学习笔记Spark—— Spark MLlib应用—— Spark MLlib应用
Posted 别呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习笔记Spark—— Spark MLlib应用—— Spark MLlib应用相关的知识,希望对你有一定的参考价值。
三、Spark MLlib应用
3.1、Spark ML线性模型
-
数据准备
基于Spark ML的线性模型需要DataFrame类型的模型数据,DataFrame需要包含:一列标签列,一列由多个特征合并得到的特征列 -
训练模型

-
模型应用


-
模型评估

任务1:
某专门面向年轻人制作肖像的公司计划在国内再开设几家分店,收集了目前已开设的分店的销售数据(Y,万元)及分店所在城市的16岁以下人数(X1,万人)、人均可支配收入(X2,元)
要求:构建线性回归模型,分析销售数据与16岁以下人数(X1,万人)、人均可支配收入(X2,元)的关系
数据 regressiondata.txt:

上传到hdfs:

处理线性回归模型数据:

构建线性回归模型:

预测:
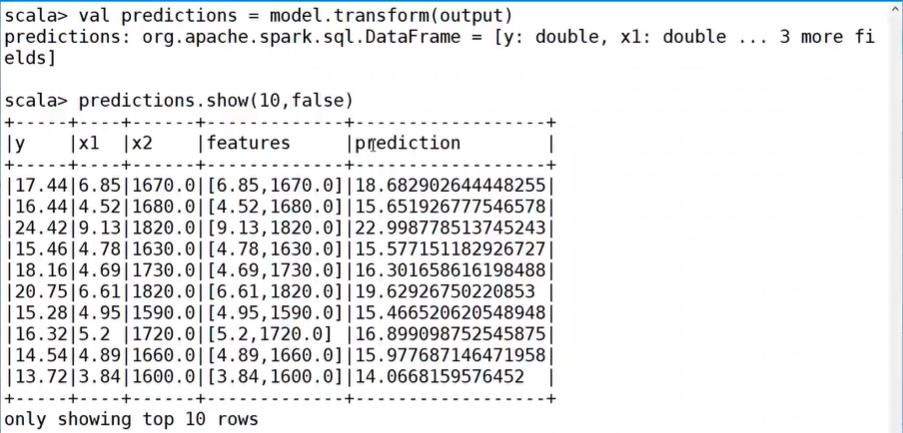
均方误差:

3.2、协同过滤简介
- 协同过滤推荐(Collaborative Filtering recommendation)是一项在信息过滤和信息系统中很受欢迎的技术。与传统的基于内容过滤直接分析内容进行推荐不同,协同过滤分析用户兴趣,在用户群中找到指定用户的相似(兴趣)用户,综合这些相似用户对某一信息的评价,形成系统对该指定用户对此信息的喜好程度预测。
- 协同过滤一般分为基于用户的协同过滤和基于物品的协同过滤。基于用户的协同过滤是依据用户之间的相似性,将相似性高的用户对于某种物品的喜好进行计算,从而推测指定用户对于该物品的喜好
3.2.1、基于用户的协同过滤
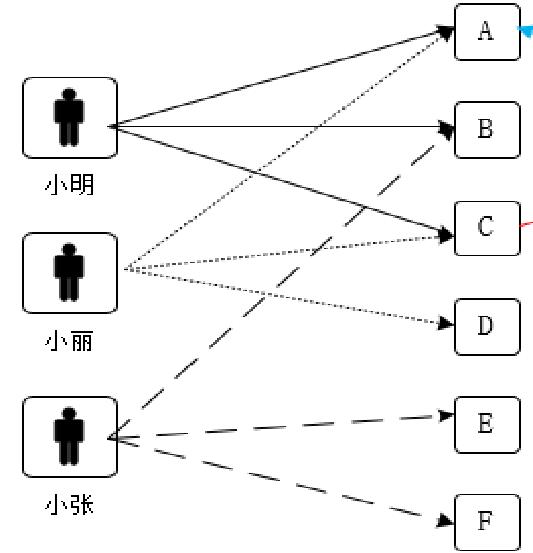
小明和小丽都喜欢A、C,说明小明小丽兴趣比较相似,可把小明喜欢的B推荐给小丽,小丽喜欢的D推荐给小明
3.2.2、基于物品的协同过滤
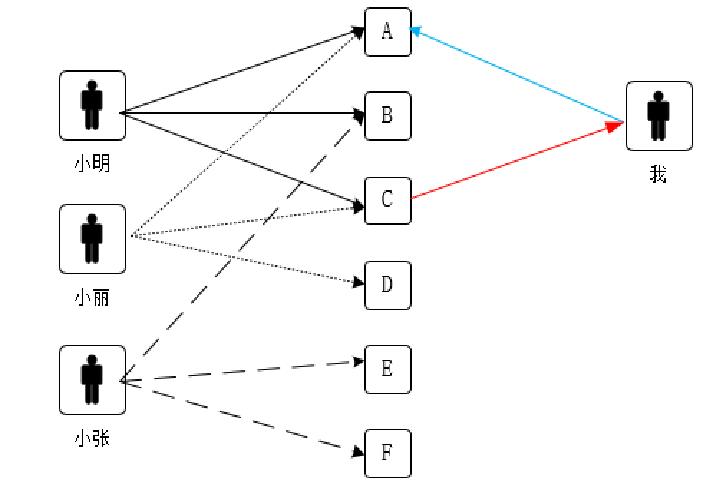
小明喜欢A、B和C,小丽喜欢A、C和D,小张喜欢B、E和F。观察三人拥有的物品,可以知道拥有A的也拥有C,可知A、C的关联程度很高,即A、C相似度很高。如果此时指定用户已经拥有A,显然应该把C推荐给该用户最合适。
3.2.3、基于ALS的协同过滤
从协同过滤的分类来说,ALS算法属于User-Item CF,也叫做混合CF。它同时考虑了User和Item两个方面。
ALS是交替最小二乘的简称。在机器学习中,ALS特指使用交替最小二乘求解的一个协同过滤算法。它通过观察到的所有用户给产品的打分,来推断每个用户的喜好并向用户推荐适合的产品。
ALS算法不像基于用户或者基于物品的协同过滤算法一样,通过计算相似度来进行评分预测和推荐,而是通过矩阵分解的方法来进行预测用户对物品的评分。
3.3、Spark ML ALS
官网:http://spark.apache.org/docs/latest/ml-features.html#vectorindexer
- 数据准备
需要3个列,用户列、物品列、评分列 - 模型构建

