最小生成树之克鲁斯卡尔(Kruskal)算法
Posted 风中的簌雨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最小生成树之克鲁斯卡尔(Kruskal)算法相关的知识,希望对你有一定的参考价值。
学习最小生成树算法之前我们先来了解下 下面这些概念:
树(Tree):如果一个无向连通图中不存在回路,则这种图称为树。
生成树 (Spanning Tree):无向连通图G的一个子图如果是一颗包含G的所有顶点的树,则该子图称为G的生成树。
生成树是连通图的极小连通子图。这里所谓极小是指:若在树中任意增加一条边,则将出现一条回路;若去掉一条边,将会使之变成非连通图。
最小生成树(Minimum Spanning Tree,MST):或者称为最小代价树Minimum-cost Spanning Tree:对无向连通图的生成树,各边的权值总和称为生成树的权,权最小的生成树称为最小生成树。
构成生成树的准则有三条:
<1> 必须只使用该网络中的边来构造最小生成树。
<2> 必须使用且仅使用n-1条边来连接网络中的n个顶点
<3> 不能使用产生回路的边。
构造最小生成树的算法主要有:克鲁斯卡尔(Kruskal)算法和普利姆(Prim)算法他们都遵循以上准则。
接下分别讨论一下这两种算法以及判定最小生成树是否唯一的方法。
克鲁斯卡尔算法
克鲁斯卡尔算法的基本思想是以边为主导地位,始终选择当前可用(所选的边不能构成回路)的最小权植边。所以Kruskal算法的第一步是给所有的边按照从小到大的顺序排序。这一步可以直接使用库函数qsort或者sort。接下来从小到大依次考察每一条边(u,v)。
具体实现过程如下:
<1> 设一个有n个顶点的连通网络为G(V,E),最初先构造一个只有n个顶点,没有边的非连通图T={V,空},图中每个顶点自成一格连通分量。
<2> 在E中选择一条具有最小权植的边时,若该边的两个顶点落在不同的连通分量上,则将此边加入到T中;否则,即这条边的两个顶点落到同一连通分量 上,则将此边舍去(此后永不选用这条边),重新选择一条权植最小的边。
<3> 如此重复下去,直到所有顶点在同一连通分量上为止。
下面是伪代码:
1 // 把所有边排序,记第i小的边为e[i] (1<=i<=m)m为边的个数 2 // 初始化MST为空 3 // 初始化连通分量,使每个点各自成为一个独立的连通分量 4 5 for (int i = 0; i < m; i++) 6 { 7 if (e[i].u和e[i].v不在同一连通分量) 8 { 9 // 把边e[i]加入MST 10 // 合并e[i].u和e[i].v所在的连通分量 11 } 12 }

上面的伪代码,最关键的地方在于“连通分量的查询和合并”,需要知道任意两个点是否在同一连通分量中,还需要合并两个连通分量。
这个问题正好可以用并查集完美的解决(不得不佩服前辈们聪明才智啊!)
并查集(Union-Find set)这个数据结构可以方便快速的解决这个问题。基本的处理思想是:初始时把每个对象看作是一个单元素集合;然后依次按顺序读入联通边,将连通边中的两个元素合并。在此过程中将重复使用一个搜索(Find)运算,确定一个集合在那个集合中。当读入一个连通边(u,v)时,先判断u和v是否在同一个集合中,如果是则不用合并;如果不是,则用一个合并(Union)运算把u、v所在集合合并,使得这两个集合中的任意两个元素都连通。因此并查集在处理时,主要用到搜索和合并两个运算。
为了方便并查集的描述与实现,通常把先后加入到一个集合中的元素表示成一个树结构,并用根结点的序号来表示这个集合。因此定义一个parent[n]的数组,parent[i]中存放的就是结点i所在的树中结点i的父亲节点的序号。例如,如果parent[4]=5,就是说4号结点的父亲结点是5号结点。约定:如果i的父结点(即parent[i])是负数,则表示结点i就是它所在的集合的根结点,因为集合中没有结点的序号是负的;并且用负数的绝对值作为这个集合中所含结点的个数。例如,如果parent[7]=-4,说明7号结点就是它所在集合的根结点,这个集合有四个元素。初始时结点的parent值为-1(每个结点都是根结点,只包含它自己一个元素)。
实现Kruskal算法数据结构主要有3个函数。
