从代码层读懂HashMap的实现原理
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从代码层读懂HashMap的实现原理相关的知识,希望对你有一定的参考价值。
概述
Hashmap继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。它的key、value都可以为null,映射不是有序的。
Hashmap不是同步的,如果想要线程安全的HashMap,可以通过Collections类的静态方法synchronizedMap获得线程安全的HashMap。
Map map = Collections.synchronizedMap(new HashMap());
HashMap 中两个重要的参数:“初始容量” 和 “加载因子”。
容量: 是哈希表中桶的数量,初始容量 只是哈希表在创建时的容量。
加载因子: 是哈希表在其容量自动增加之前可以达到多满的一种尺度(默认0.75)。
当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构,桶数X2)。
加载因子越大,填满的元素越多,好处是,空间利用率高了,但:冲突的机会加大了.反之,加载因子越小,填满的元素越少, 好处是:冲突的机会减小了,但:空间浪费多了。
HashMap数据结构
Hashmap本质是数组加链表。通过key的hashCode来计算hash值的,只要hashCode相同,计算出来的hash值就一样,然后再计算出数组下标,如果多个key对应到同一个下标,就用链表串起来,新插入的在前面。
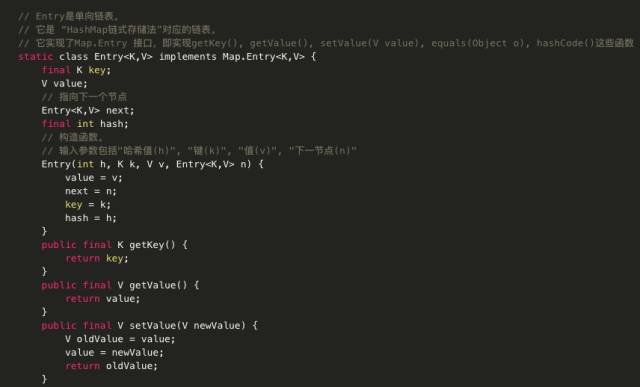
先来看看HashMap中Entry类的代码:
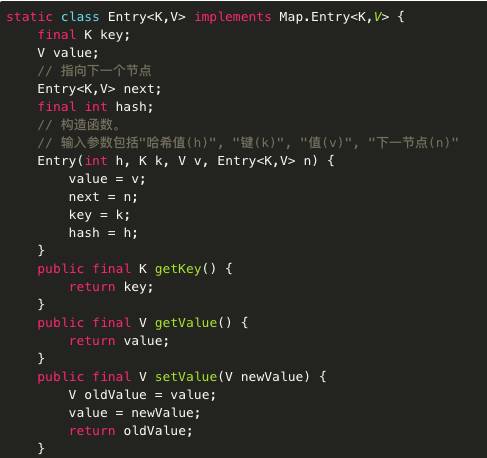
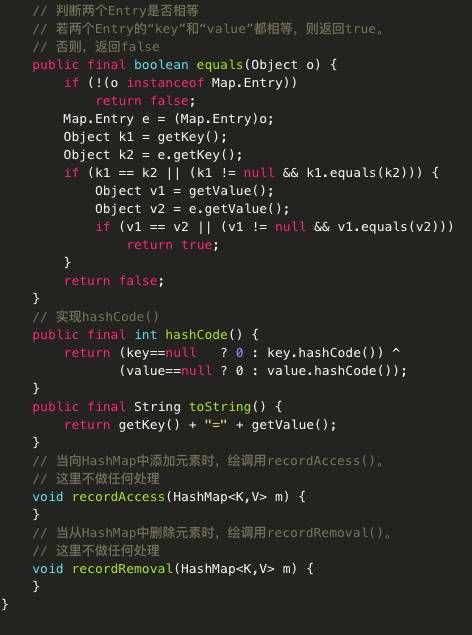
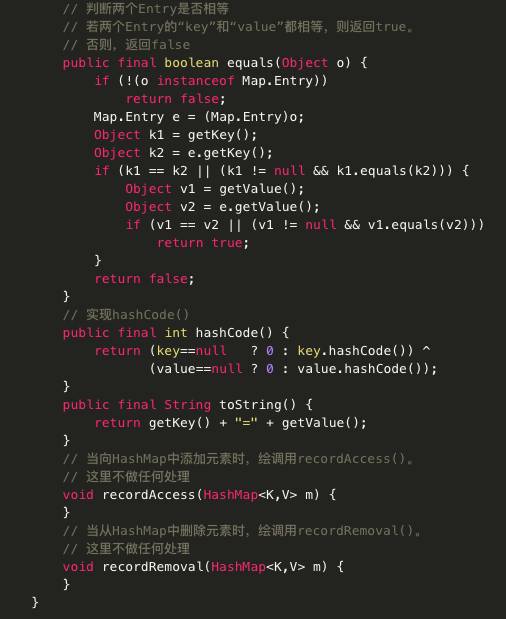
可以看出HashMap就是一个Entry数组,Entry对象中包含了键和值两个属性。
HashMap源码分析
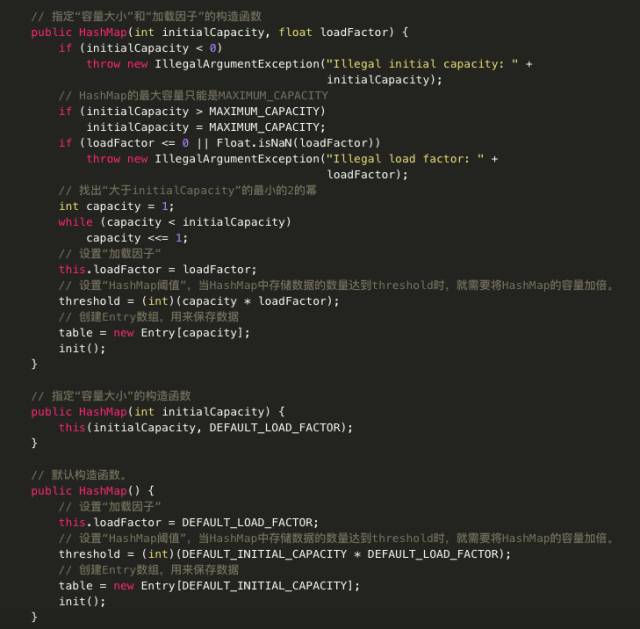
HashMap共有4个构造函数,如下:
· HashMap() 构造一个具有默认初始容量 (16) 和默认加载因子 (0.75) 的空 HashMap。
