干货:解码OneData,阿里的数仓之路。
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货:解码OneData,阿里的数仓之路。相关的知识,希望对你有一定的参考价值。
免费开通大数据服务:https://www.aliyun.com/product/odps
据IDC报告,预计到2020年全球数据总量将超过40ZB(相当于4万亿GB),这一数据量是2013年的10倍。正在“爆炸式”增长的数据的潜在巨大价值正在被发掘,它有可能成为商业世界的“新能源”,变革我们的生产,影响我们生活。当我们面对如此庞大的数据之时,如果我们不能有序、有结构的进行分类组织和存储,那么在价值被发现前,也许数据成本灾难已经来临。它犹如堆积如山的垃圾,给我们企业带来的是极大的成本,而且非常难以消费和发掘价值,也许数据更可悲的命运是在价值发现之前它以死去。不得已的历史数据清理还在进行中吗?

那么,企业大数据体系的数据架构应该如何建立?如何保障数据快速支撑业务并且驱动业务发展?在2016数据库技术大会上,数据中台的高级技术专家王赛结合阿里数据的实践成果,按照背景、方法思路以及如何落地实现、效果如何的逻辑,为大家详细介绍阿里数据中台的秘密武器——OneData体系。
背景》》》》》》》
在企业发展初期,数据研发模式一般紧贴业务的发展而演变的,数据体系也是基于业务单元垂直建立,不同的垂直化业务,带来不同的烟囱式的体系。但随着企业的发展,一方面数据规模在快速膨胀,垂直业务单元也越来越多,另一方面基于大数据的业务所需要的数据不仅仅是某个垂直单元的,使用数据类型繁多(Variety)的数据才能具备核心竞争力。跨垂直单元的数据建设接踵而至,混乱的数据调用和拷贝,重复建设带来的资源浪费,数据指标定义不同而带来的歧义、数据使用门槛越来越高……这些问题日益凸显,成为企业发展迫在眉睫必须要解决的问题。
1)数据标准不统一
在建立OneData之前,阿里数据有30000多个指标,其中,即使是同样的命名,但定义口径却不一致。例如,仅uv这样一个指标,就有十几种定义。带来的问题是:都是uv,我要用哪个? 都是uv,为什么数据却不一样?
2)服务业务能力
由于数据模式是跟着垂直业务,导致一开始只支持了淘宝、天猫、1688等少数业务团队。而更多有个性化需求的业务团队却无法提供更多支持。
3)计算存储成本
由于没有统一的规范标准管理,造成了重复计算等资源浪费。而数据表的层次、粒度不清晰,也使得重复存储严重,仅淘系的数据表就超过了25000张,集团总数据的存储量每年以2.5倍的速度在增长,可以预见的未来的将会带来巨大的数据成本负担,我们不得不去做一些改变。
4)研发成本
每个工程师都需要从头到尾了解研发流程的每个细节,对同样的“坑”每个人都会重新踩一遍,对研发人员的时间和精力成本造成浪费
建立的方法和思路》》》》》》》》
基于这样的问题和挑战,阿里集团规划建设一个全集团的全域数据公共层,将公共的数据、计算沉淀于此,降低数据存储和计算成本,提升数据互通和消费的效率,从而支撑快速数据业务应该的创新。公共层中重要的一环是数据模型的构建,那么我们先从行业看看一些方法体系和经验:
1)他山之石——行业内是如何做的?
