Hashmap实现原理
Posted forever-z
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hashmap实现原理相关的知识,希望对你有一定的参考价值。
1.HashMap的数据结构
数组的特点是:寻址容易,插入和删除困难;而链表的特点是:寻址困难,插入和删除容易。那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表,哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法—— 拉链法,我们可以理解为“链表的数组” ,如图:
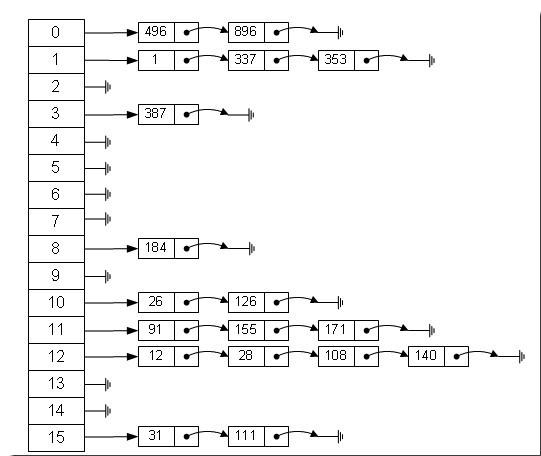
从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。
1.首先HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
2.HashMap的存取实现
既然是线性数组,为什么能随机存取?这里HashMap用了一个小算法,大致是这样实现:
1 //存储时: 2 int hash = key.hashCode();// 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值 3 int index = hash % Entry[].length; 4 Entry[index] = value; 5 6 //取值时: 7 int hash = key.hashCode(); 8 int index = hash % Entry[].length; 9 return Entry[index];
到这里我们轻松的理解了HashMap通过键值对实现存取的基本原理
3.疑问:如果两个key通过hash%Entry[].length得到的index相同,会不会有覆盖的危险?
这里HashMap里面用到链式数据结构的一个概念。上面我们提到过Entry类里面有一个next属性,作用是指向下一个Entry。打个比方, 第一个键值对A进来,通过计算其key的hash得到的index=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其index也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起。所以疑问不用担心。也就是说数组中存储的是最后插入的元素。到这里为止,HashMap的大致实现,我们应该已经清楚了。
当然HashMap里面也包含一些优化方面的实现,这里也说一下。比如:Entry[]的长度一定后,随着map里面数据的越来越长,这样同一个index的链就会很长,会不会影响性能?HashMap里面设置一个因素(也称为因子),随着map的size越来越大,Entry[]会以一定的规则加长长度。
3.解决hash冲突的办法
- 开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列)
- 再哈希法
- 链地址法
- 建立一个公共溢出区
Java中hashmap的解决办法就是采用的链地址法。
4.实现自己的HashMap
Entry.java


1 package edu.sjtu.erplab.hash; 2 3 public class Entry<K,V>{ 4 final K key; 5 V value; 6 Entry<K,V> next;//下一个结点 7 8 //构造函数 9 public Entry(K k, V v, Entry<K,V> n) { 10 key = k; 11 value = v; 12 next = n; 13 } 14 15 public final K getKey() { 16 return key; 17 } 18 19 public final V getValue() { 20 return value; 21 } 22 23 public final V setValue(V newValue) { 24 V oldValue = value; 25 value = newValue; 26 return oldValue; 27 } 28 29 public final boolean equals(Object o) { 30 if (!(o instanceof Entry)) 31 return false; 32 Entry e = (Entry)o; 33 Object k1 = getKey(); 34 Object k2 = e.getKey(); 35 if (k1 == k2 || (k1 != null && k1.equals(k2))) { 36 Object v1 = getValue(); 37 Object v2 = e.getValue(); 38 if (v1 == v2 || (v1 != null && v1.equals(v2))) 39 return true; 40 } 41 return false; 42 } 43 44 public final int hashCode() { 45 return (key==null ? 0 : key.hashCode()) ^ (value==null ? 0 : value.hashCode()); 46 } 47 48 public final String toString() { 49 return getKey() + "=" + getValue(); 50 } 51 52 }
MyHashMap.java
1 package edu.sjtu.erplab.hash; 2 3 //保证key与value不为空 4 public class MyHashMap<K, V> { 5 private Entry[] table;//Entry数组表 6 static final int DEFAULT_INITIAL_CAPACITY = 16;//默认数组长度 7 private int size; 8 9 // 构造函数 10 public MyHashMap() { 11 table = new Entry[DEFAULT_INITIAL_CAPACITY]; 12 size = DEFAULT_INITIAL_CAPACITY; 13 } 14 15 //获取数组长度 16 public int getSize() { 17 return size; 18 } 19 20 // 求index 21 static int indexFor(int h, int length) { 22 return h % (length - 1); 23 } 24 25 //获取元素 26 public V get(Object key) { 27 if (key == null) 28 return null; 29 int hash = key.hashCode();// key的哈希值 30 int index = indexFor(hash, table.length);// 求key在数组中的下标 31 for (Entry<K, V> e = table[index]; e != null; e = e.next) { 32 Object k = e.key; 33 if (e.key.hashCode() == hash && (k == key || key.equals(k))) 34 return e.value; 35 } 36 return null; 37 } 38 39 // 添加元素 40 public V put(K key, V value) { 41 if (key == null) 42 return null; 43 int hash = key.hashCode(); 44 int index = indexFor(hash, table.length); 45 46 // 如果添加的key已经存在,那么只需要修改value值即可 47 for (Entry<K, V> e = table[index]; e != null; e = e.next) { 48 Object k = e.key; 49 if (e.key.hashCode() == hash && (k == key || key.equals(k))) { 50 V oldValue = e.value; 51 e.value = value; 52 return oldValue;// 原来的value值 53 } 54 } 55 // 如果key值不存在,那么需要添加 56 Entry<K, V> e = table[index];// 获取当前数组中的e 57 table[index] = new Entry<K, V>(key, value, e);// 新建一个Entry,并将其指向原先的e 58 return null; 59 } 60 61 }
MyHashMapTest.java
1 package edu.sjtu.erplab.hash; 2 3 public class MyHashMapTest { 4 5 public static void main(String[] args) { 6 7 MyHashMap<Integer, Integer> map = new MyHashMap<Integer, Integer>(); 8 map.put(1, 90); 9 map.put(2, 95); 10 map.put(17, 85); 11 12 System.out.println(map.get(1)); 13 System.out.println(map.get(2)); 14 System.out.println(map.get(17)); 15 System.out.println(map.get(null)); 16 } 17 }
以上是关于Hashmap实现原理的主要内容,如果未能解决你的问题,请参考以下文章