阿里云机器学习平台——PAI平台
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里云机器学习平台——PAI平台相关的知识,希望对你有一定的参考价值。
在云栖TechDay第十五期活动上,阿里云iDST资深技术专家褚崴给大家带来了《阿里云机器学习平台》的分享,他以机器学习的概念入手展开了此次分享,演讲中他重点介绍了阿里云机器学习平台的基础架构和产品特点,并结合阿里内部的芝麻信用分、推荐系统等场景讲解了PAI平台的具体应用方案。
下文根据褚崴的演讲内容整理。
机器学习

图一 机器学习分类
机器学习简单来说就是,人教机器在我们积累的数据当中发现规律,然后能够辅助我们来做一些预测和决策。
机器学习笼统地讲可以分为三类:
1)有监督学习(supervised learning),是指每个样本都有对应的期望值,然后通过搭建模型,完成从输入的特征向量到目标值映射,典型的例子是回归和分类问题;
2)无监督学习(unsupervised learning),是指在所有的样本中没有任何目标值,我们期望从数据本身发现一些潜在的规律,比如说做一些简单的聚类;
3)增强学习(Reinforcement learning)相对来说比较复杂,是指一个系统和外界环境不断地交互,获得外界反馈,然后决定自身的行为,达到长期目标的最优化,其中典型的案例就是阿法狗下围棋,或者无人驾驶。
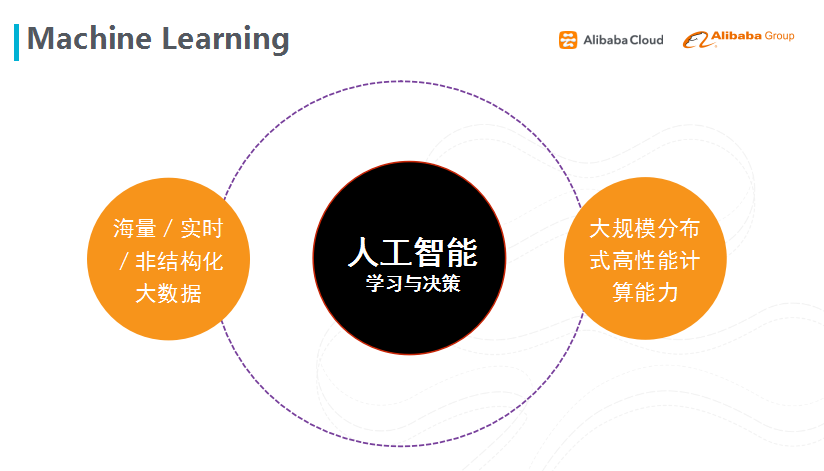
图二 机器学习兴起的因素
最近几年,机器学习比以前更火了,主要是我们在深度学习技术上取得了一定的进展,总结起来应该是三大因素:
第一个因素是数据的因素。互联网上每天生成海量的数据,有图像、语音、视频、还有各类传感器产生的数据,例如各种定位信息、穿戴设备;非结构化的文本数据也是重要的组成部分。数据越多,深度学习越容易得到表现好的模型。
