Distributed Representation——词向量
Posted TopCoderのZeze
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Distributed Representation——词向量相关的知识,希望对你有一定的参考价值。
Distributed Representation 这种表示,它最早是 Hinton 于 1986 年提出的,可以克服 one-hot representation 的缺点。
其基本想法是:
通过训练将某种语言中的每一个词映射成一个固定长度的短向量(当然这里的“短”是相对于 one-hot representation 的“长”而言的),将所有这些向量放在一起形成一个词向量空间,而每一向量则为该空间中的一个点,在这个空间上引入“距离”,则可以根据词之间的距离来判断它们之间的(词法、语义上的)相似性了。
为更好地理解上述思想,我们来举一个通俗的例子:假设在二维平面上分布有 N 个不同的点,给定其中的某个点,现在想在平面上找到与这个点最相近的一个点,我们是怎么做的呢?首先,建立一个直角坐标系,基于该坐标系,其上的每个点就唯一地对应一个坐标 (x,y);接着引入欧氏距离;最后分别计算这个词与其他 N-1 个词之间的距离,对应最小距离值的那个词便是我们要找的词了。
上面的例子中,坐标(x,y) 的地位相当于词向量,它用来将平面上一个点的位置在数学上作量化。坐标系建立好以后,要得到某个点的坐标是很容易的,然而,在 NLP 任务中,要得到词向量就复杂得多了,而且词向量并不唯一,其质量也依赖于训练语料、训练算法和词向量长度等因素。
一种生成词向量的途径是利用神经网络算法,当然,词向量通常和语言模型捆绑在一起,即训练完后两者同时得到。用神经网络来训练语言模型的思想最早由百度 IDL (深度学习研究院)的徐伟提出。 这方面最经典的文章要数 Bengio 于 2003 年发表在 JMLR 上的 A Neural Probabilistic Language Model,其后有一系列相关的研究工作。
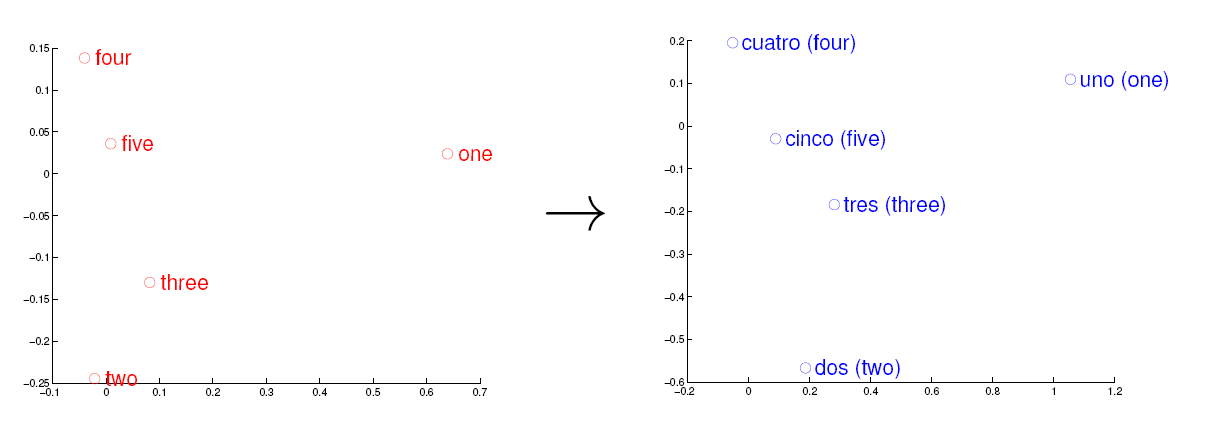
考虑英语和西班牙语两种语言,通过训练分别得到它们对应的词向量空间 E 和 S。从英语中取出五个词 one,two,three,four,five,设其在 E 中对应的词向量分别为 v1,v2,v3,v4,v5,为方便作图,利用主成分分析(PCA)降维,得到相应的二维向量 u1,u2,u3,u4,u5,在二维平面上将这五个点描出来,如下图左图所示。类似地,在西班牙语中取出(与 one,two,three,four,five 对应的) uno,dos,tres,cuatro,cinco,设其在 S 中对应的词向量分别为 s1,s2,s3,s4,s5,用 PCA 降维后的二维向量分别为 t1,t2,t3,t4,t5,将它们在二维平面上描出来(可能还需作适当的旋转),如下图右图所示:
链接:https://www.zhihu.com/question/21714667/answer/19433618
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
以上是关于Distributed Representation——词向量的主要内容,如果未能解决你的问题,请参考以下文章
torch.distributed.barrier() 是如何工作的
[Big Data - ZooKeeper] ZooKeeper: A Distributed Coordination Service for Distributed Applications
ClickHouse 分布式原理:Distributed引擎
ClickHouse 分布式原理:Distributed引擎
The Microsoft Distributed Transaction Coordinator (MS DTC) has cancelled the distributed transaction