Cassandra存储time series类型数据时的内部数据结构?
Posted 一直问
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Cassandra存储time series类型数据时的内部数据结构?相关的知识,希望对你有一定的参考价值。
因为我一直想用Cassandra来存储我们的数字电表中的数据,按照之前的文章(getting-started-time-series-data-modeling )的介绍,Cassandra真的和适合用于存储time series类型的数据,那么我就想要弄清楚,对于下面这张表
CREATE TABLE temperature ( weatherstation_id text, event_time timestamp, temperature text, PRIMARY KEY (weatherstation_id,event_time));
在插入了下面这些数据之后,他内部究竟是怎么存储的?
INSERT INTO temperature(weatherstation_id,event_time,temperature) VALUES (\'1234ABCD\',\'2013-04-03 07:01:00\',\'72F\'); INSERT INTO temperature(weatherstation_id,event_time,temperature) VALUES (\'1234ABCD\',\'2013-04-03 07:02:00\',\'73F\'); INSERT INTO temperature(weatherstation_id,event_time,temperature) VALUES (\'1234ABCD\',\'2013-04-03 07:03:00\',\'73F\'); INSERT INTO temperature(weatherstation_id,event_time,temperature) VALUES (\'1234ABCD\',\'2013-04-03 07:04:00\',\'74F\');
如果按照传统的关系数据库的逻辑,那么在数据库中就存在如下行:
weatherstation_id, event_time, temprature \'1234ABCD\',\'2013-04-03 07:01:00\',\'72F\' \'1234ABCD\',\'2013-04-03 07:02:00\',\'73F\' \'1234ABCD\',\'2013-04-03 07:03:00\',\'73F\' \'1234ABCD\',\'2013-04-03 07:04:00\',\'74F\'
假如在数据库中真的也是这么存储的,那就和关系数据库一样了,那我继续使用Postgresql就可以了,还来瞎折腾干什么。
但是我真心希望文章getting-started-time-series-data-modeling所介绍的例子是正确的,我希望数据确实是按照下图这种方式来存储的。

也就是同一个温度气象站的所有温度数据全都存储在同一行,row key就是weatherStationId。那么我就想要弄清楚上面这个temperature 表明明只定义了weatherstation_id, event_time, temperature三列,并且weatherstation_id, event_time作为primary key,为什么到存储的时候,event_time的值就变为列名了?这里究竟是一种什么样的转换规则。
另外,在很多地方出现的这张图中,这个 row key1究竟是什么,他和primary key之间有什么关系?
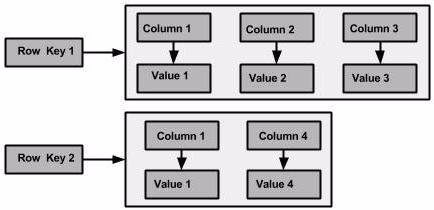
在查阅了一些相关的资料,特别是看了understanding-how-cql3-maps-to-cassandras-internal-data-structure这篇文章之后,我感觉这次我真的懂了,下面来详细说说我的理解。
一、几个基本概念
首先我们来弄清楚几个基本概念
1) Primary Key;
2) Partition Key;
3) Compound Primary key;
4) Composit Partition key;
5) Clustering Key;
6) Row Key;
首先给个公式,
Primary Key = Partition Key + [Clustering Key]
Row Key=PartitionKey
这里的意思就是,Primary Key是有Partition Key 和 Clustering key组成的,其中 Clustering key是可选的。
Primary key, Partition key, clustering key都可以由多个字段组成,其中Partition key如果要由多个字段组成,要用小括号括起来。
Row Key就是PartitionKey,也就是一行的唯一标识。
下面来给几个例子。
例子1:
CREATE TABLE users ( user_name varchar PRIMARY KEY, password varchar, gender varchar, session_token varchar, state varchar, birth_year bigint );
在这例子中:
Primary key = user_name
Partition key = user_name
Clustering key = null
RowKey=user_name;
例子2:
CREATE TABLE emp ( empID int, deptID int, first_name varchar, last_name varchar, PRIMARY KEY (empID, deptID) );
Primary Key=empId, deptId;
Partition key=empId
Clustering Key=deptId
rowKey=empId
此时的Primary key 就叫做 Compound Primary Key
例子3:
CREATE TABLE Cats ( block_id uuid, breed text, color text, short_hair boolean, PRIMARY KEY ((block_id, breed), color, short_hair) );
Primary Key = (block_id, breed), color, short_hair
PartitionKey=block_id, breed
ClusteringKey=color, short_hair
rowKey=blockId, breed
此时的Primary key 就叫做 Compound Primary Key
此时的PartitionKey就叫做Composit Partition Key
二、Cassandra的表schema与内部存储结构的转换关系
(1)例子1:
CreateTable employees( name text PRIMARY KEY, age int, role text );
加上往该表中插入如下几条数据
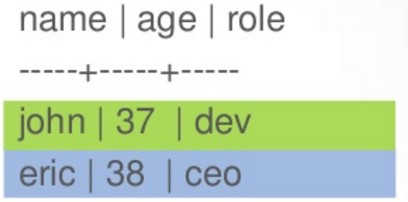
此时,他在Cassandra内部实际上是这么存储的
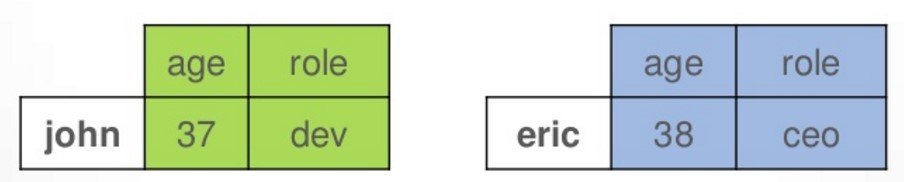
可以看到,PartitionKey对应的name的值被作为row key
然后每一行有2列,每一列都包含列名和值,这个看起来和关系数据库区别不大,他相对于关系数据库其实存在数据冗余,就是每一行都单独存储了列名,而不是像关系数据库一样,有一个统一的列名。
(2) 例子2
CreateTable employees( company text, name text, age int, role text, PRIMARY KEY(company, name) );
往表内插入了如下数据
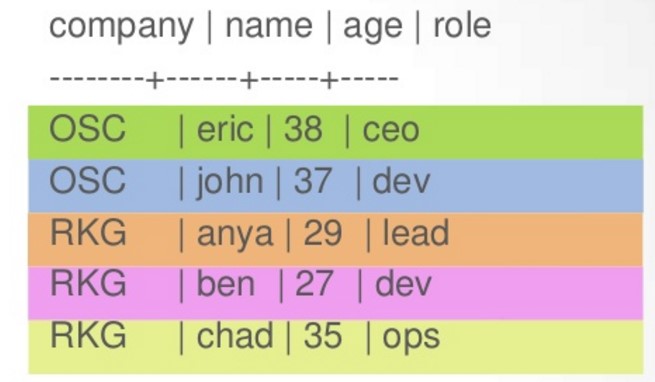
此时,在Cassandra内部实际上是这么存的