· HashMap(int initialCapacity) 构造一个带指定初始容量和默认加载因子 (0.75) 的空 HashMap。
· HashMap(int initialCapacity, float loadFactor) 构造一个带指定初始容量和加载因子的空 HashMap。
· HashMap(Map< extends K, extends V> m) 构造一个映射关系与指定 Map 相同的新 HashMap。
HashMap提供的API方法:
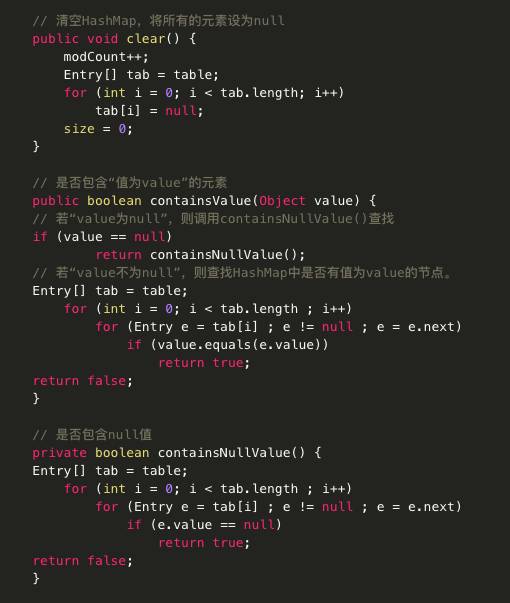
· void clear() 从此映射中移除所有映射关系。
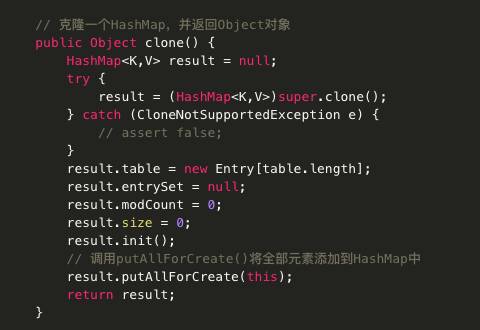
Object clone() 返回此 HashMap 实例的浅表副本:并不复制键和值本身。
· boolean containsKey(Object key) 如果此映射包含对于指定键的映射关系,则返回 true。
· boolean containsValue(Object value) 如果此映射将一个或多个键映射到指定值,则返回 true。
· Set entrySet() 返回此映射所包含的映射关系的 Set<Map.Entry> 视图。