第二个因素是大规模分布式高性能计算能力的提升。这些年来,GPU高性能计算、分布式云计算等计算平台迅猛发展,让大规模的数据挖掘和数据建模成为可能,也为深度学习的飞跃创造了物质基础;阿里云的愿景之一就是成为和水电煤一样的基础设施。
第三个因素是指算法上的创新。随着数据和计算能力的提升,算法本身也有了很大的进展,尤其在深度学习方面,譬如从脑神经学上得到的灵感,在激活函数上进行了稀疏性的处理,等等。
基于上述三点,人工智能又迎来了它的第二个春天。人工智能将以更快的速度进入我们的生产和生活中来,成为我们的眼睛,我们的耳朵,帮助我们更快捷地获取信息,辅助我们做出决策。机器学习平台产品也因此而产生,加速迭代过程,助力技术的发展。
机器学习平台:PAI 平台
图三 主流机器学习平台
阿里去年发布了自己的智能平台,其目的是为了加速整个创新过程,提高工作效率。该平台是基于阿里云的云计算平台,具有处理超大规模数据的能力和分布式的存储能力,同时整个模型支持超大规模的建模以及GPU计算。此外,该平台还具有社区的特点:实验结果可共享、社区团队相互协作。该智能平台主要分为三层,第一层是Web UI界面,第二层是IDST算法层,最后一层是ODPS平台层。下文更加详细地介绍。
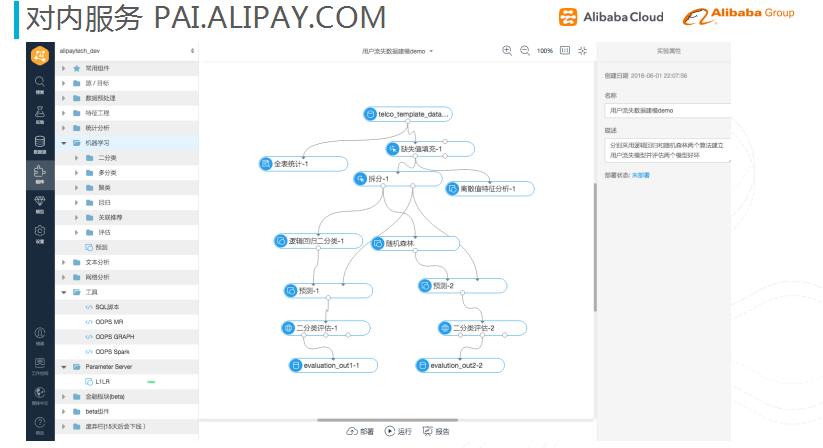
图四 PAI平台内部界面
上图所示的是PAI平台内部的界面。左边是主要功能区,中间是一个画布。使用者可以用鼠标将相应的组件拖拽到画布上,形成一个有向的工作流,完成从元数据到数据处理再到建模等一系列的数据挖掘工作。右边主要是用于设置组件内参数。
下面来介绍下它主要功能:
- 搜索功能:当我们有很多数据、表、实验时,可以通过搜索功能快速查找到你需要的资料;
- 实验列表:通过双击实验名称,在画布上显示原来的有向实验流图,可以继续之前没有完成的实验;
- 数据表,它类似于文件管理器,可以查看你所有的数据表;
- 算法和工具列表,包含了常用的机器学习算法组件等核心功能;
