拉勾网爬取全国python职位并数据分析薪资,工作经验,学历等信息
Posted 步摇流苏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了拉勾网爬取全国python职位并数据分析薪资,工作经验,学历等信息相关的知识,希望对你有一定的参考价值。
- 首先前往拉勾网“爬虫”职位相关页面
- 确定网页的加载方式是JavaScript加载
- 通过谷歌浏览器开发者工具分析和寻找网页的真实请求,确定真实数据在position.Ajax开头的链接里,请求方式是POST
- 使用requests的post方法获取数据,发现并没有返回想要的数据,说明需要加上headers和每隔多长时间爬取
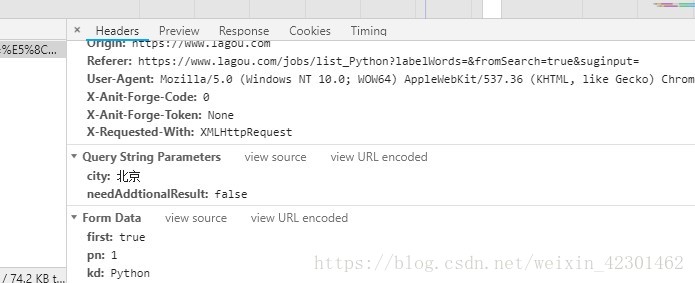
我们可以看到拉勾网列表页的信息一般js加载的都在xhr和js中,通过发送ajax加载POST请求,获取页面信息。 - 这个是ajax的头信息,通过Form Data中的的信息获取页面
- 下面是scrapy爬虫的 代码部分

1 import scrapy 2 import json 3 from lagou.items import LagouItem 4 class LagoupositionSpider(scrapy.Spider): 5 name = ‘lagouposition‘ 6 allowed_domains = [‘lagou.com‘] 7 kd = input(‘请输入你要搜索的职位信息:‘) 8 ct =input(‘请输入要搜索的城市信息‘) 9 page=1 10 start_urls = ["https://www.lagou.com/jobs/list_"+str(kd)+"&city="+str(ct)] 11 headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36", 12 ‘Referer‘: ‘https://www.lagou.com/jobs/list_‘+str(kd)+‘?labelWords=&fromSearch=true&suginput=‘, 13 ‘Cookie‘:‘ _ga=GA1.2.1036647455.1532143907; user_trace_token=20180721113217-aacd6291-8c96-11e8-a020-525400f775ce; LGUID=20180721113217-aacd667e-8c96-11e8-a020-525400f775ce; index_location_city=%E5%8C%97%E4%BA%AC; _gid=GA1.2.1320510576.1532272161; WEBTJ-ID=20180723084204-164c4960832159-09bf89fcd2732e-5e442e19-1049088-164c496083348; JSESSIONID=ABAAABAABEEAAJAC7D58B57D1CAE4616ED47AACF945615E; _gat=1; LGSID=20180723203627-04b27de6-8e75-11e8-9ee6-5254005c3644; PRE_UTM=; PRE_HOST=www.baidu.com; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DYhfCtaCVlOHCdncJxMCMMS3PB1wGlwfw9Yt2c_FXqgu%26wd%3D%26eqid%3D8f013ed00002f4c7000000035b55cbc4; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1532306722,1532306725,1532306732,1532349358; SEARCH_ID=cdd7822cf3e2429fbc654720657d5873; LGRID=20180723203743-3221dec8-8e75-11e8-a35a-525400f775ce; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1532349434; TG-TRACK-CODE=search_code‘ 14 } 15 16 17 def parse(self, response): 18 with open(‘lagou.html‘,‘w‘) as f: 19 f.write(response.text) 20 url="https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false" 21 formdata={‘first‘:‘true‘,‘kd‘:str(self.kd),‘pn‘:‘1‘,‘city‘:str(self.ct)} 22 yield scrapy.FormRequest(url,formdata=formdata,callback=self.parse_detail,headers=self.headers) 23 24 def parse_detail(self,response): 25 text=json.loads(response.text) 26 res=[] 27 try: 28 res = text["content"]["positionResult"]["result"] 29 print(res) 30 except: 31 pass 32 if len(res)>0: 33 item = LagouItem() 34 for position in res: 35 try: 36 item[‘title‘]=position[‘positionName‘] 37 item[‘education‘]=position[‘education‘] 38 item[‘company‘]=position[‘companyFullName‘] 39 item[‘experience‘]=position[‘workYear‘] 40 item[‘location‘]=position[‘city‘] 41 item[‘salary‘] = position[‘salary‘] 42 print(item) 43 except: 44 pass 45 yield item 46 self.page+=1 47 url=‘https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false 48 formdata={‘first‘:‘false‘,‘kd‘:str(self.kd),‘pn‘:str(self.page),‘city‘:str(self.ct)} 49 print(‘===========================‘,formdata) 50 yield scrapy.FormRequest(url, callback=self.parse_detail, formdata=formdata,headers=self.headers) 51 else: 52 print("爬取结束!")
