数仓 | 数据模型OneData实践
Posted zhisheng_blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数仓 | 数据模型OneData实践相关的知识,希望对你有一定的参考价值。
数据治理问题
数据孤岛:各部门、产品、业务的数据相互隔离,难以通过共性ID打通
重复建设:重复的开发、计算、存储,带来高昂的数据成本
数据歧义:指标定义口径不一致,造成计算偏差,应用困难
OneData体系
OneData是阿里巴巴多年大数据开发和治理实践中沉淀总结的方法论,包含 OneModel、OneService、OneID 三个概念。
OneModel统一数据构建和管理
将指标定位细化为:原子指标、时间周期、修饰词(统计粒度、业务限定, etc),通过这些定义,设计出各类派生指标; 基于数据分层,设计出维度表、明细事实表、汇总事实表。
OneService统一数据服务
基于复用而不是复制数据的思想,能力包括:
利用主题逻辑表屏蔽复杂物理表的主题式数据服务;
一般查询 + OLAP分析 + 在线服务的统一且多样化数据服务;
屏蔽多种异构数据源的跨源数据服务。
OneID统一数据萃取
基于统一的实体识别、连接和标签生产,实现数据通融,包括:
ID自动化识别与连接;
行为元素和行为规则;
标签生产。
指导方针
首先,在建设大数据数据仓库时,要进行
充分的业务调研和需求分析。这是数据仓库建设的基石,业务调研和需求分析做得是否充分直接决定了数据仓库建设是否成功。其次,进行
数据总体架构设计,主要是根据数据域对数据进行划分;按照维度建模理论,构建总线矩阵、抽象出业务过程和维度。再次,
对报表需求进行抽象整理出相关指标体系,使用工具完成指标规范定义和模型设计。最后,就是
代码研发和运维。
实施流程
业务调研是否充分,将会直接决定数据仓库建设是否成功。
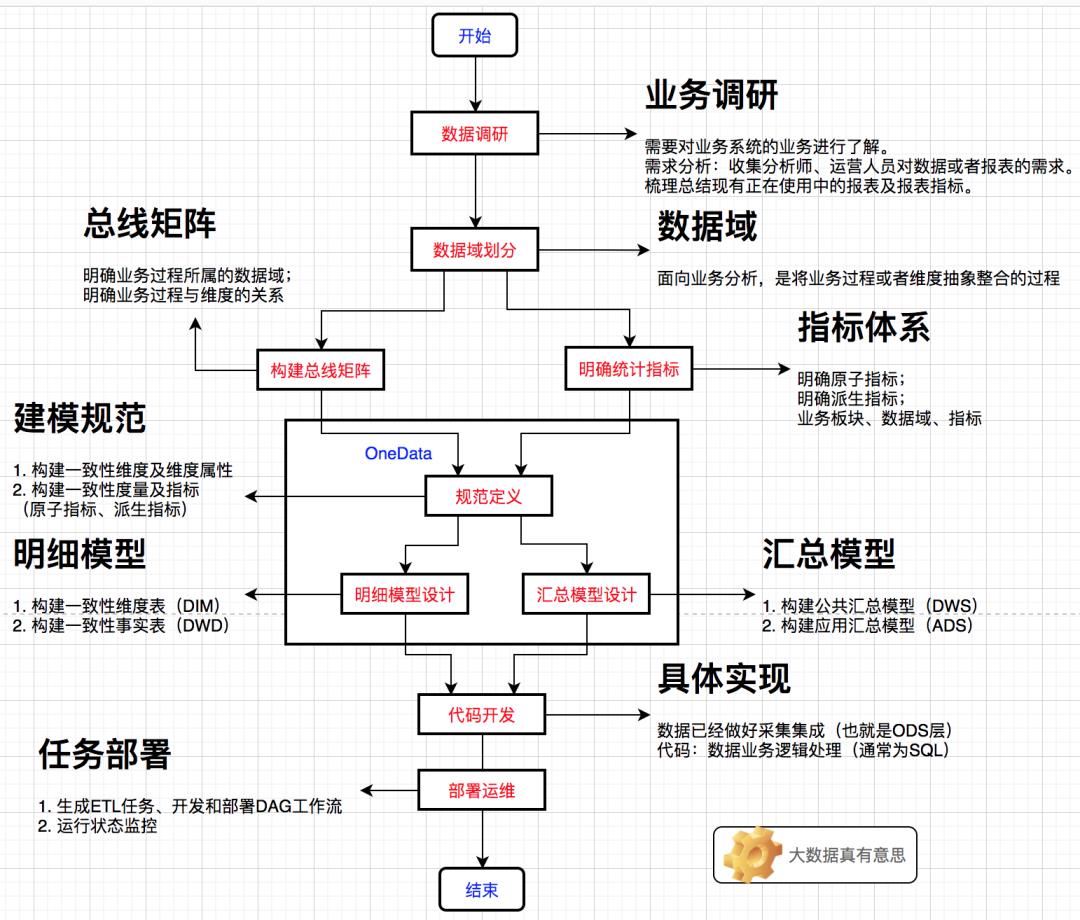
需求调研的途径有两种
根据与分析师、业务运营人员的沟通(邮件、IM、线下)获知需求;
对报表系统中现有的报表进行研究分析通过需求调研分析后,就清楚数据要做成什么样的。
很多时候,都是由具体的数据需求驱动数据仓库团队去了解业务系统的业务数据,这两者并没有严格的先后顺序。
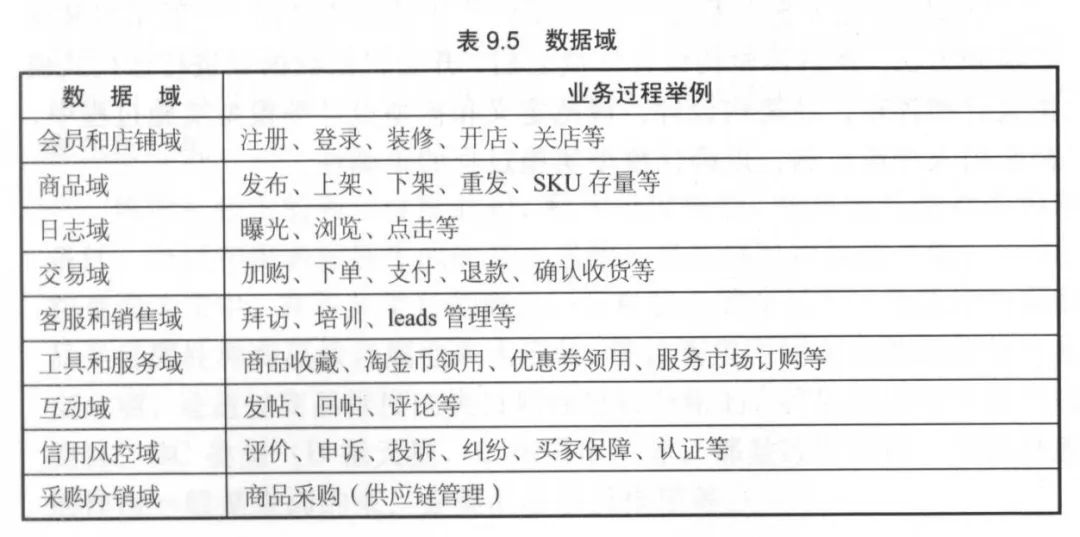
数据域划分
数据域是指面向业务分析,将业务过程或者维度进行抽象的集合。
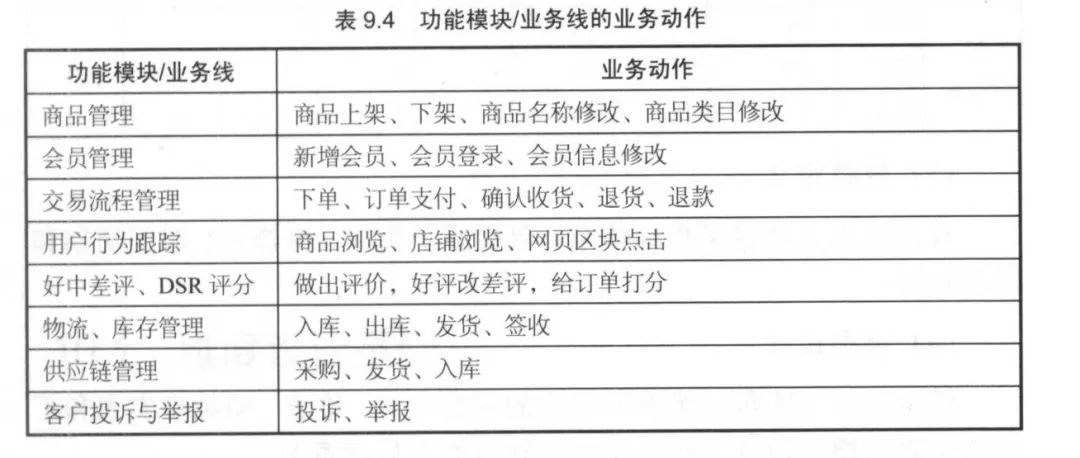
业务过程可以概括为一个个不可拆分的行为事件,如下单、支付、退款。