- 模型列表,通过该功能,使用者可以管理所有的模型,并且可以与其他使用者共享这些产品模型。
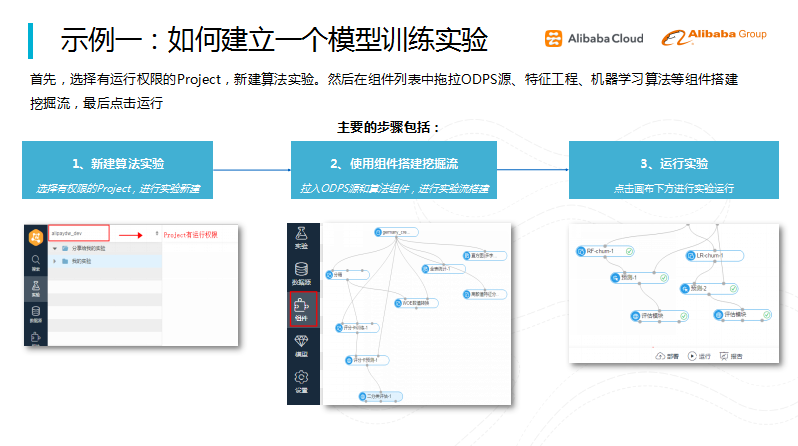
图五 建立一个模型训练实验
建立一个模型训练实验的步骤包括:首先,选择有运行权限的Project,新建算法实验;然后在组件列表中拖拉ODPS源、特征工程、机器学习算法等组件搭建挖掘流;最后点击运行即可。
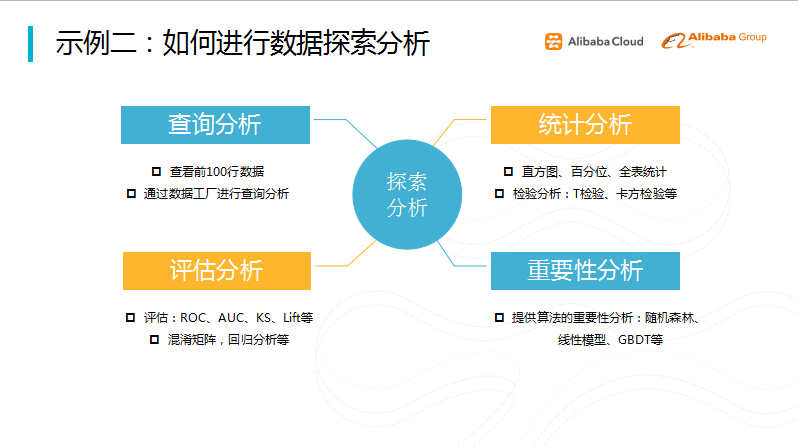
图六 数据探索分析
在整个过程当中,需要做进行一些数据的探索分析,所有的算法都会提供一个重要性的分析,提供特征排序。这里面最为重要的是评估分析,我们希望整个评估是全面而准确的。
图形工作流的优势在于,使用者可以很容易地进行循环实验。因为在模型优化时,需要多次循环迭代优化,通过该模板,每次修改相应的参数再进行重复实验,大大提高了工作效率。
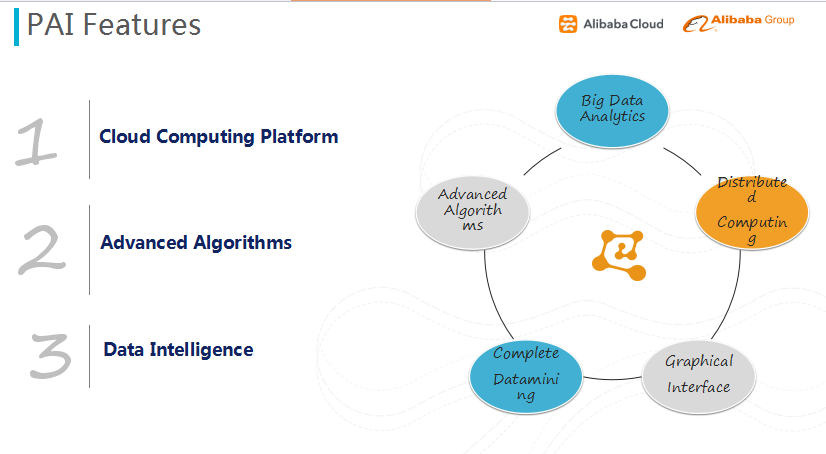
图七 PAI平台特点
该平台通过交互的界面降低了技术门槛,使用者可以轻松实现数据挖掘的工作,而无需太多经验;其次,其内嵌的算法,都是经过阿里内部多年的淬炼,在性能和准确率上都有较大的提升;最后是数据智能,该平台提供了从元数据到模型部署整套流程,通过提供基本的组件,使用者可以搭建各个垂直场景下的解决方案。
我们的客户主要包括以下几部分:一类是传统的大型企业和政府部门,如中石化、中石油、气象局等;另一类是中小企业,主要是公共云上的初创用户;以及一些个人用户,如数据科学家,研究人员等。
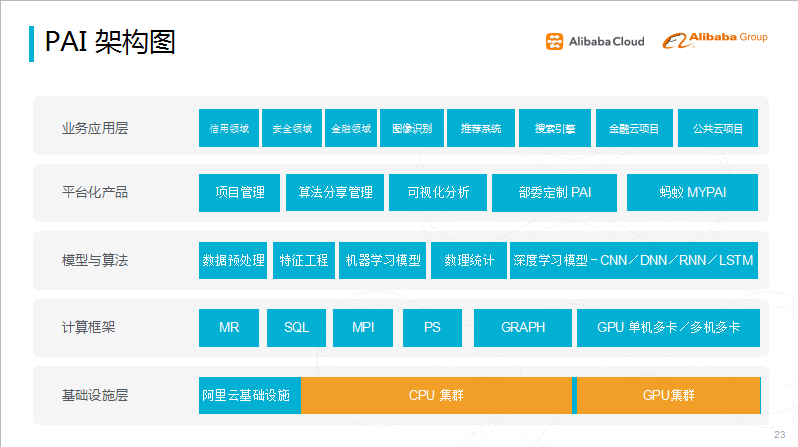
图八 PAI平台架构图