A、实体关系(ER)模型
数据仓库之父Immon的方法从全企业的高度设计一个3NF模型,用实体加关系描述的数据模型描述企业业务架构,在范式理论上符合3NF,它与OLTP系统中的3NF的区别,在于数据仓库中的3NF上站在企业角度面向主题的抽象,而不是针对某个具体业务流程的实体对象关系抽象,它更多的是面向数据的整合和一致性治理,正如Immon所希望达到的:“single version of the truth”。但是要采用此方法进行构建,也有其挑战:
- 需要全面了解企业业务和数据
- 实施周期非常长
- 对建模人员的能力要求也非常高
B、维度模型
维度模型是数据仓库领域另一位大师Ralph Kimall所倡导,它的《The DataWarehouse Toolkit-The Complete Guide to Dimensona Modeling》是数据仓库工程领域最流行的数仓建模经典。
维度建模以分析决策的需求出发构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。典型的代表是我们比较熟知的星形模型,以及在一些特殊场景下适用的雪花模型。
C、DataVault
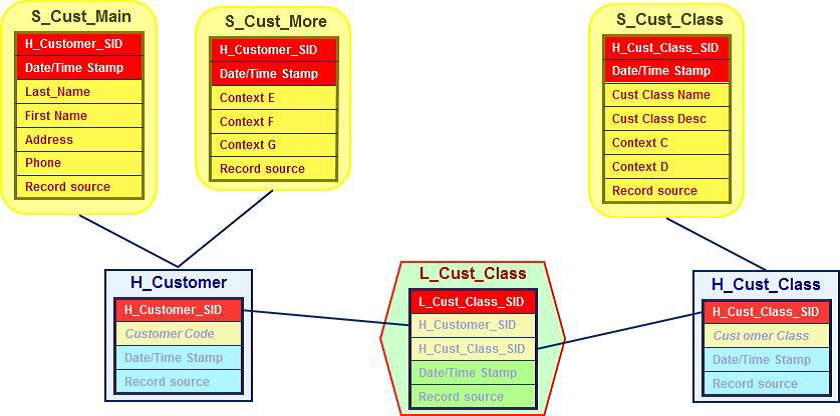
DataVault是Dan Linstedt发起创建的一种模型方法论,它是在ER关系模型上的衍生,同时设计的出发点也是为了实现数据的整合,并非为数据决策分析直接使用。它强调建立一个可审计的基础数据层,也就是强调数据的历史性可追溯性和原子性,而不要求对数据进行过度的一致性处理和整合;同时也基于主题概念将企业数据进行结构化组织,并引入了更进一步的范式处理来优化模型应对源系统变更的扩展性。它主要由:Hub(关键核心业务实体)、Link(关系)、Satellite(实体属性)三部分组成 。
D、Anchor模型
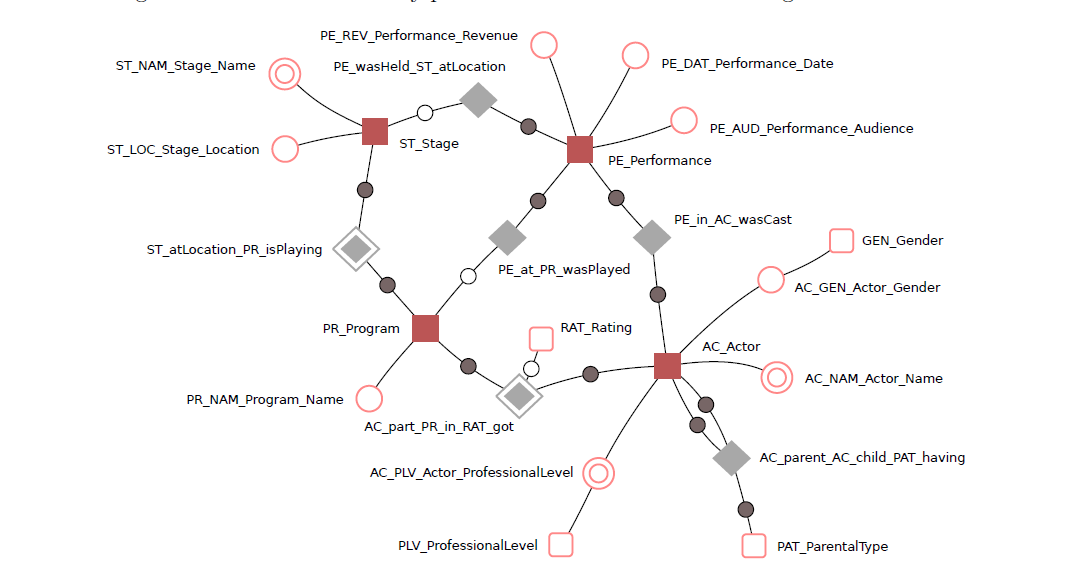
Anchor模型是由Lars. R?nnb?ck设计的,初衷是设计一个高度可扩展的模型,核心思想:所有的扩展只是添加而不是修改,因此它将模型规范到6NF,基本变成了K-V结构模型。Anchor模型由:Anchors 、Attributes 、Ties 、Knots 组成,相关细节可以参考《Anchor Modeling-Agile Information Modeling in Evolving Data Environments》
2)阿里的数仓模型体系要如何构建?
