Mooc爬虫05-scrapy框架
Posted weihuchao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mooc爬虫05-scrapy框架相关的知识,希望对你有一定的参考价值。
1 scrapy框架的介绍
安装
pip install scrapy
查看是否安装完成
scrapy ‐h
scrapy框架是实现爬虫功能的一个软件结构和功能组件集合
scrapy爬虫框架的结构
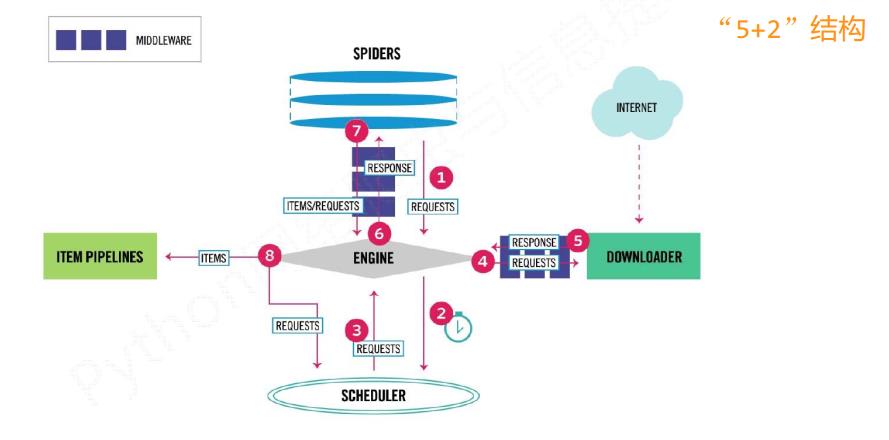
这5+2的结构, 就是scrapy框架
主要有三条主要的数据流路径
第一条路径
1) Engine通过中间件获得了Spiders发送的请求, 这个请求叫做requests, 相当于是一个url
2) Engine再转发给scheduler, scheduler主要负责对爬取请求进行调度
第二条路径
3) 从Scheduler获得下一个需要爬取的请求, 这是一个真实的请求
4) Engine获得这个请求之后, 通过中间件, 将请求给 Downloader模块
5) Downloader爬取请求中相关的网页, 并将爬取的内容封装成一个对象, 这个对象叫response(响应)
6) Engine再通过中间件将response返回给Spiders
第三条路径
7) Spiders处理从Downloader获得的响应, 处理之后会产生两个数据类型, 一个是items(爬取项), 另一个是新的requests
8) Engine接受到这两数据之后, 将items发送给Item Pipelines, 将requests发送给Scheduler进行调度
整个框架的入口是Spiders, 出口是Item Pipelines
其中Engine, Scheduler, 和Downloader是已经写好的, 不需要实现
Spiders和Item Pipelines是需要编写的, 但是里面有既定的代码框架, 所以情况是要对某东西进行修改, 这种情况一般叫配置
2 框架解析
Engine
是整个框架的核心
不需要修改
控制所有模块之间的数据流
根据条件触发事件
Downloader
根据请求下载网页
不需要修改
Scheduler
对所有请求进行调度管理
Downloader Middleware
在Engine和Downloader之间的中间件
实现用户可配置的控制, 一般是对requests或者responses进行处理和修改的时候使用
实现 修改, 丢弃, 新增请求或相应
用户可以编写配置代码
Spiders
解析Downloader返回的相应
产生爬取项
产生额外的爬取请求
需要用户编写, 是用户最主要编写的部分
Item Pipelines
是以流水线的形式进行处理生成的爬起项
由一组操作顺序组成, 类似流水线, 每个操作是一个Item Pipelines
可能包含的操作有: 清理, 检验, 和查重爬取项中的html数据, 将数据存储到数据库中
完全由用户编写