· V get(Object key) 返回指定键所映射的值;如果对于该键来说,此映射不包含任何映射关系,则返回 null。
· boolean isEmpty() 如果此映射不包含键-值映射关系,则返回 true。
· Set keySet() 返回此映射中所包含的键的 Set<K> 视图。
· V put(K key, V value) 在此映射中关联指定值与指定键。
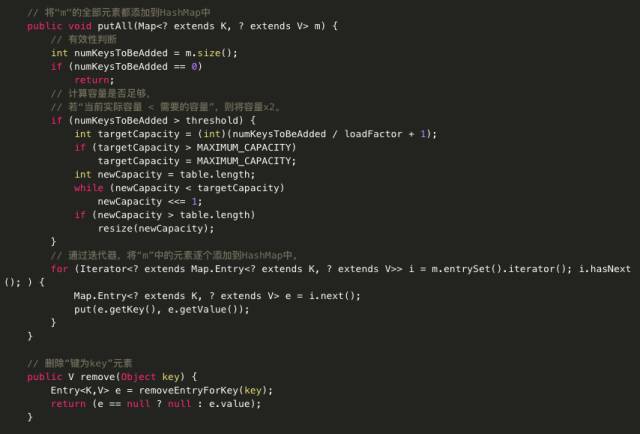
· void putAll(Map< extends K, extends V> m) 将指定映射的所有映射关系复制到此映射中,这些映射关系将替换此映射目前针对指定映射中所有键的所有映射关系。
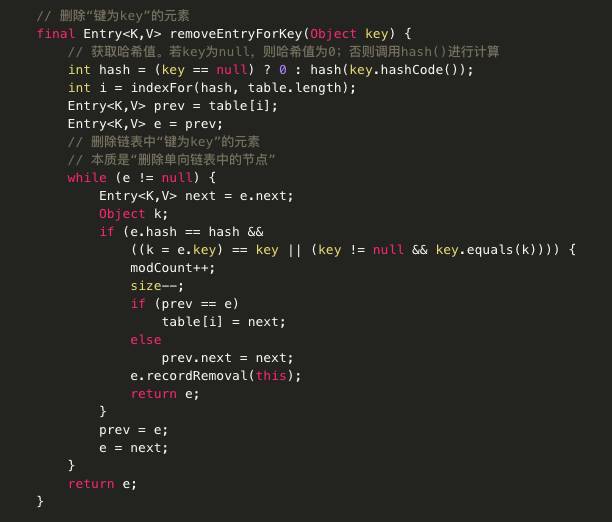
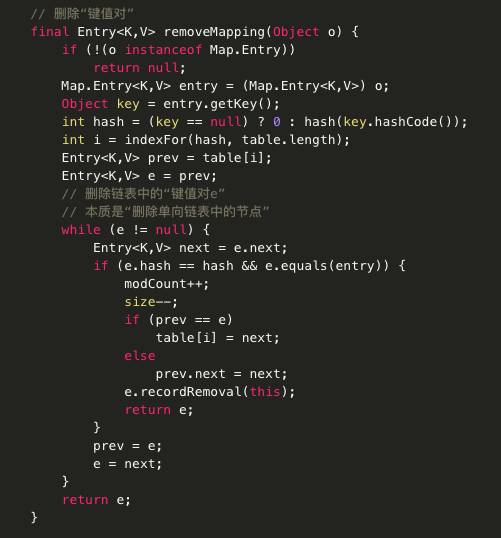
· V remove(Object key) 从此映射中移除指定键的映射关系(如果存在)。
· int size() 返回此映射中的键-值映射关系数。
· Collection values() 返回此映射所包含的值的 Collection 视图。
