Python爬虫练习(拉勾网北京地区数据挖掘类职位所需技能统计)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫练习(拉勾网北京地区数据挖掘类职位所需技能统计)相关的知识,希望对你有一定的参考价值。
这是我最近学习用Python做爬虫时的一个小练习,这段程序可以可以统计拉勾网北京地区的数据挖掘类职位所需的各项技能。程序未完成,还需要加工,目前职位的网址为手动添加,作为程序演示,后续会改为自动读取网址。
代码如下:
1 #encoding: utf-8 2 ‘‘‘ 3 本段代码可以统计拉勾网北京地区的数据挖掘类职位所需的各项技能, 4 每个技能在每个统计职位中出现至少1次,则该技能统计次数加1(一 5 个职位中一个技能只统计1次),最后做出各技能被统计次数的条形图。 6 ‘‘‘ 7 import numpy as np 8 import pandas as pd 9 from pandas import Series, DataFrame 10 import urllib 11 import urllib2 12 import re 13 import matplotlib.pyplot as plt 14 15 #列表:各项技能列表。 16 indexs = [‘sas‘, ‘spss‘, ‘c++‘, ‘c‘, ‘python‘, ‘r‘, ‘java‘, ‘scala‘, ‘excel‘,17 ‘php‘, ‘javascript‘, ‘matlab‘, ‘sql‘, ‘oracle‘, ‘linux‘, ‘unix‘, ‘hadoop‘, 18 ‘spark‘, ‘shell‘, ‘hive‘, ‘storm‘, ‘graphlab‘, ‘perl‘, ‘html‘,19 ‘css‘, ‘etl‘, ‘pig‘, ‘node.js‘, ‘mpi‘, ‘mapreduce‘] 20 21 #字典:技能与匹配对象(有的是str,有的是正则表达式)。 22 i_compile = {‘sas‘: ‘sas‘, ‘spss‘: ‘spss‘, ‘c++‘: ‘c\+\+‘, ‘c‘: re.compile(‘\W(c)[^\+\+]‘), 23 ‘python‘: ‘python‘, ‘r‘: re.compile(‘\W(r)\W‘), ‘java‘: re.compile(‘\W(java)\W‘), 24 ‘scala‘: ‘scala‘, ‘excel‘: ‘excel‘,‘php‘: ‘php‘, ‘javascript‘: ‘javascript‘, ‘matlab‘: ‘matlab‘,25 ‘sql‘: ‘sql‘, ‘oracle‘: ‘oracle‘, ‘linux‘: ‘linux‘, ‘unix‘: ‘unix‘, ‘hadoop‘:‘hadoop‘, 26 ‘spark‘: ‘spark‘, ‘shell‘: ‘shell‘, ‘hive‘: ‘hive‘, ‘storm‘: ‘storm‘, ‘graphlab‘: ‘graphlab‘, 27 ‘perl‘: ‘perl‘, ‘html‘: ‘html‘,‘css‘: ‘css‘, ‘etl‘: ‘etl‘, ‘pig‘: ‘pig‘, 28 ‘node.js‘: re.compile(‘node\.js‘), ‘mpi‘: ‘mpi‘, 29 ‘mapreduce‘: re.compile(‘map.*?reduce‘)} 30 31 #字典:技能与对应出现次数的初始化字典。 32 i_num = {‘sas‘: 0, ‘spss‘: 0, ‘c++‘: 0, ‘c‘: 0, ‘python‘: 0, ‘r‘: 0, ‘java‘: 0, ‘scala‘: 0, ‘excel‘: 0,33 ‘php‘:0 , ‘javascript‘: 0, ‘matlab‘: 0, ‘sql‘: 0, ‘oracle‘: 0, ‘linux‘: 0, ‘unix‘: 0, ‘hadoop‘: 0, 34 ‘spark‘: 0, ‘shell‘: 0, ‘hive‘: 0, ‘storm‘: 0, ‘graphlab‘: 0, ‘perl‘: 0, ‘html‘: 0,35 ‘css‘: 0, ‘etl‘: 0, ‘pig‘: 0, ‘node.js‘: 0, ‘mpi‘: 0, ‘mapreduce‘: 0} 36 37 ‘‘‘北京数据挖掘类职位网址中的识别数字列表。 