史上最骚爬虫|疯狂爬取中国大学mooc太燃了,爬虫vs慕课反爬世纪大战|No.1
Posted 夜斗小神社
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了史上最骚爬虫|疯狂爬取中国大学mooc太燃了,爬虫vs慕课反爬世纪大战|No.1相关的知识,希望对你有一定的参考价值。
爬取中国大学全网mooc:NO.1
-
作者:夜斗小神社
-
IDEA工具:PyCharm
-
抓包工具:Fiddler
-
时间:2021/5/2

小夜斗与爬虫已经很久没交流过辽,想着能重新把爬虫捡起来,这次就试一下mooc这个网站,希望能够做一个全网爬虫!
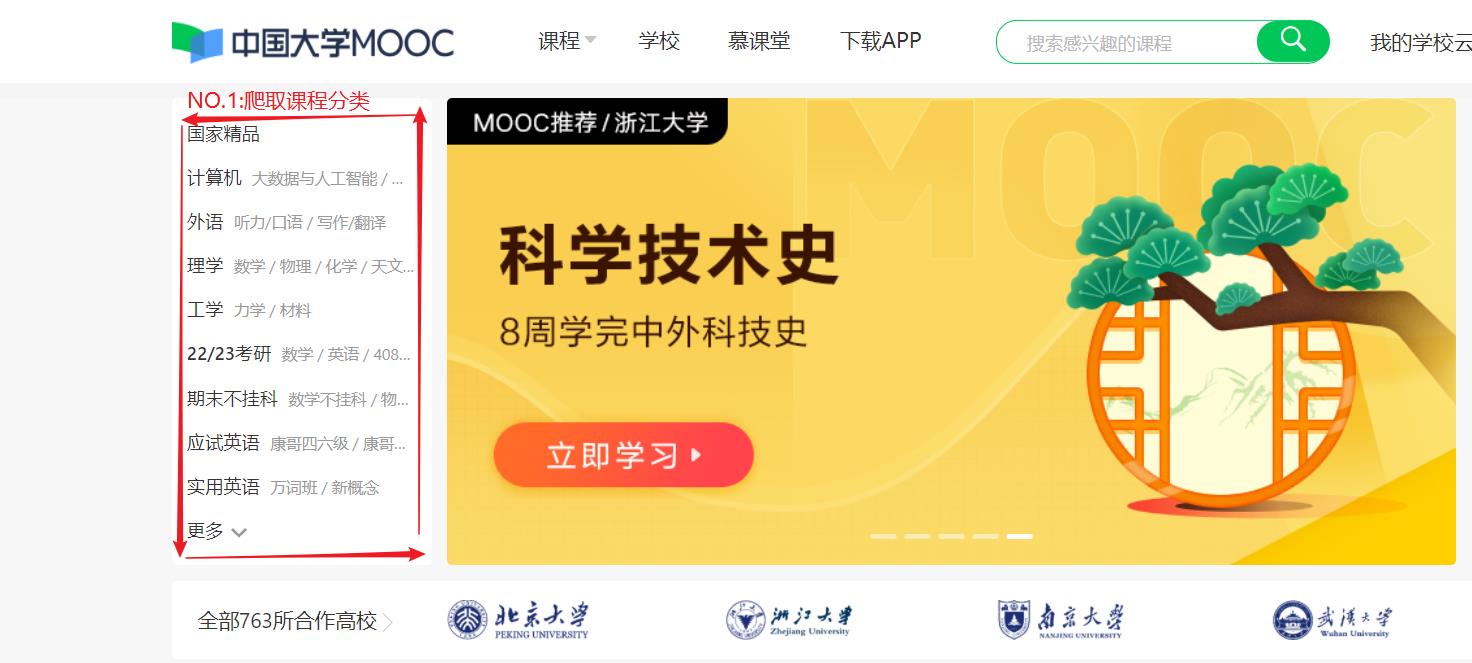
爬取结果是:mooc官网左侧的课程分类,并获取其跳转链接
一:通过Fiddler抓包分析
抓包过程很简单:打开Fiddler点击Caputre,刷新网页进行抓包
小夜斗通过分析发现这个课程分类url地址链接如下所示:
# 1:课程分类网址
course_classify = 'https://www.icourse163.org/web/j/indexBeanV3.getCategoryInfo.rpc?csrfKey=10dc66f3f3eb49148d5bb5ad38269204'
看了一下也没有啥加密的参数,就是一个简单的POST请求
带时候带上请求头headers发送请求就可,请求头如下:
# 2: 请求头
headers = '全部copy下来,cookie千万不要漏掉'
'''
替换规则:快速改变请求头格式
(.*?): (.*)
'$1':'$2',
'''
二:开始着手写爬虫代码
(一):定义一个函数获取课程系列跳转链接
def get_channel():
# 1:课程分类网址
course_classify = 'https://www.icourse163.org/web/j/indexBeanV3.getCategoryInfo.rpc?csrfKey=10dc66f3f3eb49148d5bb5ad38269204'
# 发起请求
r = requests.post(url=course_classify, headers=headers)
try:
if r.status_code == 200:
# 获取json文本内容
content = r.json()
print(content)
# 获取计算机类的跳转链接
computer_href = content['result'][1]['targetUrl']
print(f'computer_href:computer_href')
# 循环遍历拿去课程系列名和跳转链接
# 然后用字典来装载
channel_dict =
for course in content['result']:
# 获取channelName系列课程名
channelName = course['channelName']
# 获取目标链接
targetUrl = course['targetUrl']
channel_dict[channelName] = targetUrl
print(f'channel_dict:channel_dict')
return channel_dict
except:
print("爬虫被识别!")
每行代码都给了详细的注释信息
有问题可以在评论区留言或者私信小夜斗都可以的哈
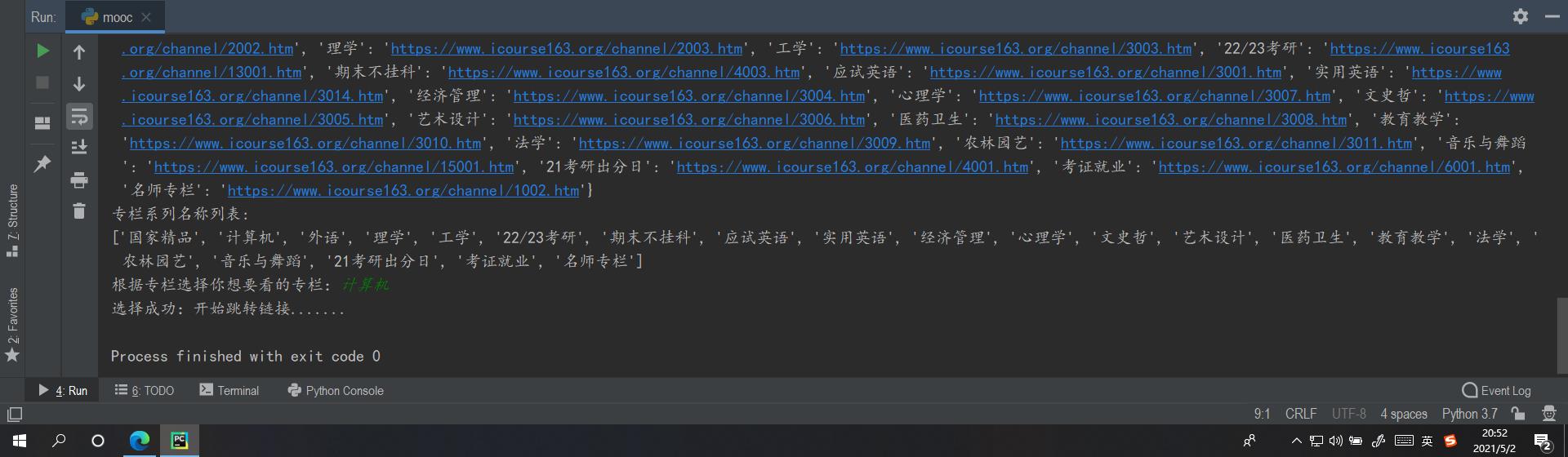
打印的装载目标调整链接的字典channel_dict如下所示:

(二):写一个跳转链接的逻辑接口
获取到的专栏列表:从专栏选择你想要跳转的频道,如果有就直接进行链接跳转,没有的话让用户重新选择!
if __name__ == '__main__':
# 1:定义一个函数获取课程系列跳转链接
course_channel = get_channel()
# 2:获取专栏系列名称
keys = course_channel.keys()
# 以列表的形式打印出来
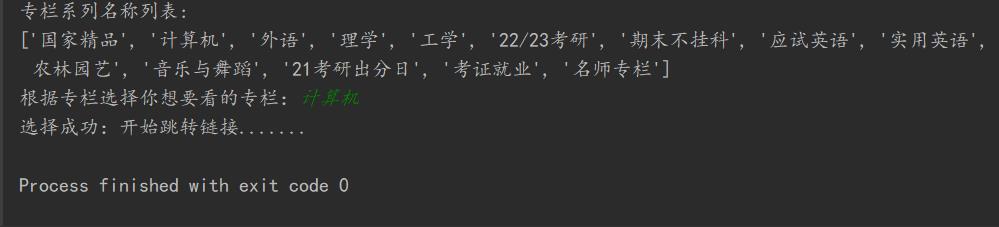
print(f'专栏系列名称列表:\\nlist(keys)')
# 2:访问计算机专栏
while True:
channel = input('根据专栏选择你想要看的专栏:')
if channel not in list(keys):
print("现在还没有开辟此专栏,请重新选择!")
continue
else:
print("选择成功:开始跳转链接.......")
break
本期分享就到这里啦,下期爬虫内容也会是mooc这个网址!
关注夜斗小神社,自学pyhon爬虫不迷路!
- 在这个星球上,你很重要,请珍惜你的珍贵! ~~~夜斗小神社

以上是关于史上最骚爬虫|疯狂爬取中国大学mooc太燃了,爬虫vs慕课反爬世纪大战|No.1的主要内容,如果未能解决你的问题,请参考以下文章