HashMap源码:
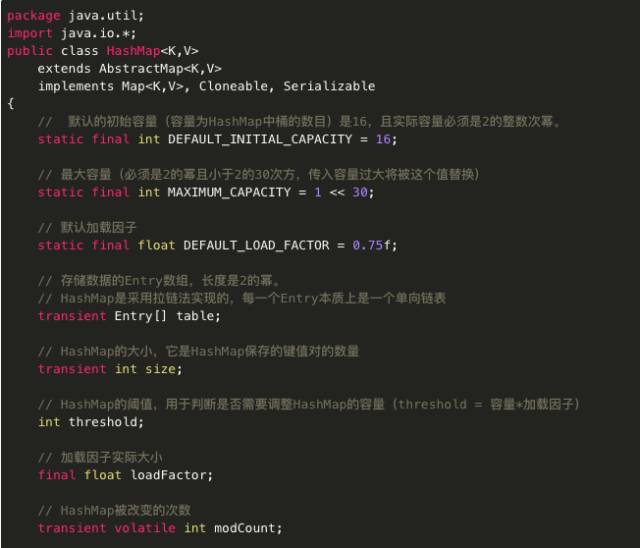
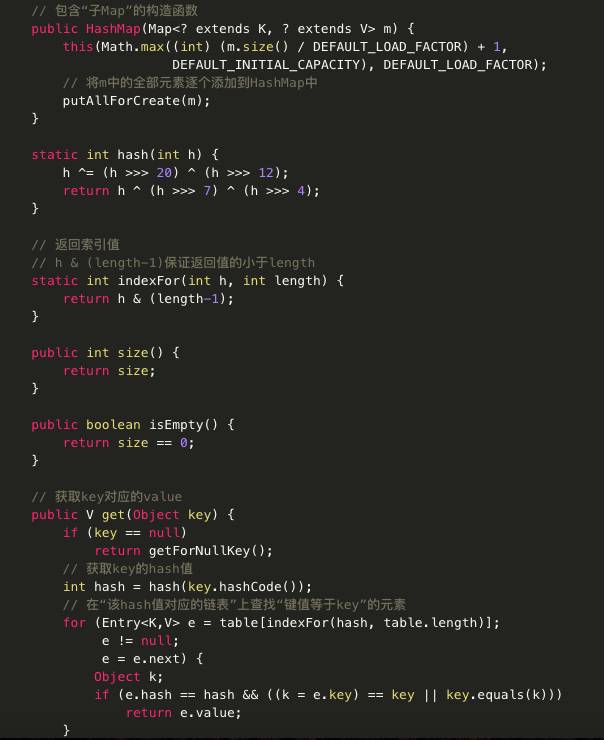
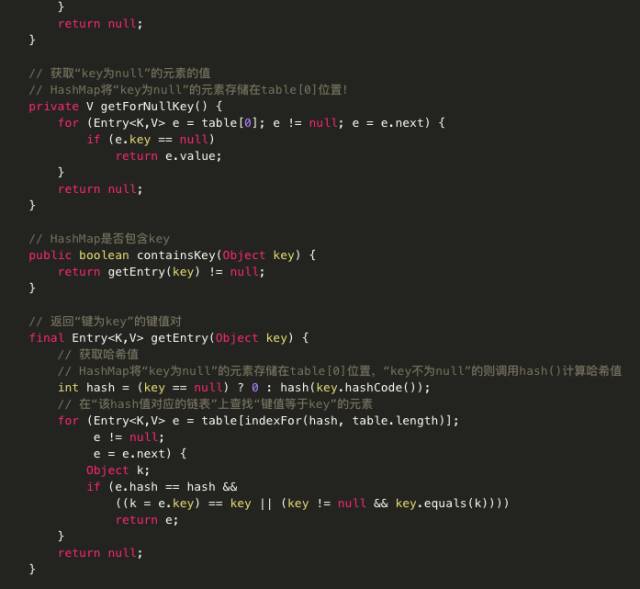
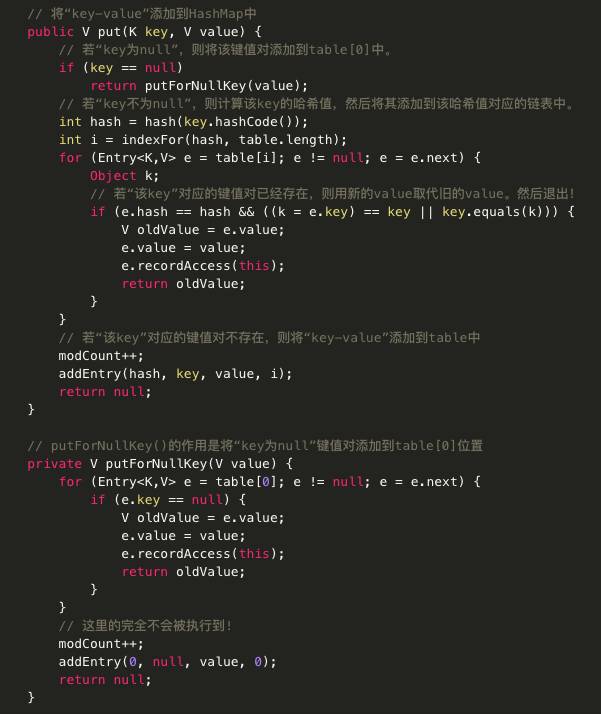
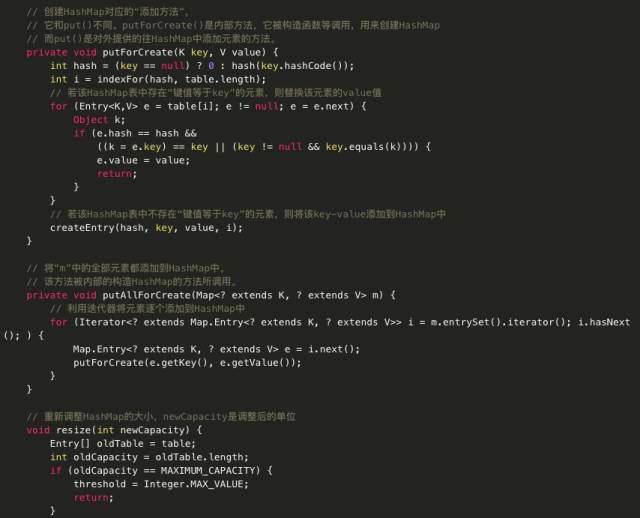

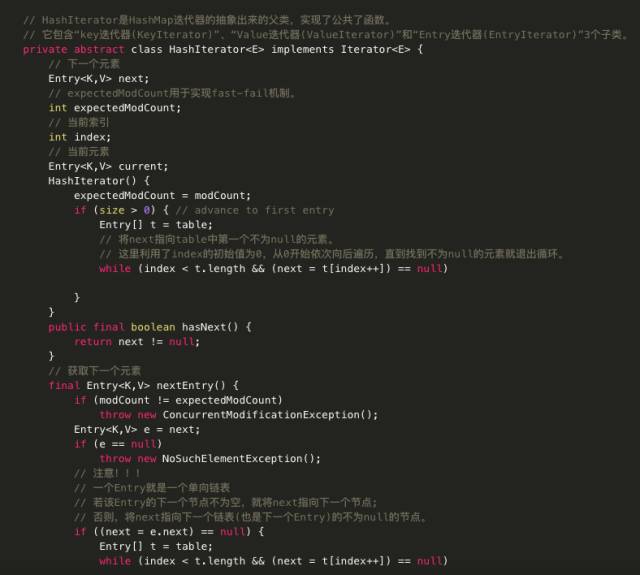
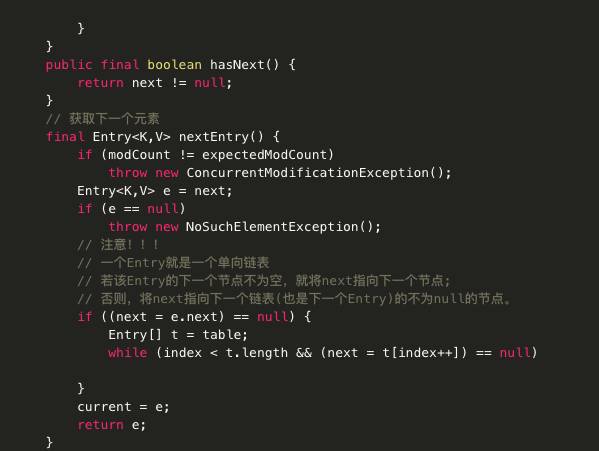
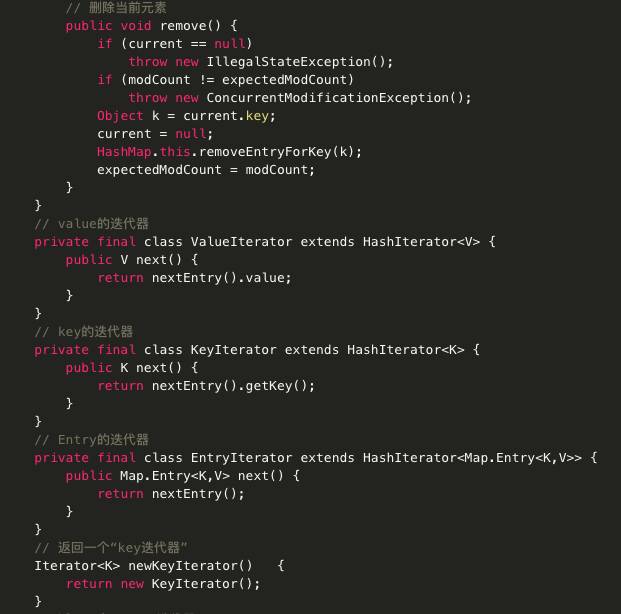
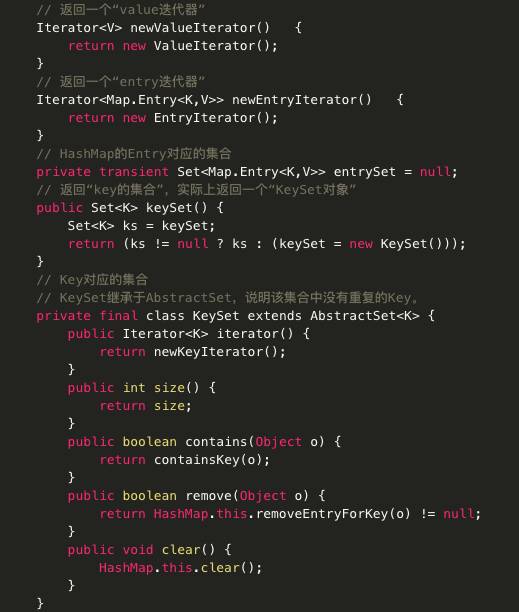
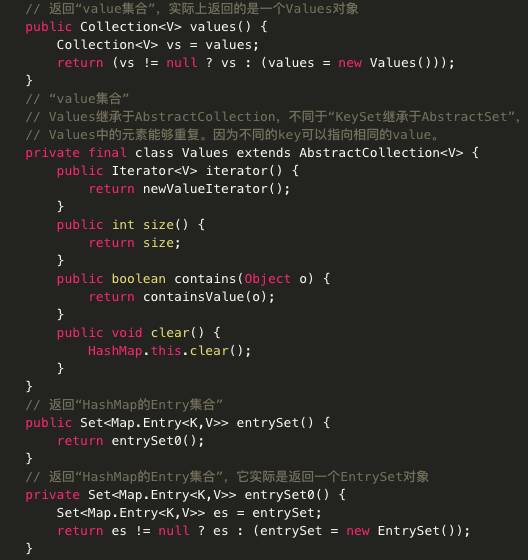
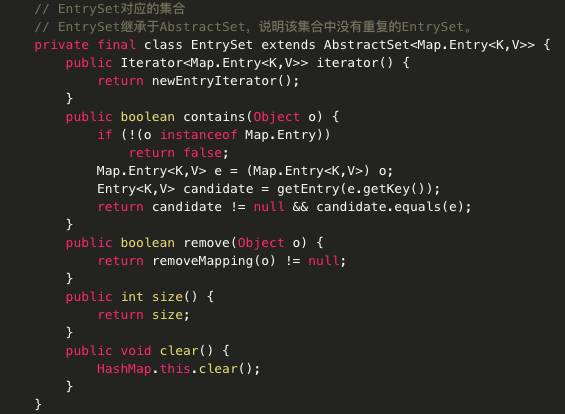
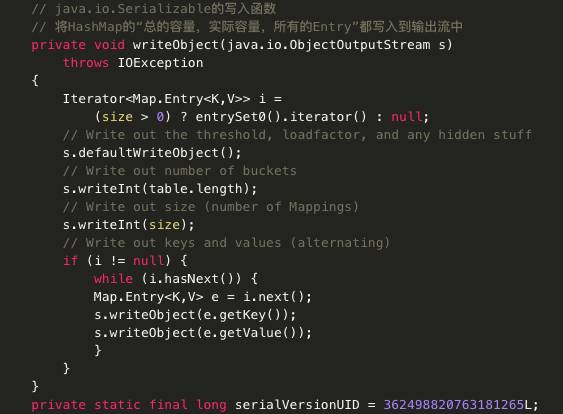
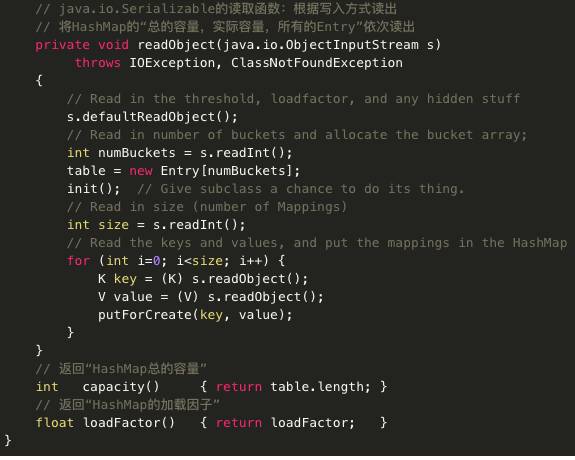
