机器学习之统计分析
Posted 傲慢的上校
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习之统计分析相关的知识,希望对你有一定的参考价值。
前言
最近在阿里云数加平台上学习一下机器学习,把学习中整理的资料记录于此,已备查看,以下资料主要是概念解释及应用。
相关系数矩阵
了解相关矩阵前先了解相关系数。
相关系数的取值范围为[-1,1],当相关系数为1时,表示正相关;当相关系数为-1时,表示负相关;当相关系数为0时,表示不相关。
正相关:因变量随着自变量的增大而增大
负相关:因变量随着自变量的增大而减小
计算公式:
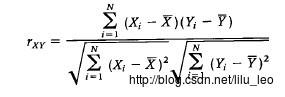
相关矩阵
相关矩阵中每个值都是代表原矩阵中各列之间的相关系数(相关矩阵为方阵,阶数为原矩阵的列数),对角线上都是原矩阵各列与自身的相关系数,所以对角线的值均为1。
参考资料
样本检验
双样本T检验
- 独立样本是指两个样本之间彼此独立。独立样本T检验是检测两个样本之间是否有显著性差异。前提是两个样本相互独立,来自的两个总体服从正态分布。
- 配对样本T检验是检验来自两配对总体的均值是否有显著性差异。
来自维基百科的定义:
其零假设为两个正态分布的总体的均值之差为某实数,例如检验二群人的身高之平均是否相等。这一检验通常被称为学生t检验。但更为严格地说,只有两个总体的方差是相等的情况下,才称为学生t检验;否则,有时被称为Welch检验。以上谈到的检验一般被称作“未配对”或“独立样本”t检验,我们特别是在两个被检验的样本没有重叠部分时用到这种检验方式。
单样本T检验
单样本T检验是检验某个变量的总体均值和某指定值之间是否存在显著差异。T检验的前提是样本总体服从正态分布。
来自维基百科的定义:
检验一个正态分布的总体的均值是否在满足零假设的值之内,例如检验一群人的身高的平均是否符合170公分。
参考资料
正态检验
正态性检验是检验观测值是否服从正态分布,本组件由三种检验方法组成,包括Anderson-Darling Test, Kolmogorov-Smirnov Test,以及QQ图。
原假设H0:观测值服从正态分布,H1:观测值不服从正态分布
KS的p值计算方法采用渐进计算KS分布的CDF,无论样本量多大都采用的是该方法
QQ图在样本量>1000时,会采样进行计算和画图输出,因此图中的数据点不一定覆盖所有样本
效果图
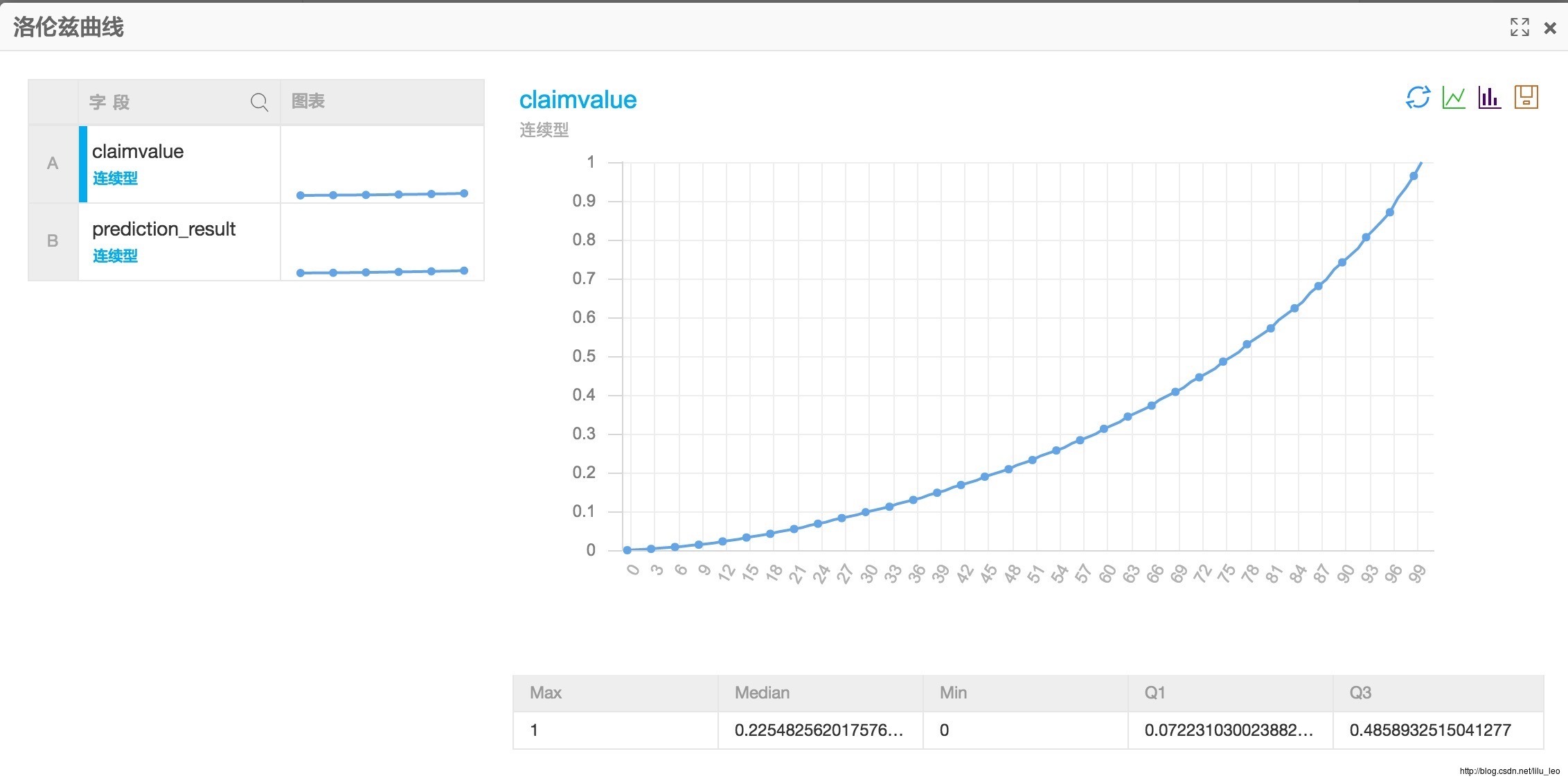
洛伦兹曲线
洛伦兹曲线研究的是国民收入在国民之间的分配问题。为了研究国民收入在国民之间的分配问题,美国统计学家(或说奥地利统计学家)M.O.洛伦兹(Max Otto Lorenz,1903- )1907年(或说1905年)提出了著名的洛伦兹曲线。意大利经济学家基尼在此基础上定义了基尼系数。 画一个矩形,矩形的高衡量社会财富的百分比,将之分为N等份,每一等分为1/N的社会总财富。在矩形的长上,将所有家庭从最贫者到最富者自左向右排列,也分为N等分,第一个等份代表收入最低的1/N的家庭。在这个矩形中,将每1/N的家庭所有拥有的财富的占比累积起来,并将相应的点画在图中,便得到了一条曲线就是洛伦兹曲线。
效果图
参考资料
分位数及百分位数
Quartile(四分位数)
四分位数(Quartile)是统计学中分位数的一种,即把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值就是四分位数。