注意拉钩网有反爬措施, 我们在Formreqest提交POST请求消息必须携带kd等键值对,在setting中也许设置
1 DOWNLOAD_DELAY = 20 2 #设置爬取时间 3 ROBOTSTXT_OBEY = False 4 #是否遵循发爬虫协议 5 DEFAULT_REQUEST_HEADERS = { 6 ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘, 7 ‘Accept-Language‘: ‘zh-CN,zh;q=0.8‘, 8 ‘Content-Type‘: ‘application/x-www-form-urlencoded; charset=UTF-8‘, 9 ‘Host‘: ‘www.lagou.com‘, 10 ‘Origin‘: ‘https://www.lagou.com‘, 11 ‘Referer‘: ‘https://www.lagou.com/jobs‘, 12 ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36‘, 13 ‘X-Anit-Forge-Code‘: ‘0‘, 14 ‘X-Anit-Forge-Token‘: ‘None‘, 15 ‘X-Requested-With‘: ‘XMLHttpRequest‘ 16 } 17 #请求头信息headers
接下来就是在items中设置爬取信息的字段
1 import scrapy 2 3 4 class LagouItem(scrapy.Item): 5 # define the fields for your item here like: 6 # name = scrapy.Field() 7 # pass 8 9 education= scrapy.Field() 10 company= scrapy.Field() 11 experience= scrapy.Field() 12 location= scrapy.Field() 13 salary= scrapy.Field() 14 title= scrapy.Field()
在Pipeline.py文件中设置保存爬取文件的格式等
1 import json 2 class LagouPipeline(object): 3 def open_spider(self,spider): 4 self.file=open(‘pythonposition.json‘,‘w‘,encoding=‘utf-8‘) 5 def process_item(self, item, spider): 6 python_dict=dict(item) 7 content=json.dumps(python_dict,ensure_ascii=False)+‘ ‘ 8 self.file.write(content) 9 return item 10 def close_spider(self,spider): 11 self.file.close()
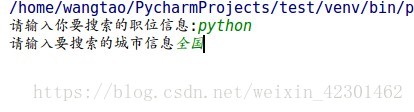
注意一定要把setting中的ITEM_PIPELINES解注释,接下来就是跑起我们的项目,通过input输入想要爬取的职位和城市,

上面就是爬取到的信息总共是855条招聘消息,接下来就是用jumpter-notebook打开爬取到的csv文件用pandas,numpy,和mupltlib进行分析
1 import pandas as pd 2 import numpy as np 3 import seaborn as sns 4 lagou=pd.read_csv(‘./examples/lagou.csv‘) 5 lagou.info() 6 #查看缺失值情况
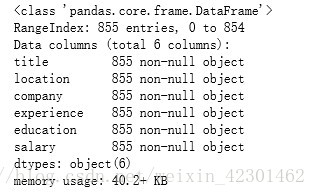
通过读取文件并显示出855条招聘信息是否有缺失值
1 city=lagou[‘location‘] 2 city=pd.DataFrame(city.unique()) 3 city