Spider Middleware
在Spiders和Engine之间的中间件
对象求和爬取项的再处理
修改, 丢弃, 新增请求或者爬取项
中间件主要是对中间的数据流进行一些操作
3 scrapy和requests的区别
相同点:
都可以进行页面的爬取
可用性都比较好
两者都没有处理js, 提交表单, 应对验证码的功能(但是可以扩展)
不同点
scrapy是网站级别的爬虫, 是一个框架, 并发性好, 性能较高, 重点在于爬虫结构
requests是页面级别的爬虫, 是一个库, 并发性不足, 性能不好, 重点在于页面下载, 定制灵活
4 常用命令
命令格式
scrapy 命令 命令项 命令参数
startproject 创建一个新工程
genspider 创建一个爬虫
settings 获取爬虫配置信息
crawl 运行一个爬虫
list 列出工程中所有爬虫
shell 启动URL调试命令行
scrapy主要是一个后台的爬虫框架
之所以提供命令行的方式是因为 命令行的方式更加容易自动化, 适合脚本控制
本质上, scrapy是给程序员使用的, 使用命令行的方式更加合适
5 Scrapy的基本使用
5.1 建立一个工程
执行命令
scrapy startproject 工程名字
这样就会在当前目录下, 创建一个以工程名字命名的文件夹
在这个目录下有:
scrapy.cfg -这是部署Scrapy爬虫的配置文件, 将爬虫放在特定的服务器上, 并且配置好相关的操作接口, 在本地上使用不需要配置
PythonDemo1文件夹 -这是Scrapy框架对应的所有文件所在的目录, 这个名字和工程名字一致
在文件夹中对应有:
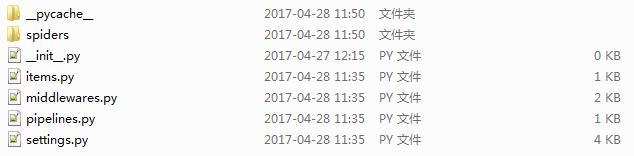
__pycache__文件夹 -这是缓存文件夹
spiders文件夹 -这是Spiders代码模块目录, 存放工程建立的所有爬虫
__init__.py -这是初始化脚本, 用户不需要编写
items.py -这是Items代码模板, 需要继承类, 一般不需要编写
middelwares.py -这是Middleware代码模块, 需要继承类, 定制的时候需要编写
pipelines.py -这是Pipelines代码模板, 需要继承类
setting.py -这是Scrapy爬虫的配置文件
在spiders文件夹下:

5.2 建立一个爬虫
进入工程文件目录下
输入命令建立一个爬虫
Scrapy genspider 爬虫名字 爬取的地址
建立之后再spiders文件夹中就会多出一个以爬虫名字命名的py文件
代码如下
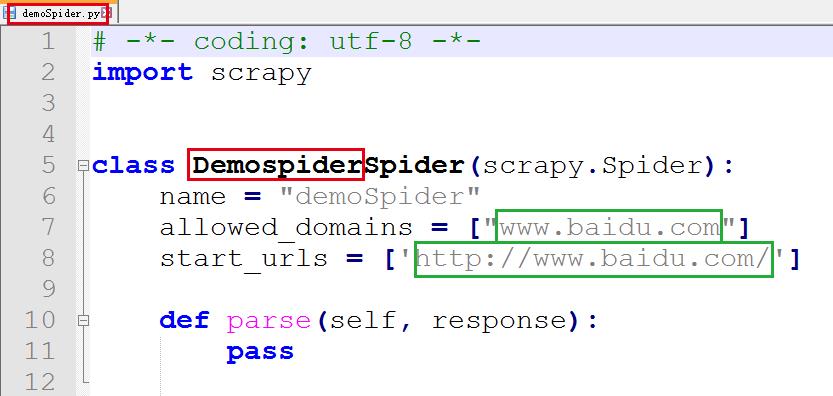
其中:
class类名是 文件名字+Spider
必须继承 Scrapy.Spider
name -是爬虫的名字
allowed_domains -是允许的域名, 只能在该域名下爬取网页信息
start_urls -爬取页面的初始页面
parse()方式 -用于处理相应, 解析内容形成字典, 发现新的URL爬取请求, 类似于步骤7的处理