阿里巴巴集团在很早就已经把大数据做为战略目标实施,而且其各个业务也非常依赖数据支撑运营,那么阿里究竟采取何种方法构建自己的体系?阿里的数据仓库模型建设经历的多个发展周期:
第一阶段:完全应用驱动的时代,阿里巴巴第一代的数据仓库系统构建在Oracle上,数据完全以满足报表需求为目的出发,将数据以与源结构相同的方式同步到Oracle后,我们叫ODS(Operational Data Store)层,数据工程师基于ODS数据进行统计,基本没有模型方法体系,完全基于对Oralce数据库特性的利用进行数据存储和加工,部分采用了一些维度建模的缓慢变化维方式进行历史数据处理。那时候的数据架构只有两次层ODS+DSS。
第二阶段:随着阿里业务的快速发展,数据量也在飞速增长,性能已经是一个较大问题,因此引入了当时MPP架构体系的Greenplum,同时阿里的数据团队也在着手开始进行一定的数据架构优化,希望通过一些模型技术改变烟囱式的开发模型,消除一些冗余,提升数据的一致性。来做传统行业数仓的工程师,开始尝试将工程领域比较流行的ER模型+维度模型方式应用的阿里集团,构建出一个四层的模型架构ODL(操作数据层)+BDL(基础数据层)+IDL(接口数据层)+ADS(应用数据层)。ODL保持和源系统保持一致,BDL希望引入ER模型,加强数据的整合,构建一致的基础数据模型,IDL基于维度模型方法构建集市层,ADL完成应用的个性化和基于展现需求的数据组装。其中我们在构建ER模型遇到了比较大的困难和挑战,互联网业务的快速发展,人员的快速迭代变化,业务知识功底的不够全面导致ER模型设计迟迟不能产出,至此,我们也得到了一个经验,在一个不太成熟,快速变化的业务面前,构建ER模型的风险非常大,不太适合去构建。
第三阶段:阿里集团的业务和数据还在飞速发展,这个时候迎来了以hadoop为代表的分布式存储计算平台的快速发展,同时阿里集团自主研发的数加大规模计算服务MaxCompute(原ODPS)也在紧锣密鼓的进行中;我们在拥抱分布式计算平台的同时,也开始建设我们的第三代模型架构,我们需要找到一个核心问题,找打适合阿里集团业务发展,又能充分利用分布是计算平台能力的数据模型方式。
我们选择了以Kimball的维度建模为核心理念基础的模型方法论,同时对其进行了一定的升级和扩展,构建了阿里集团的数据架构体系——OneData
OneData体系分为:数据规范定义体系、数据模型规范设计、ETL规范研发以及支撑整个体系从方法到实施的工具体系。
落地实现》》》》》》
A)数据规范定义
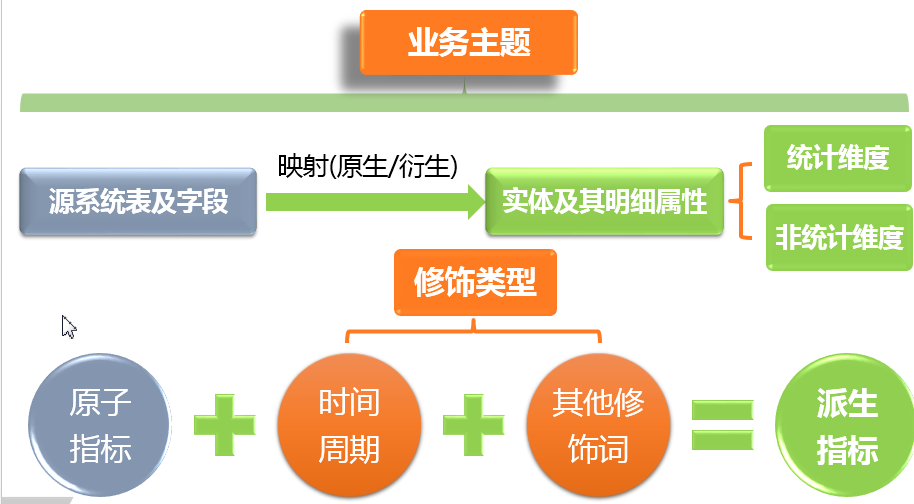
将此前个性化的数据指标进行规范定义,抽象成:原子指标、时间周期、其他修饰词等三个要素。