38 由于在自动获取这些网址时出现暂时未解决的问题, 39 所以暂时用手动添加的方法,随后会改为自动获取。 40 ‘‘‘ 41 url_nums = list(set([1521343, 1460446, 1123652, 1521661, 1266473, 1389005, 566792,42 1421532, 866283, 1244664, 757822, 1397719, 1428753, 1228585, 1254900,43 1470122, 1287218, 819958, 1338895, 1320087, 928769, 1382566, 1455719,44 1424624, 1275249, 1234735, 1366102, 1244664, 1515723, 1506654, 1507391]))#为了防止自己重复粘贴,所以用了set方法。 45 for url_num in url_nums: 46 url = ‘http://www.lagou.com/jobs/‘ + str(url_num) + ‘.html‘ 47 try: 48 request = urllib2.Request(url) #向网页发送请求。 49 response = urllib2.urlopen(request) #得到网页响应。 50 content = response.read() #读取网页内容。 51 #编译要获取内容的正则表达式。 52 pattern = re.compile(‘<dd class="job_bt">.*?<h3.*?</h3>(.*?) <dd class="jd_publisher">‘, re.S) 53 items = re.findall(pattern,content) #找到网页内容中要获取的内容,items为list。 54 item = items[0] #item为str。 55 item = item.lower() #将item变为小写。 56 item = re.sub(re.compile(r‘<.*?>‘), ‘‘, item) #去除item中类似‘<br>‘的字符串。 57 for index in indexs: 58 if bool(re.search(i_compile[index], item)): #利用re.search判断item中是否有技能字符串。 59 i_num[index] += 1 #如果有,则相应字符串的次数加1 60 #(注意:一个职位描述中,一个技能字符串出现次数不等于零,inum[index]都只加1)。 61 except urllib2.URLError, e: 62 if hasattr(e,"code"): 63 print e.code 64 if hasattr(e,"reason"): 65 print e.reason 66 67 i_num = Series(i_num) #将i_num转换为Series格式(也可以在前面直接用Series,此处暂且不改动)。 68 i_num = i_num.sort_values(ascending = True)#排序。 69 #绘制横向条形图,颜色为红色,横坐标为统计职位总数,网格打开,并添加标题。 70 i_num.plot(kind = ‘barh‘, color = ‘r‘, xticks = np.arange(len(url_nums)+1), grid = ‘on‘,71 title = ‘Data Mining Job Skills Statistics\narea: Beijing numbers: ‘ + str(len(url_nums))) 72 plt.show()
结果如下:
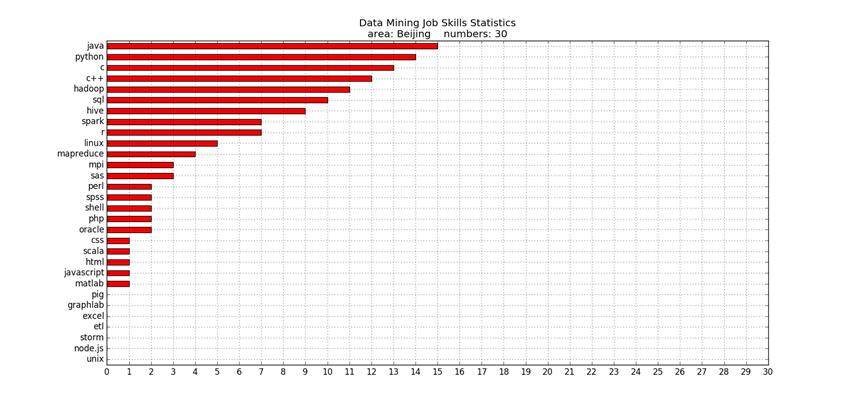
以上是关于Python爬虫练习(拉勾网北京地区数据挖掘类职位所需技能统计)的主要内容,如果未能解决你的问题,请参考以下文章
通俗易懂的分析如何用Python实现一只小爬虫,爬取拉勾网的职位信息
拉勾网爬取全国python职位并数据分析薪资,工作经验,学历等信息