上图是PAI整体框架图,最底层是基础设施层,包括CPU和GPU集群;其上一层是阿里提供的计算框架,包括MaxCompute的MapReduce/SQL/MPI等计算方式;中间一层是模型算法层,包含数据预处理,特征工程,机器学习算法等基本组件,帮助使用者完成简单的工作;平台化产品主要是项目管理、算法模型分享,以及一些特定的需求;最上层是应用层,阿里内部的搜索、推荐、蚂蚁金服等项目在进行数据挖掘工作时,都是依赖PAI平台产品。
目前依托于PAI机器学习平台,提供基本组件,通过拖拽的操作,完成工作流程的整体布局;同时在垂直场景下,提供一些更为专业的组件,例如在文本分析方面,我们提供了一套完整的文本分析的算法组件。
产品特点
接下来,介绍一下参数服务器和分布式深度学习的算法产品两部分。
去年我们基于非常流行的深度学习开源工具Caffe做了一版改造,将单机版的Caffe改造成了多机版的Caffe,内部我们称其为Pluto。在GPU和机器之间的通信进行了相应的开发,使其支持流水式通信,在必要时可以占满带宽,减少空闲等待时间,该产品同样支持DNN、CNN、RNN等常用的机器学习模型。
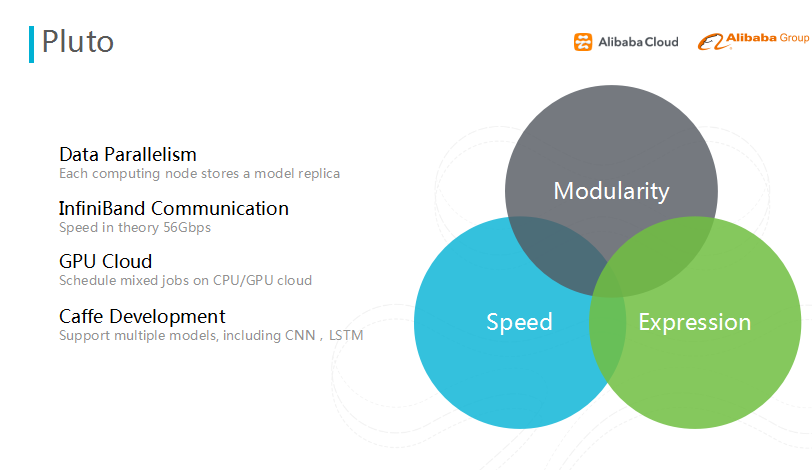
图九 Pluto
Pluto主要的特点在于数据的分片,每个GPU只处理一部分数据。如果我们采用16个GPU,则处理数据的规模就比以前扩大了16倍;另外,采用了InfiniBand来做机与机之间的通信,理论上具有56G通信的带宽。GPU的调度,是由阿里云集群调度管理完成的,摆脱了单机的模式。在Pluto做开发时,使用方式完全兼容Caffe,扩展性很强。
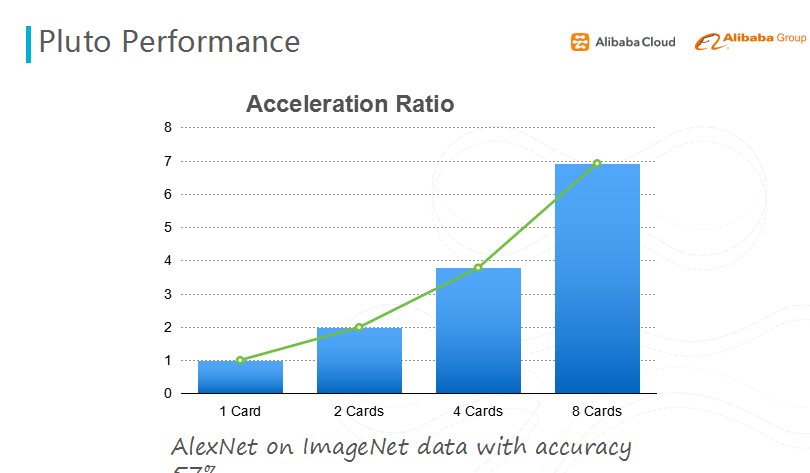
图十 Pluto 性能提升
上面是一个加速比的图。我们做了一个对比实验:如果你用8卡跟1卡的性能做比较,你会得到将近7倍的性能提升。
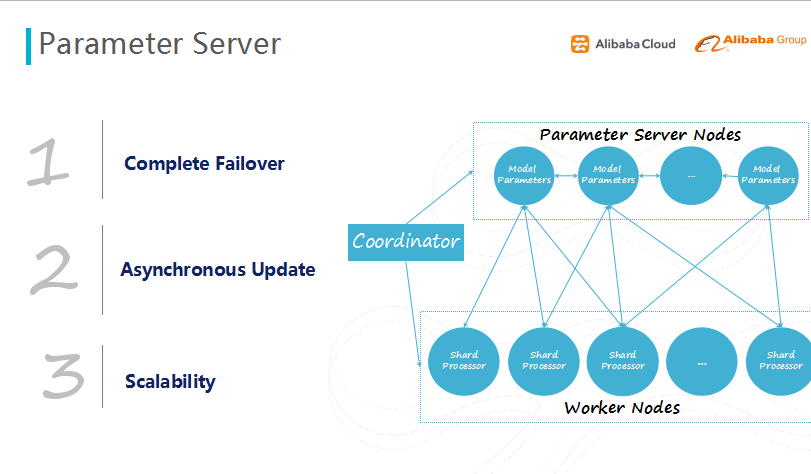
图十一 参数服务器