1 void UFset() // 初始化 2 { 3 for (int i = 0; i < n; i ++) 4 parent[i] = -1; 5 } 6 int Find(int x) // 查找并返回结点x所属集合的根结点 7 { 8 int s; // 查找位置 9 for (s = x; parent[s]>=0; s = parent[s]); // 注意这里的 ; 10 while (s != x) // 优化方案 -- 压缩路径,使后续的查找 11 { 12 int tmp = parent[x]; 13 parent[x] = s; 14 x = tmp; 15 } 16 return s; 17 } 18 // R1和R2是两个元素,属于两个不同的集合,现在合并这两个集合 19 void Union (int R1, int R2) 20 { 21 // r1位R1的根结点,r2位R2的根结点 22 int r1 = Find(R1), r2 = Find(R2); 23 int tmp = parent[r1] + parent[r2]; // 两个集合的结点个数之和(负数) 24 // 如果R2所在树结点个数 > R1所在树结点个数 25 // 注意parent[r1]和parent[r2]都是负数 26 if(parent[r1] > parent[r2]) // 优化方案 -- 加权法则 27 { 28 parent[r1] = r2; // 将根结点r1所在的树作为r2的子树(合并) 29 parent[r2] = tmp; // 跟新根结点r2的parent[]值 30 } 31 else 32 { 33 parent[r2] = r1; // 将根结点r2所在的树作为r1的子树(合并) 34 parent[r1] = tmp; // 跟新根结点r1的parent[]值 35 } 36 }
接下来对 Find 函数和 Union 函数的实现过程作详细解释。
Find 函数:在 Find 函数中如果仅仅靠一个循环来直接得到结点所属集合的根结点的话,通过多次的 Union 操作就会有很多结点在树的比较深层次中,再查找起来就会很费时。可以通过压缩路径来加快后续的查找速度:增加一个 While 循环,每次都把从结点 x 到集合根结点的路径上经过的结点直接设置为根结点的子女结点。虽然这增加了时间,但以后的查找会更快。如图 3.4 所示,假设从结点 x = 6 开始压缩路径,则从结点 6 到根结点1 的路径上有 3 个结点:6、10、8,压缩后,这 3 个结点都直接成为根结点的子女结点,如图(b)所示。

并查集:Find函数中的路径压缩
Union 函数:两个集合并时,任一方可做为另一方的子孙。怎样来处理呢,现在一般采用加权合并,把两个集合中元素个数少的根结点做为元素个数多的根结点的子女结点。这样处理有什么优势呢?直观上看,可以减少树中的深层元素的个数,减少后续查找时间。
例如,假设从 1 开始到 n,不断合并第 i 个结点与第 i+1 个结点,采用加权合并思路的过程如下图所示(各子树根结点上方的数字为其 parent[ ]值)。这样查找任一结点所属集合的时间复杂度几乎都是 O(1)!!!
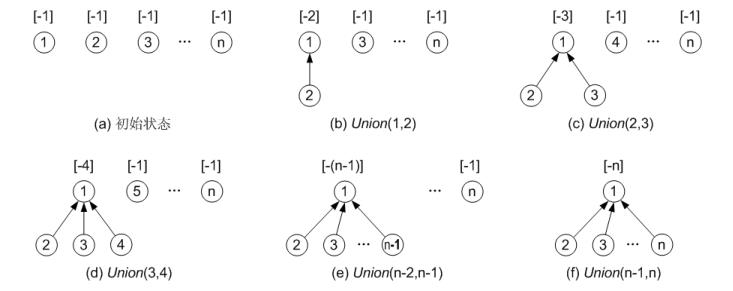
并查集:加权合并
不用加权规则可能会得到下图所示的结果。这就是典型的退化树(只有一个叶结点,且每个非叶结点只有一个子结点)现象,再查找起来就会很费时,例如查找结点 n 的根结点时复杂度为 O(n)。
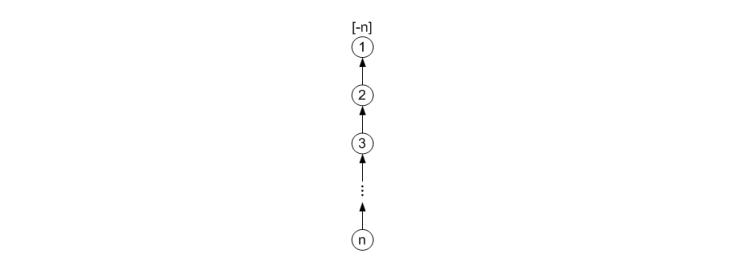
并查集:合并时不加权的结果。
例 利用 Kruskal 算法求无向网的最小生成树,并输出依次选择的各条边及最终求得的最小生成树的权。
假设数据输入时采用如下的格式进行输入:首先输入顶点个数 n 和边数 m,然后输入 m 条边的数据。每条边的数据格式为:u v w,分别表示这条边的两个顶点及边上的权值。顶点序号从 1开始计起。
分析:
在下面的代码中,首先读入边的信息,存放到数组 edges[ ]中,并按权值从小到大进行排序。
Kruskal( )函数用于实现 :首先初始化并查集,然后从 edges[ ]数组中依次选用每条边,如果这条边的两个顶点位于同一个连通分量,则要弃用这条边;否则合并这两个顶点所在的连通分量。
代码如下:


1 #include <stdio.h> 2 #include <string.h> 3 #include <algorithm> 4 #define MAXN 11 //顶点个数的最大值 5 #define MAXM 20 //边的个数的最大值 6 using namespace std; 7 8 struct edge //边 9 { 10 int u, v, w; //边的顶点、权值 11 }edges[MAXM]; //边的数组 12 13 int parent[MAXN]; //parent[i]为顶点 i 所在集合对应的树中的根结点 14 int n, m; //顶点个数、边的个数 15 int i, j; //循环变量 16 void UFset( ) //初始化 17 { 18 for( i=1; i<=n; i++ ) 19 parent[i] = -1; 20 } 21 int Find( int x ) //查找并返回节点 x 所属集合的根结点 22 { 23 int s; //查找位置 24 for( s=x; parent[s]>=0; s=parent[s] ); 25 while( s!=x ) //优化方案―压缩路径,使后续的查找操作加速。 26 { 27 int tmp = parent[x]; 28 parent[x] = s; 29 x = tmp; 30 } 31 return s; 32 } 33 34 //将两个不同集合的元素进行合并,使两个集合中任两个元素都连通 35 void Union( int R1, int R2 ) 36 { 37 int r1 = Find(R1), r2 = Find(R2); //r1 为 R1 的根结点,r2 为 R2 的根结点 38 int tmp = parent[r1] + parent[r2]; //两个集合结点个数之和(负数) 39 //如果 R2 所在树结点个数 > R1 所在树结点个数(注意 parent[r1]是负数) 40 if( parent[r1] > parent[r2] ) //优化方案――加权法则 41 { 42 parent[r1] = r2; 43 parent[r2] = tmp; 44 } 45 else 46 { 47 parent[r2] = r1; 48 parent[r1] = tmp; 49 } 50 } 51 bool cmp( edge a, edge b ) //实现从小到大排序的比较函数 52 { 53 return a.w <= b.w; 54 } 55 void Kruskal( ) 56 { 57 int sumweight = 0; //生成树的权值 58 int num = 0; //已选用的边的数目 59 int u, v; //选用边的两个顶点 60 UFset( ); //初始化 parent[]数组 61 for( i=0; i<m; i++ ) 62 { 63 u = edges[i].u; v = edges[i].v; 64 if( Find(u) != Find(v) ) 65 { 66 printf( "%d %d %d\\n", u, v, edges[i].w ); 67 sumweight += edges[i].w; num++; 68 Union( u, v ); 69 } 70 if( num>=n-1 ) break; 71 } 72 printf( "weight of MST is %d\\n", sumweight ); 73 } 74 int main( ) 75 { 76 int u, v, w; //边的起点和终点及权值 77 scanf( "%d%d", &n, &m ); //读入顶点个数 n 78 for( int i=0; i<m; i++ ) 79 { 80 scanf( "%d%d%d", &u, &v, &w ); //读入边的起点和终点 81 edges[i].u = u; edges[i].v = v; edges[i].w = w; 82 } 83 sort(edges,edges+m,cmp); 84 Kruskal(); 85 return 0; 86 }
以上是关于最小生成树之克鲁斯卡尔(Kruskal)算法的主要内容,如果未能解决你的问题,请参考以下文章