主要代码分析:
· public V get(Object key):
如果key不为null,则先求的key的hash值,根据hash值找到在table中的索引,在该索引对应的单链表中查找是否有键值对的key与目标key相等,有就返回对应的value,没有则返回null。 如果key为null,则直接从哈希表的第一个位置table[0]对应的链表上查找。记住,key为null的键值对永远都放在以table[0]为头结点的链表中,当然不一定是存放在头结点table[0]中。
· public V put(K key, V value)
如果key不为null,则同样先求出key的hash值,根据hash值得出在table中的索引,而后遍历对应的单链表,如果单链表中存在与目标key相等的键值对,则将新的value覆盖旧的value,并将旧的value返回,如果找不到与目标key相等的键值对,或者该单链表为空,则将该键值对插入到改单链表的头结点位置(每次新插入的节点都是放在头结点的位置),该操作是有addEntry方法实现的,它的源码如下:

参数bucketIndex就是indexFor函数计算出来的索引值,第2行代码是取得数组中索引为bucketIndex的Entry对象,第3行就是用hash、key、value构建一个新的Entry对象放到索引为bucketIndex的位置,并且将该位置原先的对象设置为新对象的next构成链表。第4行和第5行就是判断put后size是否达到了临界值threshold,如果达到了临界值就要进行扩容,HashMap扩容是扩为原来的两倍。
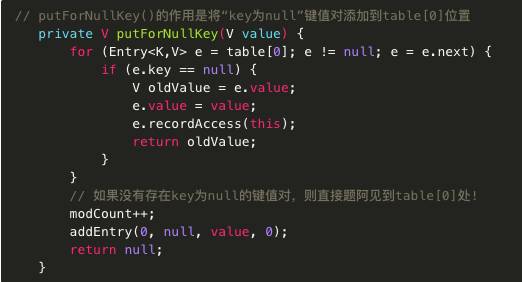
如果key为null,则将其添加到table[0]对应的链表中,由putForNullKey()实现。
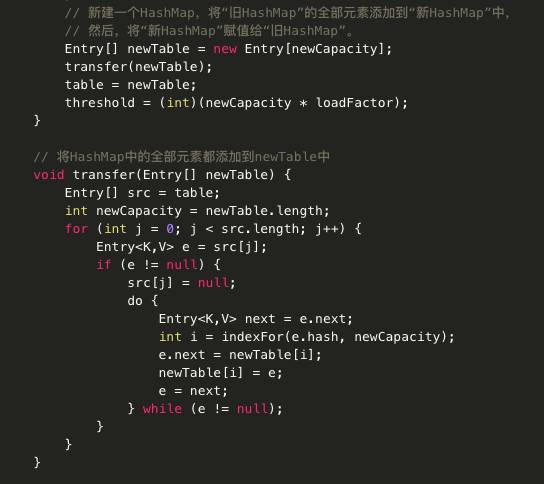
涉及到的resize扩容方法:

它新建了一个HashMap的底层数组,而后调用transfer方法,将就HashMap的全部元素添加到新的HashMap中(要重新计算元素在新的数组中的索引位置)。
扩容是需要进行数组复制的,非常消耗性能的操作,所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。
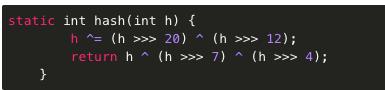
· hash()
· hash值找到对应索引
