阿里云机器学习平台PAI之分类实践
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里云机器学习平台PAI之分类实践相关的知识,希望对你有一定的参考价值。
💜这篇博客是机器学习PAI的实践部分,主要演示的是分类算法在平台上的使用方法,对往期内容感兴趣的小伙伴可以查看一下内容👇:
- hadoop专题: hadoop系列文章.
- spark专题: spark系列文章.
- 阿里云系列: 阿里云MaxComputer SQL学习之DDL.
- 阿里云系列: 阿里云MaxComputer SQL学习之DML.
- 阿里云系列: 阿里云MaxComputer SQL学习之内置函数.
- 阿里云系列: 阿里云DataWorks介绍.
- 阿里云系列: 阿里云DataWorks学习之平台实践.
- 阿里云系列: 阿里云Quick BI理论学习.
- 阿里云系列: 阿里云Quick BI学习之报表制作.
- 阿里云系列: 阿里云机器学习平台PAI之理论基础.
💖自己动手学完一遍之后,发现这个平台所提供的功能太强大了,主流的模型方法,特征工程,评估方法等很全面。让我们开始今日的学习吧!
目录
1. 实验目的
实验借助葡萄酒的11种指标并通过线性支持向量机和逻辑回归多分类方法对不同类别的葡萄酒建立模型,检验此模型效果,以此达到通过模型可以预测葡萄酒类别的目的。
2. 导入数据
- 进入DataWorks的数据开发界面

- 创建数据表
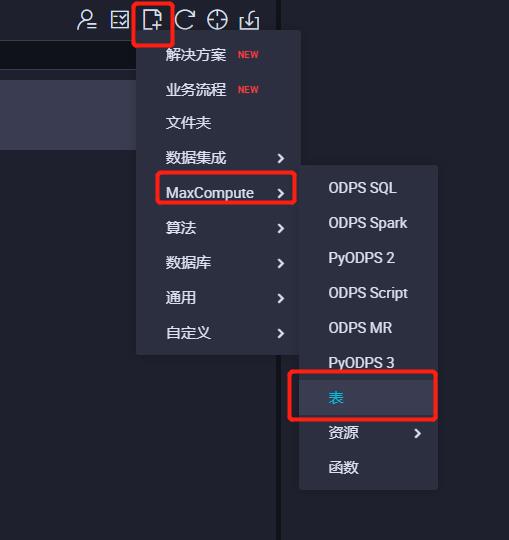
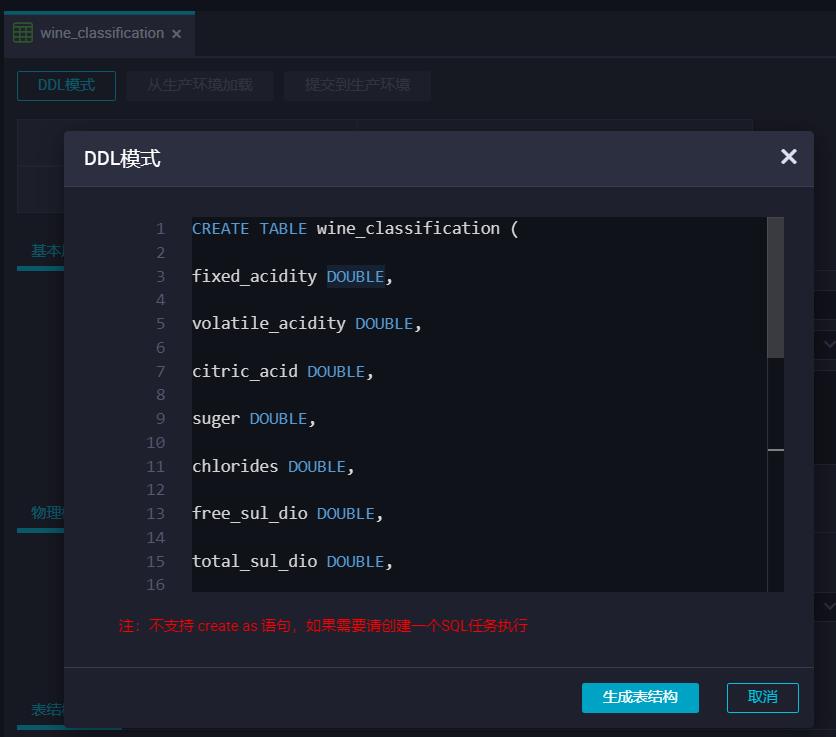
- DDL模式生成表,提交到生产环境
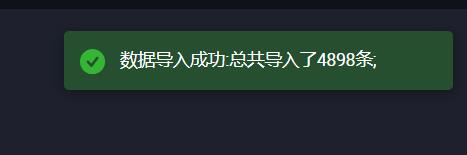
- 将数据导入表中