下面向大家介绍下参数服务器,其主要思想是:不仅仅是进行数据并行,同时将模型分片,将大的模型分为多个子集,每个参数服务器只存一个子集,全部的参数服务器聚合在一起拼凑成一个完整的模型。该系统主要的创新点在于失败重试的功能,在分布式系统上,上百个节点协同工作时,经常会出现一个或几个节点挂掉的情况,如果没有失败重试机制,任务就会有一定的几率失败,需要重新提交任务到集群调度。
失败重试是将每个节点的状态备份到相邻(前后)的节点,当个别节点死掉后,重启一个新的节点,同时从原节点相邻的节点获取所存储的状态,理论上可以实现任务的100%完成。
还有一个功能是异步迭代,无需等待全部节点完成任务,当大部分节点完成任务时,就可以直接更新对应的模型,这样可以不需要等待慢机的结果,从而摆脱慢机的影响,提升效率。
应用案例
下面介绍在阿里内部的三个应用场景。
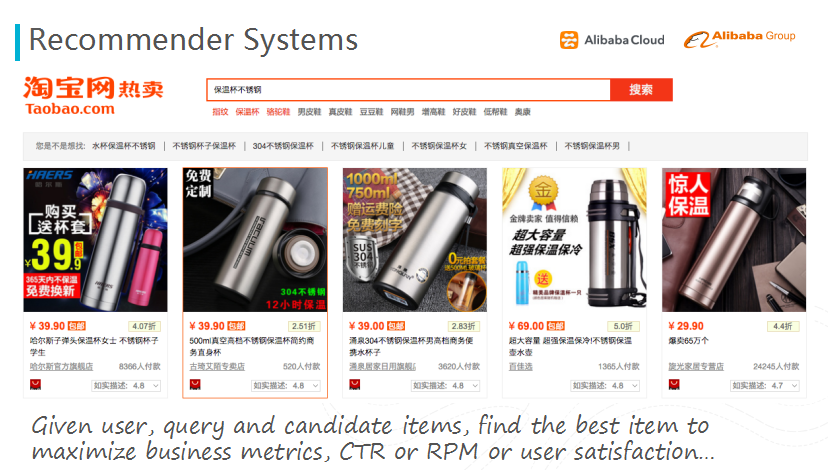
图十二 应用一:推荐系统
第一个应用是推荐系统,主要是参数服务器在推荐系统内的应用。当在淘宝购物时,经查询显示的商品一般都是非常个性化的推荐,它是基于商品的信息和用户的个人信息以及行为信息三者的特征提取。这个过程中形成的特征一般都是很大,在没有参数服务器时,采用的是MPI实现方法,MPI中所有的模型都存在于一个节点上,受限于自身物理内存上限,它只能处理2000万个特征;通过使用参数服务器,我们可以把更大模型(比如说2亿个特征的模型),分散到10个或者是100个参数服务器上,打破了规模的瓶颈,实现了性能上的提升。
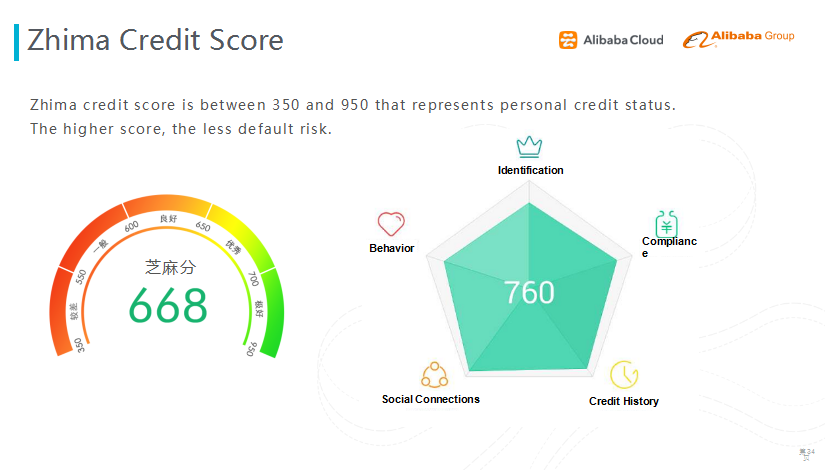
图十三 应用二:芝麻信用分
第二个应用是芝麻信用分。芝麻信用分是通过个人的数据来评估你个人信用。做芝麻信用分时,我们将个人信息分成了五大纬度:身份特质、履约能力、信用历史、朋友圈状况和个人行为进行评估信用等级。
在去年,我们利用DNN深度学习模型,尝试做芝麻信用分评分模型。