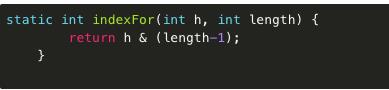
HashMap中则通过h&(length-1)的方法来代替取模,同样实现了均匀的散列,但效率要高很多,这也是HashMap对Hashtable的一个改进。length为2的整数次幂的话,h&(length-1)就相当于对length取模,这样便保证了散列的均匀,同时也提升了效率。
说明:length为2的整数次幂的话,为偶数,这样length-1为奇数,奇数的最后一位是1,这样便保证了h&(length-1)的最后一位可能为0,也可能为1(这取决于h的值),即与后的结果可能为偶数,也可能为奇数,这样便可以保证散列的均匀性,而如果length为奇数的话,很明显length-1为偶数,它的最后一位是0,这样h&(length-1)的最后一位肯定为0,即只能为偶数,这样任何hash值都只会被散列到数组的偶数下标位置上,这便浪费了近一半的空间。
往期精彩文章
0.点击进入留言抽送此书!
1.
2.
3.
4.
-END-
云栖社区
ID:yunqiinsight
云计算丨互联网架构丨大数据丨机器学习丨运维
这里“阅读原文”,查看本文及更多技术好文
以上是关于从代码层读懂HashMap的实现原理的主要内容,如果未能解决你的问题,请参考以下文章