- 模型应用


- 模型评估


任务2:
现有一份数据,记录了用户对电影的评分,如下所示,包括用户id、电影id、评分。
要求:根据用户的电影评分记录,通过协同过滤算法计算用户之间的相似度,为用户进行电影推荐。
数据 sample_movielens_data.txt:

上传到hdfs:
构建ALS算法进行电影推荐:
预测:

均方误差:

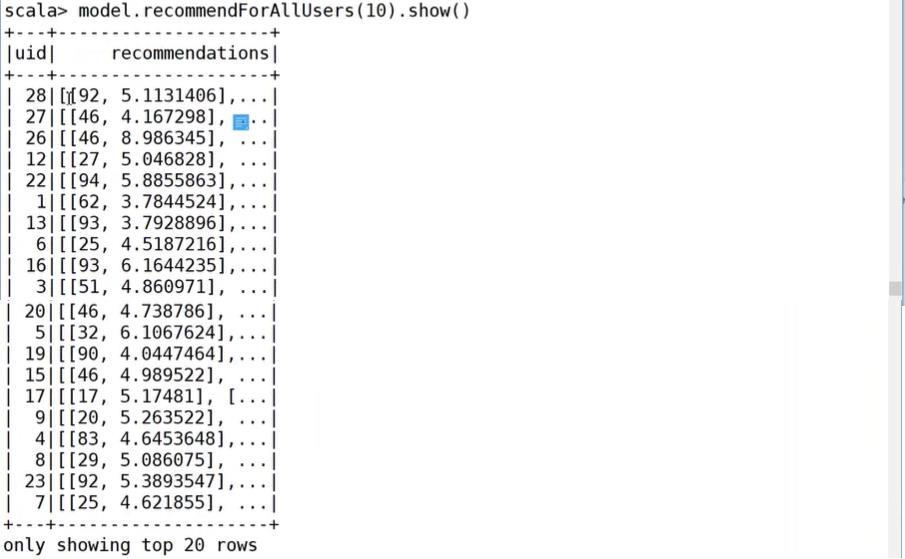
给参与用户推荐:
给参与模型构建的商品推荐相似商品:

3.4、在IDEA实现ALS
在IDEA创建Spark工程见我博客:学习笔记Spark(五)—— 配置Spark IDEA开发环境
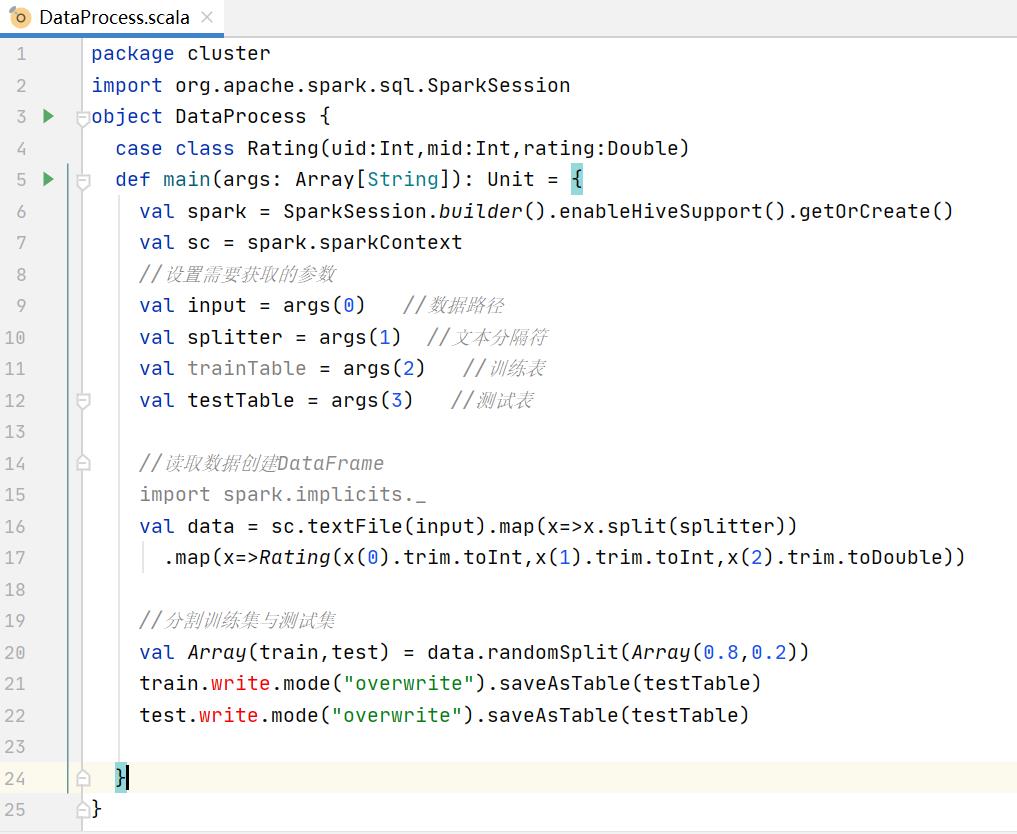
3.4.1、实现ALS数据处理过程
3.4.2、实现ALS模型构建过程