对于
start_urls = [\'http://www.naidu.com\']
这其实是一个简单的写法, 完整的写法是一个生成器, 代码如下
def start_requests(self):
urls = [
\'heep://www.baidu.com\'
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
5.3 配置爬虫
可以实现一个基本的功能, 将爬取的页面保存为一个文件
处理demoSpider.py文件如下
import scrapy
class DemospiderSpider(scrapy.Spider):
name = "demoSpider"
#allowed_domains = ["www.baidu.com"]
start_urls = [\'http://www.baidu.com/\']
def parse(self, response):
fname = response.url.split(\'/\')[-1]
with open(fname, "wb") as f:
f.write(response.body)
self.log("保存成功, 文件名为{}".format(fname))
5.4 运行爬虫
同样是在工程目录下, 执行命令运行爬虫
Scrapy crawl demoSpider
6 Scrapy数据信息
基本使用的步骤为
1) 创建一个工程和Spider模板
2) 编写Spider
3) 编写Item Pipeline
4) 优化配置策略
使用的基本数据类型
1) Request类 向网络上提交请求的内容
class.scrapy.http.Request()
表示一个http请求
有Spider生成, 有Downloader执行
具体的属性和方法
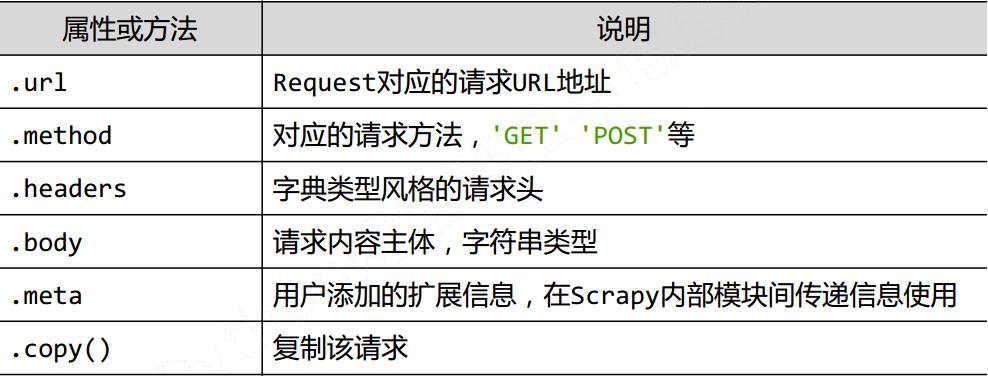
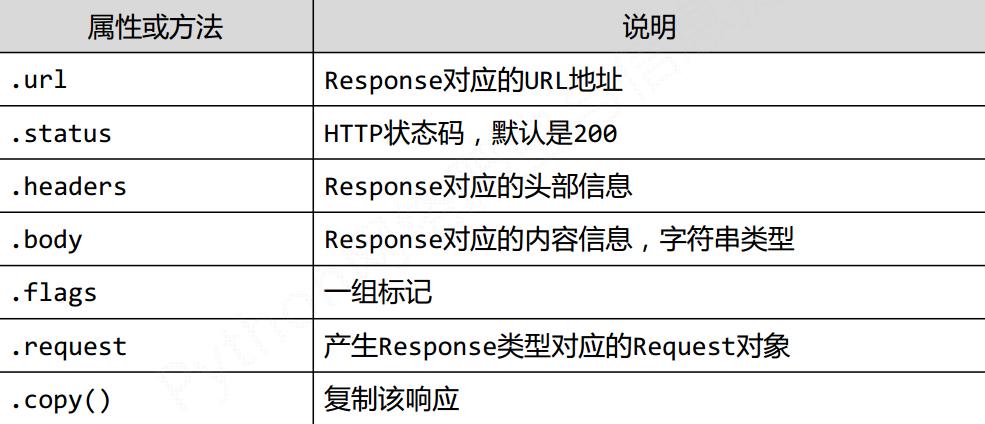
2) Response类 爬取内容的封装类
class.scrapy.http.Response()
表示一个http的响应
有Downloader生成, 有Spider处理
属性和方法有
3) Item类 Spider产生的信息封装的类
class.scrapy.http.Item()
Item对象表示一个从HTML页面中提取单位信息内容
由Spider生成, 有Item Pipeline处理
Item类似字典类型, 可以按照字典类型操作
提取信息的方法有
Beautifull Soup
lxml
re
XPath Selector
CSS Selector
具体的CSS Selector
基本格式
HTML.css( \'标签名称::标签属性\' ).extract()
7 Scrapy爬虫实例
待续..
以上是关于Mooc爬虫05-scrapy框架的主要内容,如果未能解决你的问题,请参考以下文章