- 导入成功
- 预览数据

3. 二分类分析
实验目标:对原始数据上已有的标签(即classification字段,该字段有3-9共7个类别)进行分类,为消除量纲而进行归一化操作后进行切分比例为0.8的拆分,用80%的数据进行分析建模,用剩余20%的数据对建立的模型进行检验,具体通过查看这20%的数据在classification字段上的准确率(即模型预测出的类别和这葡萄酒本身的类别符合程度)的方式明确模型效果
- 进入平台
- 进入项目
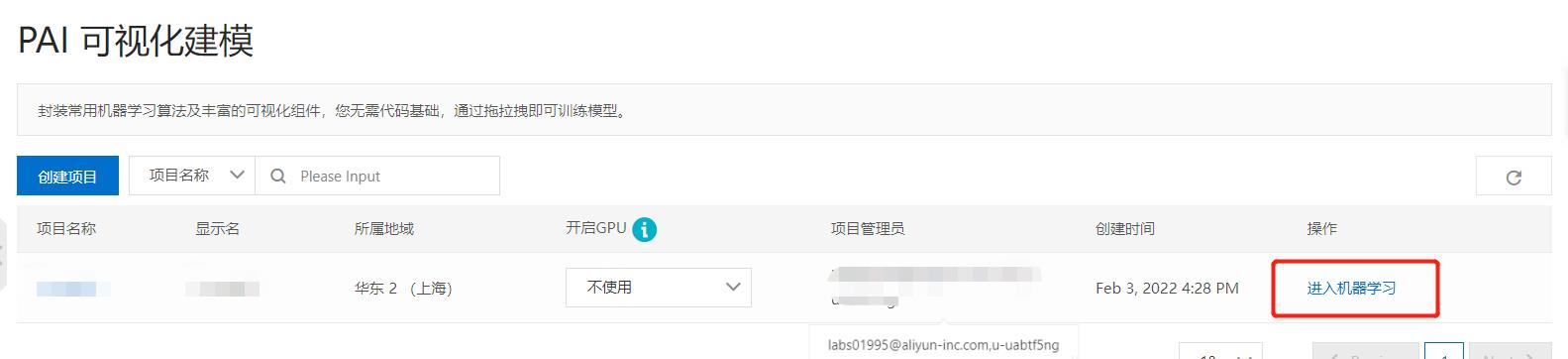
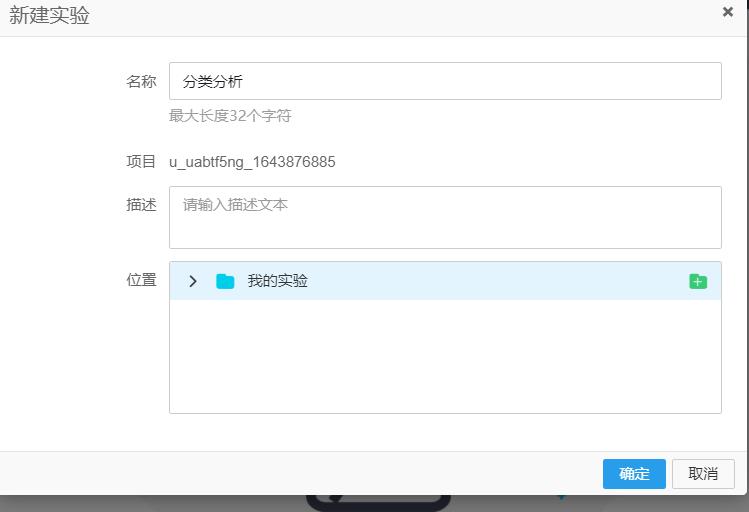
- 新建实验
- 读取数据表,将它拽过来改个名字
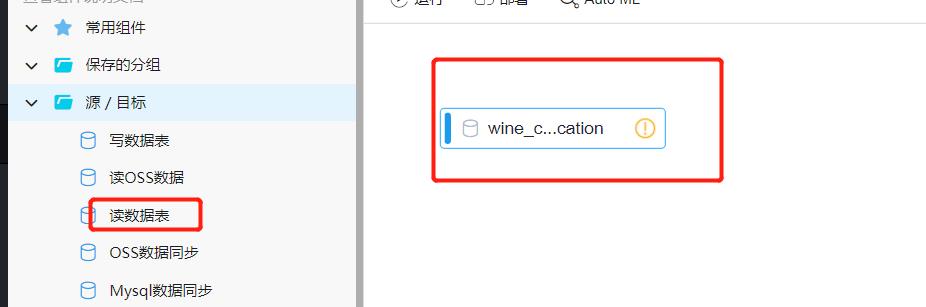
- 设置该节点的数据表为wine_classification