输入是用户原始的特征,基于专家知识将上千维的特征分为五部分,每部分对应评分的维度。我们通过一个本地结构化的深度学习网络,来捕捉相应方面的评分。由于业务对解释性的需求,我们改变了模型的结构,在最上面的隐层,一共有五个神经原,每个神经原的输出都对应着它五个维度上面值的变化;再往下一层,是改变维度分数的因子层;用这种本地结构化的方式,维持模型的可解释性。

图十四 应用三:光学文字识别
最后一个应用是图象上面的光学文字的识别。我们主要做强模板类、证件类的文字识别,以及自然场景下文字的识别。强模板服务(身份证识别)在数加平台上也提供了相应的入口,目前可以达到身份证单字准确率99.6%以上、整体的准确率93%。
在识别中用到的是CNN模型,但其实整个流程特别长,不是深度学习一个建模就能解决的问题,包括版面分析、文字行的检测、切割等等技术。在CNN训练中,我们采用了多机多卡分布式算法产品,之前利用一千万个图像训练CNN模型,大约需要耗时70个小时,迭代速度非常缓慢;采用分布式8卡产品之后,不到十个小时就可以完成模型训练。
总结
阿里云机器学习平台既支持深度学习,又支持CPU、GPU任务混合调度。接下来发展的方向,是数据智能的方向,一是提供智能化的组件,例如将参数调优的工作也替用户完成;另一个就是开发垂直应用领域需要的算法组件,逐渐形成行业解决方案。
关于分享者
褚崴博士,现任职阿里云iDST资深技术专家,负责分布式机器学习平台产品的研发。之前先后曾任职美国微软首席科学家,美国雅虎实验室科学家,美国哥伦比亚大学副研究科学家。2003年至2006年,在英国伦敦大学学院Gatsby Unit做博士后研究工作,2003年在新加坡国立大学获得博士学位,统计机器学习方向。在顶级期刊和国际会议上累计发表40余篇论文,ACM WSDM 2011年会获得最佳论文奖。2015年入选浙江省“千人计划”创新人才,2016年入选第十二批国家“千人计划”创新长期类人才。
以上是关于阿里云机器学习平台——PAI平台的主要内容,如果未能解决你的问题,请参考以下文章