Python爬虫——定向爬取“中国大学排名网”
Posted 大西young
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫——定向爬取“中国大学排名网”相关的知识,希望对你有一定的参考价值。
内容整理自中国大学MOOC——北京理工大学-蒿天-Python网络爬虫与信息提取 相关实战章节
我们预爬取的url如下
http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html
网页节选
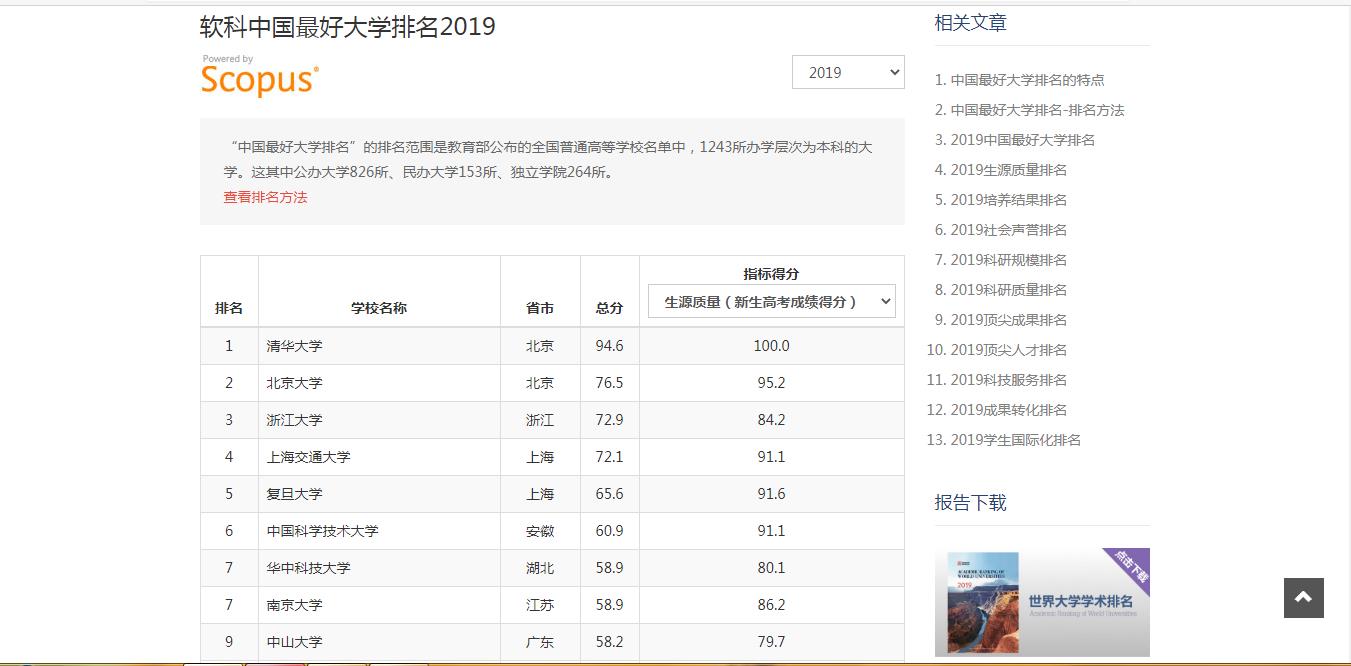
在浏览器中读取网页源代码

可以 发现表格数据信息是直接写入HTML页面信息中,所以我们可以直接采取定向爬虫操作。
我们的整体设计思路如下:
1.从网络上获取大学排名网络内容
2.提取网页内容中信息到合适的数据结构
3.利用数据结构展示并输出结果
仔细观察可以发现,HTML的结构中,每个<tr>标签包含一所大学的全部信息,而一组<tr>内,大学的校名、省市、名次等信息由<td>标记
所有<tr>均为<tbody>的子节点
根据设计思路几网页结构信息,代码如下
1 import requests 2 from bs4 import BeautifulSoup 3 import bs4 4 5 def getHTMLText(url): #获取url信息 6 try: 7 r = requests.get(url,timeout = 30) 8 r.raise_for_status() 9 r.encoding = r.apparent_encoding 10 return r.text 11 except: 12 return "" 13 14 def fillUnivList(ulist,html): #将一个html页面放入一个列表 15 soup = BeautifulSoup(html,"html.parser") 16 #每个<tr>包含一所大学的所有信息 17 #所有<tr>信息包在<tbody>中 18 for tr in soup.find(\'tbody\').children: 19 if isinstance(tr,bs4.element.Tag): #过滤掉非标签信息,以取出包含在<tr>标签中的bs4类型的Tag标签 20 tds = tr(\'td\') #等价于tr.find_all(\'td\'),在tr标签中找td标签内容 21 # print(tds) 22 ulist.append([tds[0].string,tds[1].string,tds[3].string,tds[2].string]) 23 #td[0],[1],[3],[2],分别对应每组td信息中的排名,学校名称,得分,区域。将这些信息从摘取出来 24 25 26 def printUnivList(ulist,num): #将列表信息输出 27 print("{:^10}\\t{:^6}\\t{:^10}\\t{:^10}".format("排名","大学名称","得分","省市")) 28 for i in range(num): 29 u = ulist[i] 30 print("{:^10}\\t{:^6}\\t{:^10}\\t{:^10}".format(u[0],u[1],u[2],u[3])) 31 32 if __name__ == \'__main__\': 33 uinfo = [] 34 url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html" 35 html = getHTMLText(url) 36 fillUnivList(uinfo,html) 37 printUnivList(uinfo,20) #暂时只看前20所学校
输出信息如下

其中第27行处,{:^10}为Python的格式化输出,30表示输出宽度约束为30个字符,^表示输出时右对齐,若宽度小于字符串的实际宽度,以实际宽度输出
为了使输出结果更整齐,我们可以对于输出部分进行优化
我们在输出时用到了format()方法,这样就会产生一个问题:当中文字符宽度不够时,方法会默认采用西文字符填充。而中西文字符宽度并不相同,这就是导致每行字符无法一一对齐的原因。
这里我们就可以设置format()填充方式为,采用中文字符的空格填充,即chr(12288)
于是我们对printUnivList()方法做如下修改
def printUnivList(ulist,num): #将列表信息输出 tplt = "{0:^10}\\t{1:{4}^10}\\t{2:^10}\\t{3:^10}" #{4}表示需要用到format方法中,从0伊始定义的第[4]个变量 print(tplt.format("排名","大学名称","得分","省市",chr(12288))) for i in range(num): u = ulist[i] print(tplt.format(u[0],u[1],u[2],u[3],chr(12288)))
输出结果如下

这样就对齐了
以上是关于Python爬虫——定向爬取“中国大学排名网”的主要内容,如果未能解决你的问题,请参考以下文章