简单说明下
company 是row key,上面的数据中company只有OSC和RKG两个值,那就是有两个row key,所以在数据库中就有2行。
name是clustering key, 此时就相当于是clusteringkey的值和primary key的每一列一起组成一个组合列名,比如OSC,eric行就组成了eric:age, eric:role两列。而OSC, john行就组成了john:age, john:role两列。
(3)例子3
CreateTable example( A text, B text, C text, D text, E text, F text, PrimaryKey((A,B),C,D) )
往表中插入如下数据
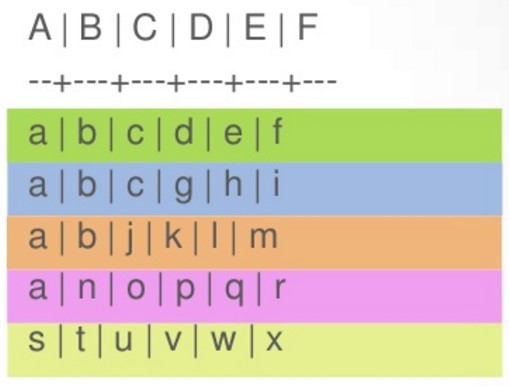
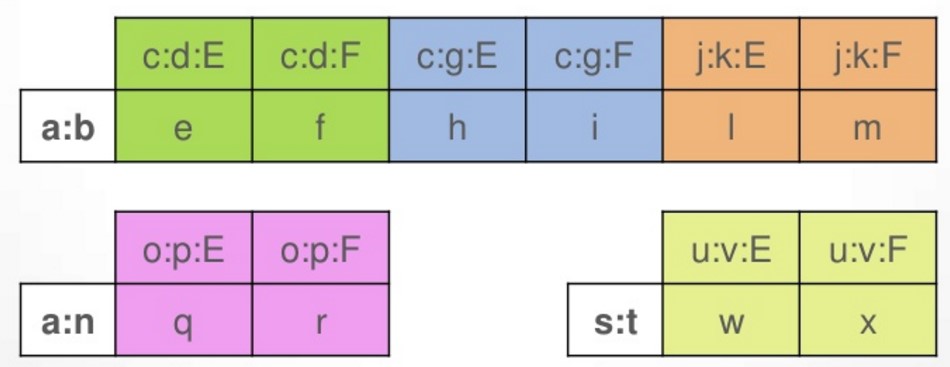
此时在Cassandra内部是这么存的,这次不一样的就是,
PartitionKey是CompositPartitionKey,这就导致rowkey是一个组合键,比如下面的a:b, a:n, s:t
并且ClusteringKey也是由多列组成的,这样在和非Primary key的列拼接列名的时候,就要加上两个字段,比如下面的c:d:E, c:d:F
三、开篇的那个time series类型数据例子的存储结构
套用上一节的模式,开篇那个表在插入如下数据之后
weatherstation_id, event_time, temprature \'1234ABCD\',\'2013-04-03 07:01:00\',\'72F\' \'1234ABCD\',\'2013-04-03 07:02:00\',\'73F\' \'1234ABCD\',\'2013-04-03 07:03:00\',\'73F\' \'1234ABCD\',\'2013-04-03 07:04:00\',\'74F\'
在Cassandra的存储结构是这样的。

所有在同一个row key中的数据,在硬盘中就是连续存储的。
参考资料:
1)这个问题和我的疑问类似,http://stackoverflow.com/questions/23096572/cassandra-long-row-with-different-data-types
3)理解Cassandra的关键概念和数据模型,https://my.oschina.net/silentriver/blog/182678
4) understanding-how-cql3-maps-to-cassandras-internal-data-structure, https://www.slideshare.net/DataStax/understanding-how-cql3-maps-to-cassandras-internal-data-structure
以上是关于Cassandra存储time series类型数据时的内部数据结构?的主要内容,如果未能解决你的问题,请参考以下文章
mongodb - 时间序列集合(time series collection)
Time-series Storage Layer Time Series Databases 时间序列
Magisterium Series by Holly Black, Cassandra Clare,1-4 epub+mp3