例如,以往业务方提出的需求是:最近7天的成交。而实际上,这个指标在规范定义中,应该结构化分解成为:
原子指标(支付订单金额 )+修饰词-时间周期(最近7天)+修饰词-卖家类型(淘宝)
B)数据模型架构
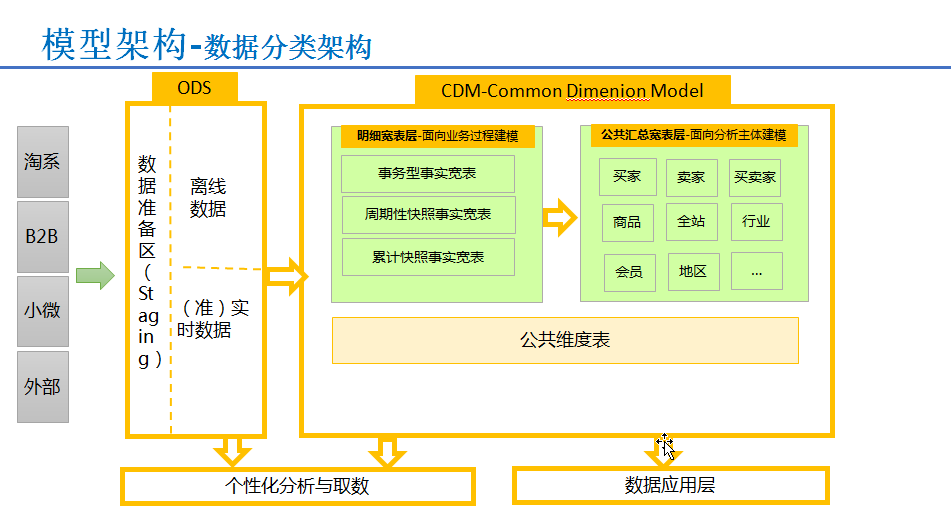
将数据分为ODS(操作数据)层、CDM(公共维度模型)层、ADS(应用数据)层。
其中:
ODS层主要功能
这里先介绍一下阿里云数加大数据计算服务MaxCompute,是一种快速、完全托管的TB/PB级数据仓库解决方案,适用于多种数据处理场景,如日志分析,数据仓库,机器学习,个性化推荐和生物信息等。
- 同步:结构化数据增量或全量同步到数加MaxCompute(原ODPS);
- 结构化:非结构化(日志)结构化处理并存储到MaxCompute(原ODPS);
- 累积历史、清洗:根据数据业务需求及稽核和审计要求保存历史数据、数据清洗;
CDM层主要功能
CDM层又细分为DWD层和DWS层,分别是明细宽表层和公共汇总数据层,采取维度模型方法基础,更多采用一些维度退化手法,减少事实表和维度表的关联,容易维度到事实表强化明细事实表的易用性;同时在汇总数据层,加强指标的维度退化,采取更多宽表化的手段构建公共指标数据层,提升公共指标的复用性,减少重复的加工。
ADS层主要功能
- 个性化指标加工:不公用性;复杂性(指数型、比值型、排名型指标)
- 基于应用的数据组装:大宽表集市、横表转纵表、趋势指标串
其模型架构图如下,阿里通过构建全域的公共层数据,极大的控制了数据规模的增长趋势,同时在整体的数据研发效率,成本节约、性能改进方面都有不错的结果。
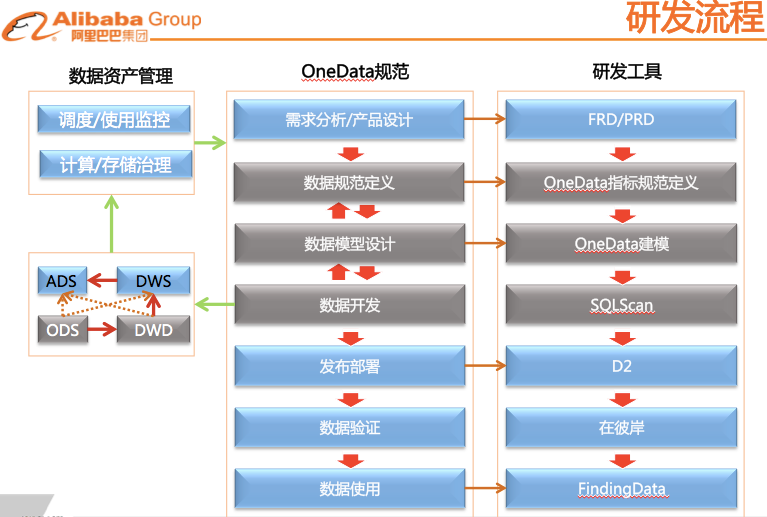
C)研发流程和工具落地实现
将OneData体系贯穿于整个研发流程的每个环节中,并通过研发工具来进行保障。
实施效果》》》》》》
- 数据标准统一:数据指标口径一致,各种场景下看到的数据一致性得到保障
- 支撑多个业务,极大扩展性:服务了集团内部45个BU的业务,满足不同业务的个性化需求
- 统一数据服务:建立了统一的数据服务层,其中离线数据日均调用次数超过22亿;实时数据调用日均超过11亿
- 计算、存储成本:指标口径复用性强,将原本30000多个指标精简到3000个;模型分层、粒度清晰,数据表从之前的25000张精简到不超过3000张。
- 研发成本:通过数据分域、模型分层,强调工程师之间的分工和协作,不再需要从头到尾每个细节都了解一遍,节省了工程师的时间和精力。
以上是关于干货:解码OneData,阿里的数仓之路。的主要内容,如果未能解决你的问题,请参考以下文章