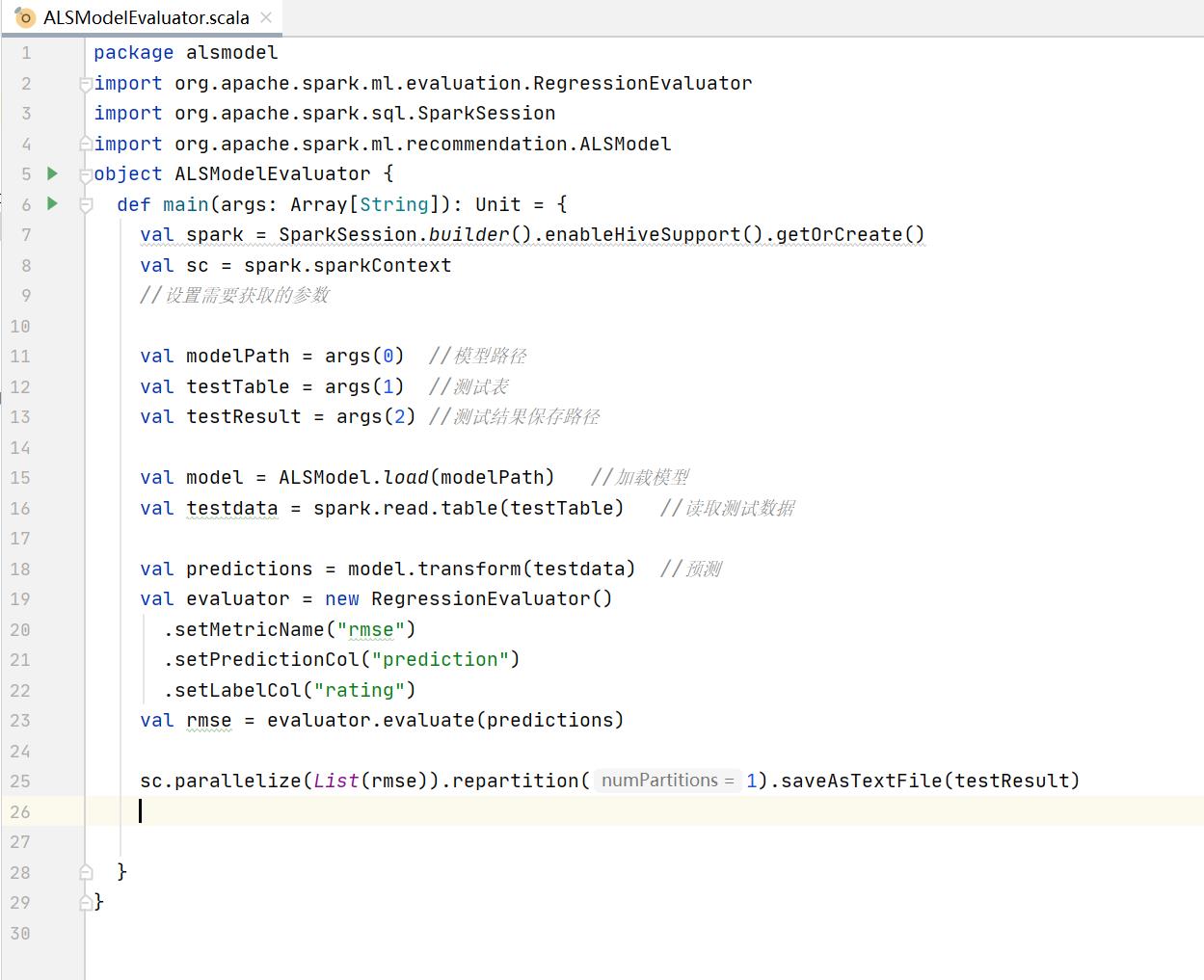
3.4.3、实现ALS预测与评估过程
3.4.4、实现ALS模型推荐过程
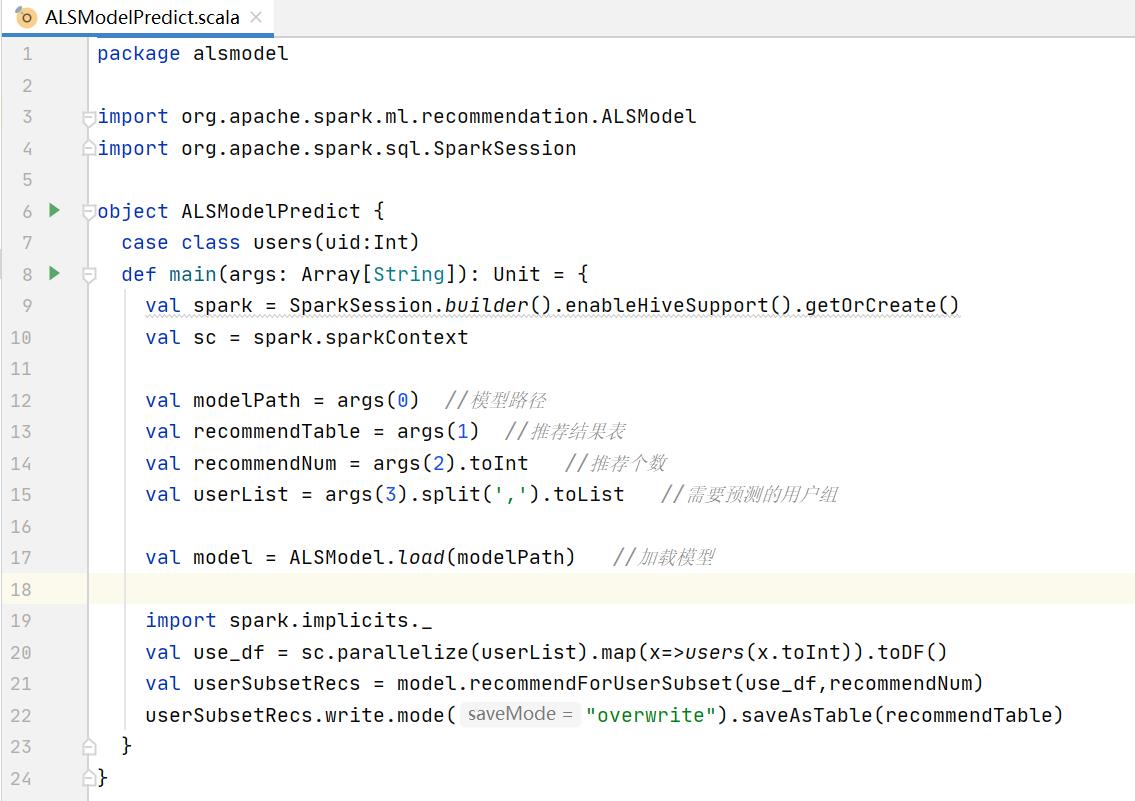
3.4.5、提交ALS电影推荐模型到集群
① 将程序打包成jar包,并上传到linux的/opt目录下

② spark-submit提交到集群



推荐结果记录:

以上是关于学习笔记Spark—— Spark MLlib应用—— Spark MLlib应用的主要内容,如果未能解决你的问题,请参考以下文章