- 我们这里做的是二分类,所以先将classification分为3、4、5、6一类和7、8、9一类,分别标为0和1,拖拽一个sql组件,写入sql语句将数据分为两类。
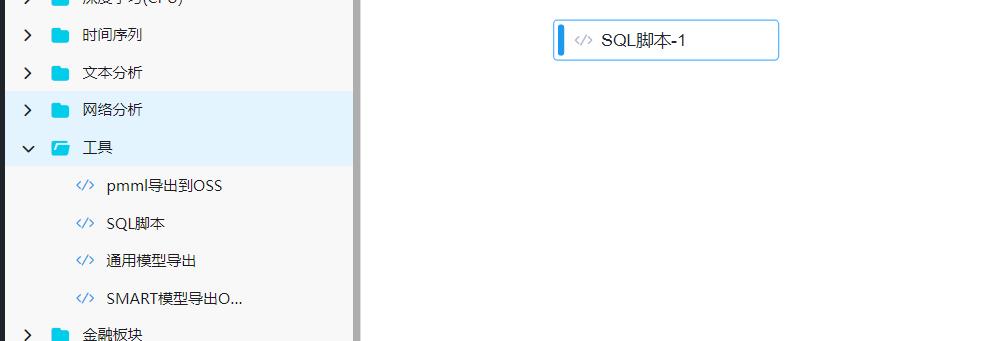
--3、4、5、6一类和7、8、9一类,分别标为0和1
select
fixed_acidity,volatile_acidity,citric_acid,suger,chlorides,
free_sul_dio,total_sul_dio,density,ph,sulphates,alcohol,
(case when classification > 6 then 1 else 0 end) as grade
from $t1
- 数据标记成功

- 数据归一化

- 选择归一化字段

- 拆分训练集和测试集(80%训练,20测试)