第一四分位数 (Q1),又称“较小四分位数”,等于该样本中所有数值由小到大排列后第25%的数字。
第二四分位数 (Q2),又称“中位数”,等于该样本中所有数值由小到大排列后第50%的数字。
第三四分位数 (Q3),又称“较大四分位数”,等于该样本中所有数值由小到大排列后第75%的数字。
第三四分位数与第一四分位数的差距又称四分位距(InterQuartile Range, IQR)
百分位
计算某列的百分位。
维基百科定义:
百分位数,统计学术语,如果将一组数据从小到大排序,并计算相应的累计百分位,则某一百分位所对应数据的值就称为这一百分位的百分位数。运用在教育统计学中,例如表现测验成绩时。(维基百科)
参考资料
皮尔森系数
在统计学中,皮尔逊积矩相关系数(英语:Pearson product-moment correlation coefficient,又称作 PPMCC或PCCs[1], 文章中常用r或Pearson’s r表示)用于度量两个变量X和Y之间的相关(线性相关),其值介于-1与1之间。在自然科学领域中,该系数广泛用于度量两个变量之间的相关程度。它是由卡尔·皮尔逊从弗朗西斯·高尔顿在19世纪80年代提出的一个相似却又稍有不同的想法演变而来的。[2][3]这个相关系数也称作“皮尔森相关系数r”。
公式定义
两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商:

数值含义
样本的简单相关系数一般用r表示,其中n 为样本量, 分别为两个变量的观测值和均值。r描述的是两个变量间线性相关强弱的程度。r的取值在-1与+1之间,若r>0,表明两个变量是正相关,即一个变量的值越大,另一个变量的值也会越大;若r<0,表明两个变量是负相关,即一个变量的值越大另一个变量的值反而会越小。r 的绝对值越大表明相关性越强,要注意的是这里并不存在因果关系。若r=0,表明两个变量间不是线性相关,但有可能是其他方式的相关(比如曲线方式)
参考资料
直方图(多字段)
可选择多个字段查看直方图
离散值特征分析
- 统计离散值的gini系数、entropy、对应label个数等
- 空值不过滤,当做一个枚举值计算
- 稀疏格式表示,某列的某个枚举值如果只有1个Label,对于未出现的label不输出0
- 对于每个离散值的gini,entropy都乘以该离散值的概率
图示如下:

gini 系数
维基百科定义:
基尼系数(英语:Gini coefficient),是20世纪初意大利学者科拉多·基尼根据劳伦茨曲线所定义的判断年收入分配公平程度的指标[2]。是比例数值,在0和1之间。基尼指数(Gini index)是指基尼系数乘100倍作百分比表示。在民众收入中,如基尼系数最大为“1”,最小为“0”。前者表示居民之间的年收入分配绝对不平均(即该年所有收入都集中在一个人手里,其余的国民没有收入),而后者则表示居民之间的该年收入分配绝对平均,即人与人之间收入绝对平等,这基尼系数的实际数值只能介于这两种极端情况,即0~1之间。基尼系数越小,年收入分配越平均,基尼系数越大,年收入分配越不平均。要注意基尼系数只计算某一时段,如一年的收入,不计算已有财产,因此它不能反映国民的总积累财富分配情况。
entropy(熵)
系统的熵值直接反映了它所处状态的均匀程度,系统的熵值越小,它所处的状态越是有序,越不均匀;系统的熵值越大,它所处的状态越是无序,越均匀。
链接资料
以上是关于机器学习之统计分析的主要内容,如果未能解决你的问题,请参考以下文章