几种数据类型:本地向量(local vectors),和存储在本地或者基于RDD的分布式矩阵(matrices)。底层的线性代数转换操作是基于Breeze和jblas实现的。在MLlib中有监督学习算法使用的训练样本数据类型被称为“带标签的点(labeled point)”。
一、本地向量(Local Vector)
一个本地向量是由从0开始的整型下标和double型数值组成的,存储在单机节点上。MLlib支持两种类型的本地向量:密集(dense)的和稀疏(sparse)的。密集向量用一个double数组来存储值。而稀疏向量由两个并列的数组,下标和值组成。例如,一个向量(1.0, 0.0, 3.0)可以由密集的数组[1.0, 0.0, 3.0]表示,或者可以由(3, [0, 2], [1.0, 3.0])表示,其中3是指向量大小。接下来第0个元素是1.0,第2个元素是3.0。由此可看出,0.0在稀疏向量中可省略不写。
本地向量的基本类型是Vector,并且有两个子类型:DenseVector, SparseVector。建议使用Vectors中的工厂方法来创建本地向量。
import org.apache.spark.mllib.linalg.{Vector, Vectors}
//创建一个密集向量(1.0, 0.0, 3.0)
val dv: Vector = Vectors.dense(1.0, 0.0, 3.0)
//通过设置非零元素的下标和值来创建一个稀疏向量(1.0, 0.0, 3.0)
val sv1: Vector = Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0))
//通过另一种方式创建稀疏向量,采用下标,值对形式
val sv2: Vector = Vectors.sparse(3, Seq((0, 1.0),(2, 3.0)))注意:Scala默认imports scala.collection.immutable.Vector,所以一定要记得手动引入MLlib的Vector类。
二、带标签的点(Labeled point)
带标签的点实质上由本地向量(既可以是密集向量也可以是稀疏向量) 和类标签(label/response)组成。在MLlib中,Labeled point一般用在有监督学习算法中。label的存储类型为double,所以Labeled point既可用在回归分析算法又可用在分类算法(regression and classification)中。对于二分型分类算法,label应该用0和1表示。对多分型分类算法,标签可以用从0开始的下标表示:0,1,2……
MLlib中Labeled point用LabeledPoint类表示
import org.apache.spark.mllib.linglg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
// 创建一个标签为1,数据为密集型向量构成的带标签点
val pos = LabeledPoint(1.0, Vectors.dense(1.0, 0.0, 3.0))
// 创建一个标签为0,数据为稀疏型向量构成的带标签点
val neg = LabeledPoint(0.0, Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0)))1、稀疏数据(sparse data)
使用稀疏数据是很普遍的现象。MLlib支持读取以LIBSVM格式存储的训练数据,LIBSVM是LIBSVM和LIBLINEAR默认的格式。它是一种text格式的数据,里面的每一行代表一个含类标签的稀疏向量,格式如下:
label index1:value1 index2:value2 .....LIBSVM中index是从1开始的,在加载完成后索引被转换成从0开始。
用MLUtins.loadLibSVMFile从LIBSVM格式中读取训练数据,
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.rdd.RDD
val examples:RDD[LabeledPoint] = MLUtils.loadLibSVMFile(sc, data/mllib/sample_libsvm_data.txt") $SPARK_HOME/data/mllib/sample_libSVM_data.txt中数据格式如下,

红色方框中的0和1代表标签类型。
三、本地矩阵(Local matrix)
本地矩阵由下标和double型的数值组成,其中下标是由整型数据表示行和列,保存在单个机器中。MLlib支持稀疏矩阵和密集矩阵,密集矩阵的值存在一个double数组中,一列列的进行存储。如下所示为一个密集矩阵
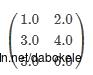
表示一个size为(3,2)的密集矩阵,其值存在一个一维数组中,数组值为[1.0, 3.0, 5.0, 2.0, 4.0, 6.0]。稀疏矩阵的非零元素值都保存在压缩的稀疏列(Compressed Sparse Column,CSC)中,按列优先的顺序存储。
本地矩阵基本类型为Matrix,有两个子类型:DenseMatrix和SparseMatrix。推荐使用Matrices的工厂方法来生成本地矩阵。必须牢记,MLlib中的本地矩阵数值是按列的顺序进行存储的。
import org.apache.spark.mllib.linalg.{Matrix,Matrices}
// 创建一个密集矩阵((1.0, 2.0), (3.0, 4.0), (5.0, 6.0))
val dm:Matrix = Matrices.dense(3,2, Array(1.0, 3.0, 5.0, 2.0, 4.0, 6.0))
// 创建一个稀疏矩阵((9.0, 0.0), (0.0, 8.0), (0.0, 6.0))
val sm:Matrix = Matrices.sparse(3, 2, Array(0, 1, 3), Array(0, 2, 1), Array(9, 6, 8)) 注:稀疏矩阵解释,首先指定矩阵是3行2列,Array(0, 1, 3)是指,第0个非零元素在第一列,第一第二个非零元素在第二列。Array(0, 2, 1)是指,第一个非零元素在第0行,第二个非零元素在第2行,第三个非零元素在第1行。此处设计比较好,假设100个元素分两列,不需要把每个元素所在列都标出来,只需要记录3个数字即可。Array(9, 6, 8)表示按顺序存储非零元素.