拆分组件有两个输出口,左边输出口为用来建模的80%数据,右边输出口为预测的20%数据。
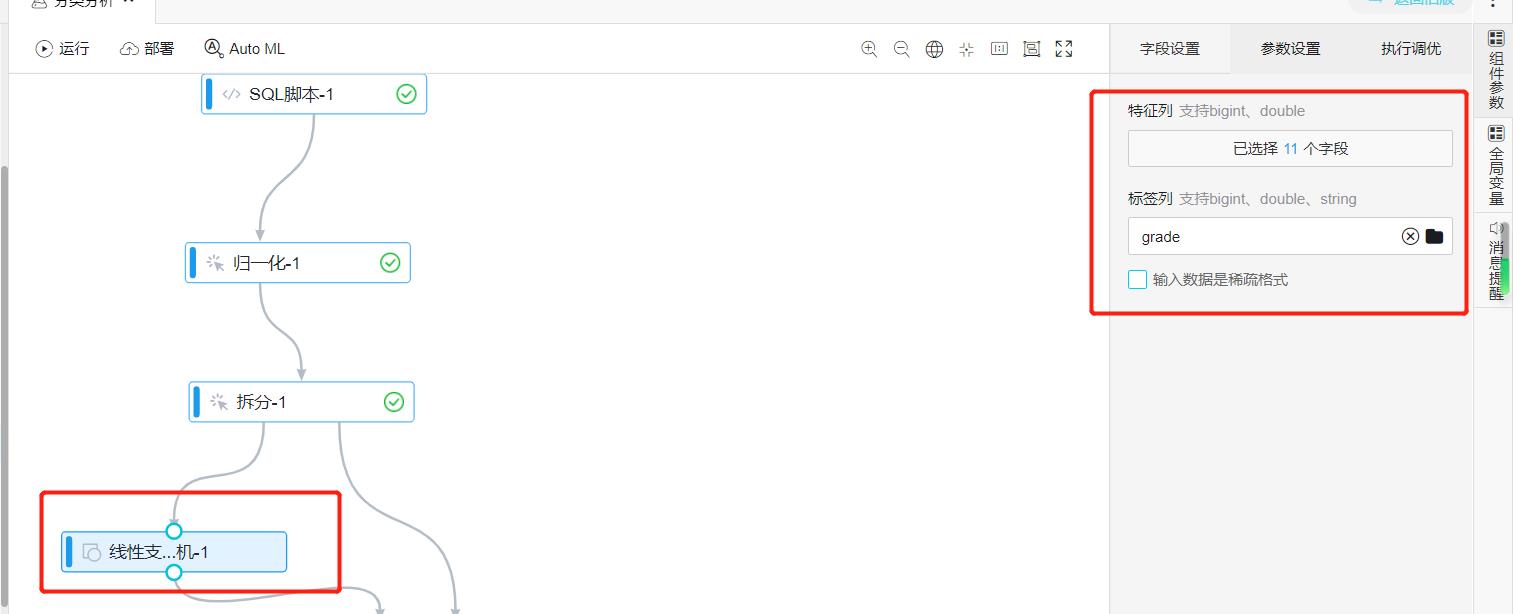
- 选择支持向量机模型,设置特征列和标签列
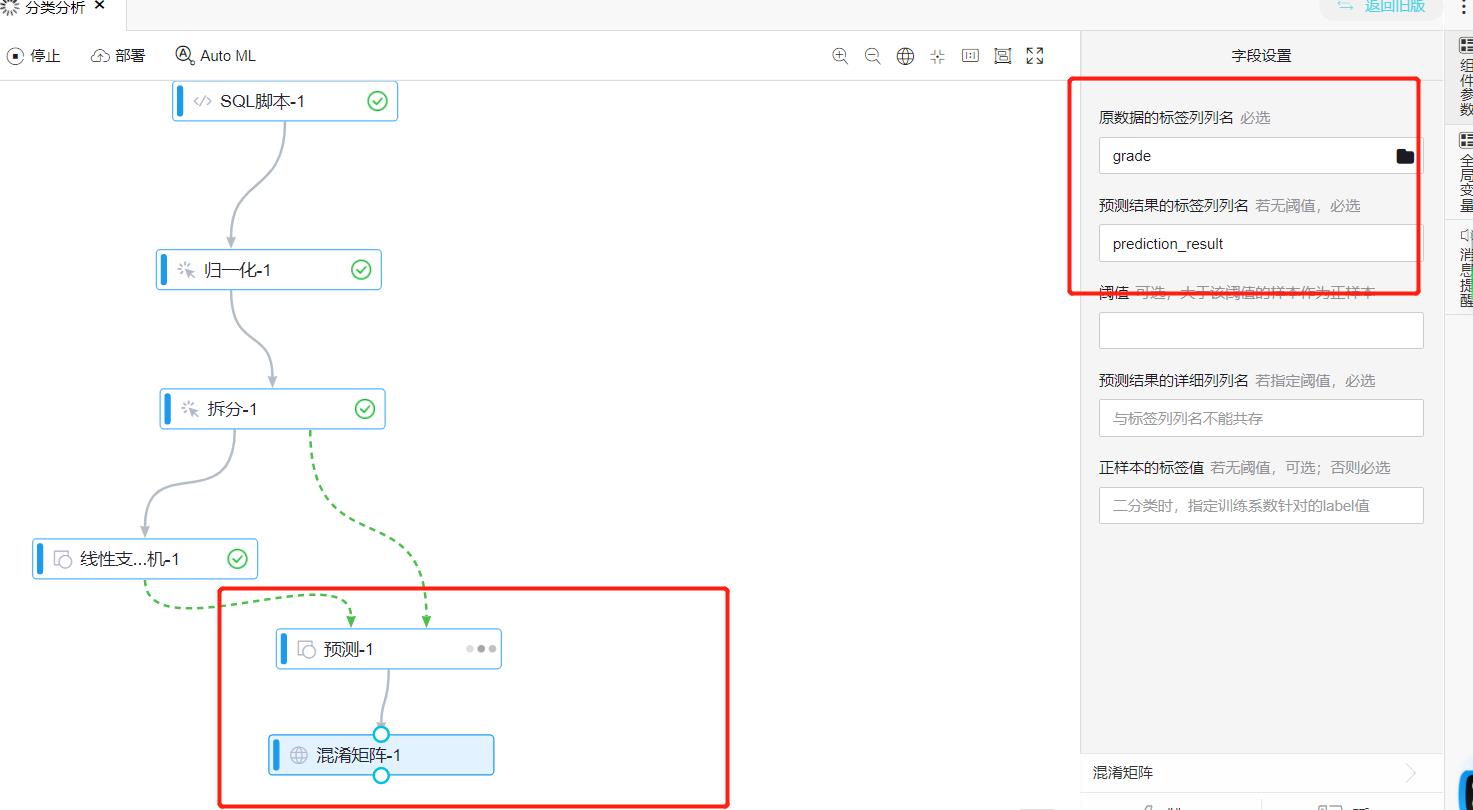
- 预测和混淆矩阵设置相同
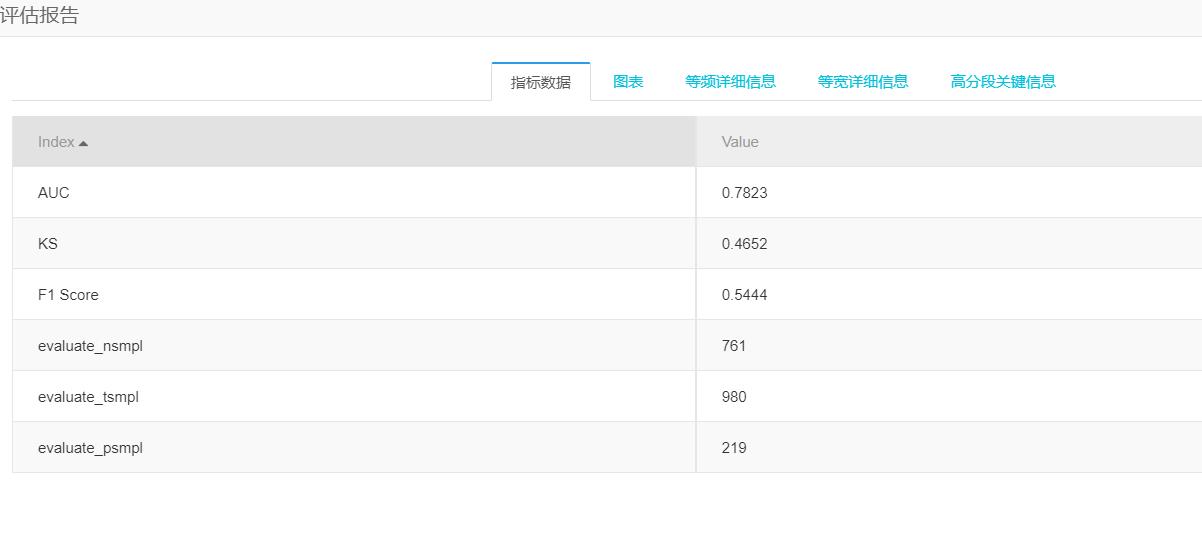
- 可添加评估模块,评估结果
4. 多分类实践
多分类实践和二分类一样的,主要的区别在于导入数据那一块,我们可以指定分成几类,比如为3、4、5一类,6、7一类,8、9一类,然后采用sql语句设置标签列。
5. 参考资料
《阿里云全球培训中心》
《机器学习PAI平台产品手册》
以上是关于阿里云机器学习平台PAI之分类实践的主要内容,如果未能解决你的问题,请参考以下文章