为保障整个体系的生命力,数据域需要抽象提炼,并且长期维护和更新,但不轻易变动。
在划分数据域时,既能涵盖当前所有的业务需求,又能在新业务进入时无影响地被包含进已有的数据域中或者扩展新的数据域。
构建总线矩阵
在进行充分的业务调研和需求调研后,就要构建总线矩阵了。
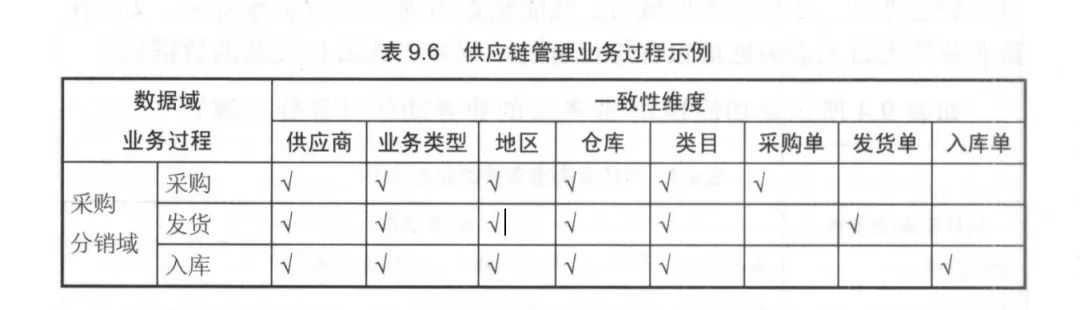
需要做两件事情
明确每个数据域下有哪些业务过程;
业务过程与哪些维度相关,并定义每个数据域下的业务过程和维度。
总结
OneData的实施过程是一个高度迭代和动态的过程,一般采用螺旋式实施方法。
在总体架构设计完成之后,开始根据数据域进行迭代式模型设计和评审。
在架构设计、规范定义和模型设计等模型实施过程中,都会引入评审机制,以确保模型实施过程的正确性。
end
Flink 从入门到精通 系列文章
基于 Apache Flink 的实时监控告警系统
关于数据中台的深度思考与总结(干干货)
日志收集Agent,阴暗潮湿的地底世界

公众号(zhisheng)里回复 面经、ClickHouse、ES、Flink、 Spring、Java、Kafka、监控 等关键字可以查看更多关键字对应的文章。点个赞+在看,少个 bug 👇以上是关于数仓 | 数据模型OneData实践的主要内容,如果未能解决你的问题,请参考以下文章