四、分布式矩阵(Distributed Matrix)
一个分布式矩阵也是由下标和double型的值组成,不过分布式矩阵的下标不是Int型,而是long型,数据分布式保存在一个或多个RDD中。选择正确的格式来保存海量和分布式的矩阵是非常重要的。将分布式矩阵转换成不同的格式需要一个全局的shuffle(global shuffle),而全局shuffle的代价会非常高。到目前为止,Spark MLlib中已经实现了三种分布式矩阵。
最基本的分布式矩阵是RowMatrix,它是一个行式的分布式矩阵,没有行索引。比如一系列特征向量的集合。RowMatrix由一个RDD代表所有的行,每一行是一个本地向量。假设一个RowMatrix的列数不是特别巨大,那么一个简单的本地向量能够与driver进行联系,并且数据可以在单个节点上保存或使用。IndexedRowMatrix与RowMatrix类似但是有行索引,行索引可以用来区分行并且进行连接等操作。CoordinateMatrix是一个以协同列表(coordinate list)格式存储数据的分布式矩阵,数据以RDD形式存储。
注意:因为我们需要缓存矩阵的大小,所以分布式矩阵的RDDs格式是需要确定的,使用非确定RDDs的话会报错。
1、RowMatrix
RowMatrix它是一个行式的分布式矩阵,没有行索引。比如一系列特征向量的集合。RowMatrix由一个RDD代表所有的行,每一行是一个本地向量。因为每一行代表一个本地向量,所以它的列数被限制在Integer.max的范围内,在实际应用中不会太大。
一个RowMatrix可以由一个RDD[Vector]的实例创建。因此我们可以计算统计信息或者进行分解。QR分解(QR decomposition)是A=QR,其中Q是一个矩阵,R是一个上三角矩阵。对sigular value decomposition(SVD和principal component analysis(PCA),可以去参考降维的部分。
import org.apache.spark.mllib.linalg.Vector
import org.apache.spark.mllib.linalg.distributed.RowMatrix
val rows:RDD[Vector] = .... //一个本地向量的RDD
// 从RDD[Vector]创建一个RowMatrix
val mat: RowMatrix = new RowMatrix(rows)
// 获取RowMatrix的维度
val m = mat.numRows()
val n = mat.numCols()
// QR降维
val qrResult = mat.takkSkinnyQR(true)2、IndexedRowMatrix
IndexedRowMatrix与RowMatrix类似,但是它有行索引。由一个行索引RDD表示,索引每一行由一个long型行索引和一个本地向量组成。
一个IndexedRowMatrix可以由RDD[IndexedRow]的实例来生成,IndexedRow是一个(Long, Vector)的封装。去掉行索引,IndexedRowMatrix能够转换成RowMatrix。
import org.apache.spark.mllib.linalg.distributed.{IndexedRow, IndexedRowMatrix,RowMatrix}
val rows: RDD[IndexedRow] = ... //一个indexed rows的RDD
// 从RDD[IndexedRow]创建一个IndexedRowMatrix
val mat:IndexedMatrix = new IndexedRowMatrix(rows)
// 获取维度
val m = mat.numRows()
val n = mat.numCols()
// 去掉行索引,转换成RowMatrix
val rowMat:RowMatrix = mat.toRowMatrix()3、CoordinateMatrix
CoordinateMatrix是一个分布式矩阵,其实体集合是一个RDD,每一个是一个三元组(i:Long, j:Long, value:Double)。其中i是行索引,j是列索引,value是实体的值。当矩阵的维度很大并且是稀疏矩阵时,才使用CoordinateMatrix。
一个CoordinateMatrix可以通过一个RDD[MatrixEntry]的实例来创建,MatrixEntry是一个(Long, Long, Double)的封装。CoordinateMatrix可以通过调用toIndexedRowMatrix转换成一个IndexedRowMatrix。CoordinateMatrix的其他降维方法暂时还不支持(Spark-1.6.2)。
import org.apache.spark.mllib.linalg.distributed.{CoordinateMatrix,MatrixEntry}
val entries:RDD[MatrixEntry] = ... //一个matrix entries的RDD
// 由RDD[MatrixEntry]创建一个CoordinateMatrix
val mat:CoordinateMatrix = new CoordinateMatrix(entries)
// 获取矩阵的维度
va l m = mat.numRows()
val n = mat.numCols()
// 调用toIndexedRowMatrix转换成IndexedRowMatrix,它的行都是稀疏向量
vavl indexedRowMatrix = mat.toIndexedRowMatrix()4、BlockMatrix
一个BlockMatrix是一个分布式的矩阵,由一个MatrixBlocks的RDD组成。MatrixBlock是一个三元组((Int, Int), Matrix),其中(Int, Int)是block的索引,Matrix是一个在指定位置上的维度为rowsPerBlock * colsPerBlock的子矩阵。BlockMatrix支持与另一个BlockMatrix对象的add和multiply操作。BlockMatrix提供了一个帮助方法validate,这个方法可以用于检测该`BlockMatrix·是否正确。
可以通过IndexedRowMatrix或者CoordinateMatrix调用toBlockMatrix快速得到BlockMatrix对象。默认情况下toBlockMatrix方法会得到一个1024 x 1024的BlockMatrix。使用时可以通过手动传递维度值来设置维度,toBlockMatrix(rowsPerBlock, colsPerBlock)。
import org.apache.spark.mllib.linalg.distributed.{BlockMatrix, CoordinateMatrix, MatrixEntry}
val entries: RDD[MatrixEntry] = ... // an RDD of (i, j, v) matrix entries
// 从RDD[MatrixEntry]生成一个CoordinateMatrix
val coordMat: CoordinateMatrix = new CoordinateMatrix(entries)
// 将CoordinateMatrix转换成BlockMatrix
val matA: BlockMatrix = coordMat.toBlockMatrix().cache()
// 检测BlockMatrix格式是否正确,错误的话会抛出异常,正确的话无其他影响
matA.validate()
// 计算A^T * A.
val ata = matA.transpose.multiply(matA)以上是关于Spark MLlib数据类型的主要内容,如果未能解决你的问题,请参考以下文章