通过上面可以看到招聘python职位的城市,总共有38城市
1 education=lagou[‘education‘] 2 education=pd.DataFrame(education.unique()) 3 lagou[‘education‘] = lagou[‘education‘].replace(‘不限‘,‘unlimited‘) 4 lagou[‘education‘] = lagou[‘education‘].replace(‘大专‘,‘junior‘) 5 lagou[‘education‘] = lagou[‘education‘].replace(‘本科‘,‘regular‘) 6 lagou[‘education‘] = lagou[‘education‘].replace(‘硕士‘,‘master‘) 7 lagou[‘education‘] = lagou[‘education‘].replace(‘博士‘,‘doctor‘) 8 #seaborn不支持中文需将对应的中文替换 9 import seaborn as sns 10 sns.set_style(‘whitegrid‘) 11 sns.countplot(x=‘education‘,data=lagou,palette=‘Greens_d‘)
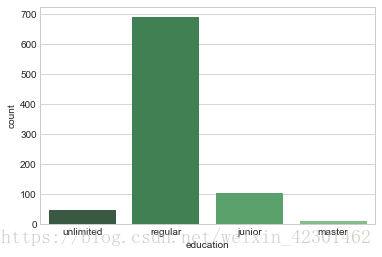
通过上图可以看到大多数的Python职位招聘还是本科学历为主
1 experience=lagou[‘experience‘] 2 experience=pd.DataFrame(experience.unique()) 3 lagou[‘experience‘] = lagou[‘experience‘].replace(‘不限‘,‘unlimited‘) 4 lagou[‘experience‘] = lagou[‘experience‘].replace(‘3-5年‘,‘3-5‘) 5 lagou[‘experience‘] = lagou[‘experience‘].replace(‘1-3年‘,‘1-3‘) 6 lagou[‘experience‘] = lagou[‘experience‘].replace(‘5-10年‘,‘5-10‘) 7 lagou[‘experience‘] = lagou[‘experience‘].replace(‘1年以下‘,‘<1‘) 8 lagou[‘experience‘] = lagou[‘experience‘].replace(‘应届毕业生‘,‘intern‘) 9 experience 10 sns.countplot(x="experience", data=lagou,palette="Blues_d")

上图是招聘的工作经验的人数分布图,可以看到3-5年的Python工程师比较抢手,其次就是1-3年工作经验的
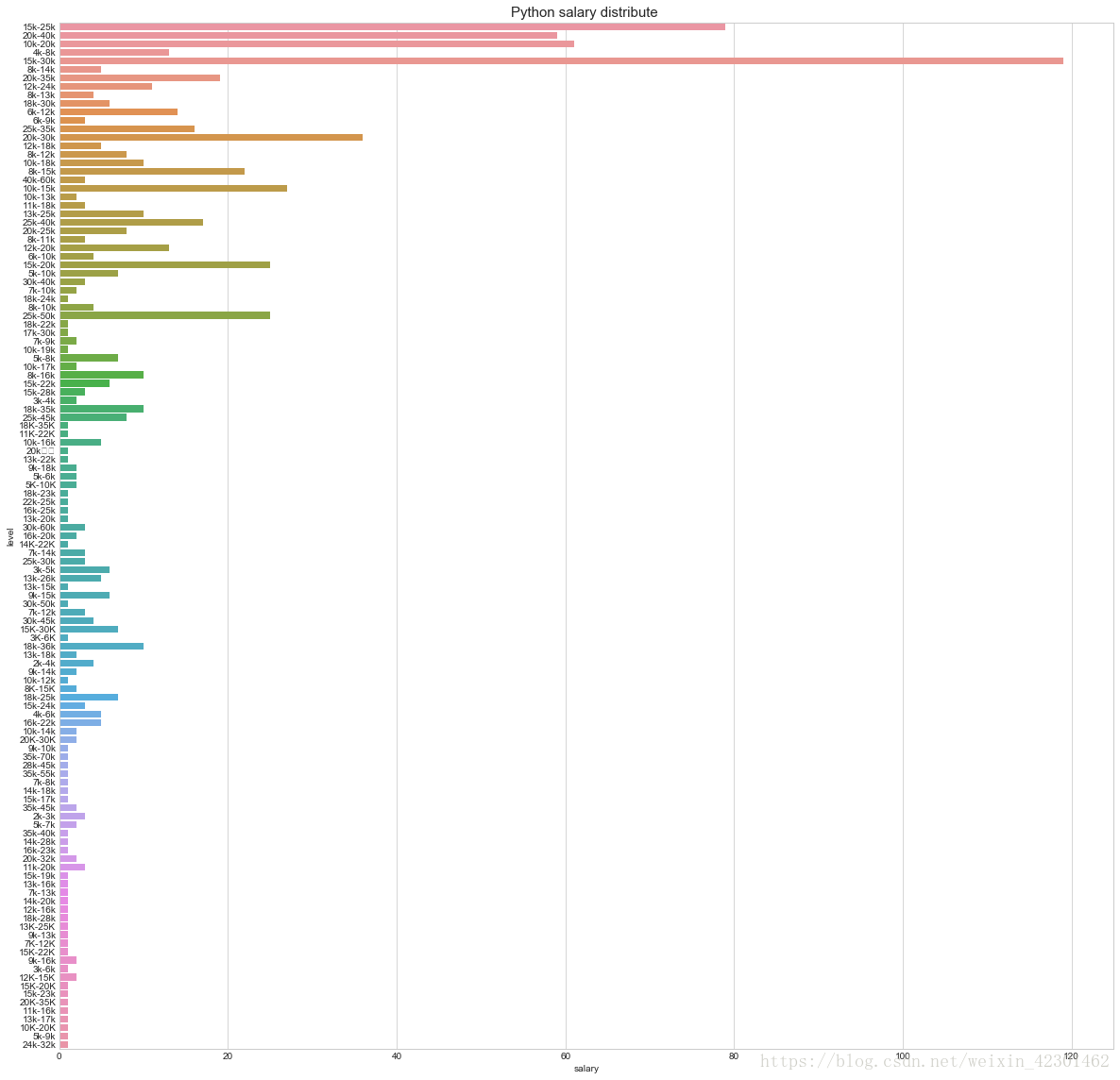
1 import matplotlib.pyplot as plt 2 %matplotlib inline 3 f, ax1= plt.subplots(figsize=(20,20)) 4 sns.countplot(y=‘salary‘, data=lagou, ax=ax1) 5 ax1.set_title(‘Python salary distribute ‘,fontsize=15) 6 #薪资分布 7 ax1.set_xlabel(‘salary‘) 8 #薪资 9 ax1.set_ylabel(‘level‘) 10 plt.show()
同过下图可以看到拉勾网上的pyhong工程师薪资待遇,其中待遇重要分布在10-40K之间,其中给出15-30K工资待遇的企业最多
Python工程师还是很有前景的,
以上是关于拉勾网爬取全国python职位并数据分析薪资,工作经验,学历等信息的主要内容,如果未能解决你的问题,请参考以下文章