ubuntu 下安装伪分布式 hadoop
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ubuntu 下安装伪分布式 hadoop相关的知识,希望对你有一定的参考价值。
安装准备:
(1)hadoop安装包:hadoop-1.2.1.tar.gz
(2)jdk安装包:jdk-7u60-linux-i586.gz
(3)要是须要eclipse开发的话 还须要eclipse安装包 和eclipse和hadoop相关连的jar包。
安装:
(1)能够选择一个新建用户安装 也能够使用眼下账户。

(2)规定 所属用户组:

(3) 给予用户hadoop权限:
sudo vim /etc/sudoers 改动加入:
说到vim ubuntu本身自带的是vim tiny 不可用 须要使用的是vim full版本号 须要下载安装:
sudo apt-get remove vim-common
sudo apt-get install vim
vim 本身的一些配置可依据自己的喜好进行设置。
(4) 安装 jdk:
依据自己须要选择安装路径、
sudo mkdir /usr/java
tar -zxvf jdk-7u60-linux-i586.gz
mv jdk-1.7.0 jdk(改动名字 能够不设置(最好))

删除安装包:

(5) 配置jdk环境:
sudo vim /etc/profile 加入

更新一下(必须):source /etc/profile
測试一下:

jdk 完毕。
(6) ssh 免password:
一般ssh-client 包括在ubuntu系统中,可是ssh-server并没有 安装,能够通过 ssh ip 測试下;
安装ssh-server: sudo apt-get install ssh
安装之后进行操作:

生成:

ssh 能够登录。
(7) 安装hadoop
能够先创建一个hadoop到目录:
sudo mkdir /usr/hadoop
cd /usr/hadoop/
sudo tar -zxvf hadoop-1.2.1.tar.gz
sudo mv hadoop-1.2.1 hadoop
sudo chown -R hadoop:hadoop hadoop 将目录hadoop 读权限赋予hadoop用户
sudo rm -rf hadoop-1.2.1.tar.gz
安装之后须要进行配置:
配置 /etc/profile 加入:
sudo vim /etc/profile

配置hadoop-env.sh文件:
sudo vim /usr/hadoop/conf/hadoop-env.sh:

建立一个目录:用于配置hadoop.tmp.dir參数:
sudo mkdir /usr/hadoop/tmp
配置核心文件:
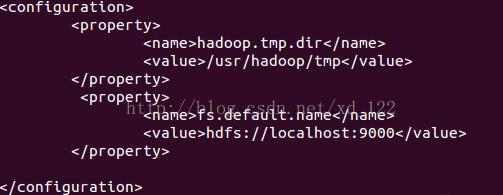
core-site.xml:
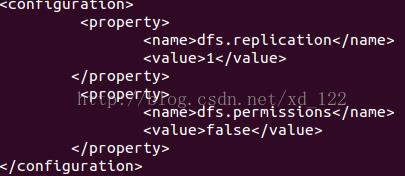
hdfs-site.xml:
mapred-site.xml:
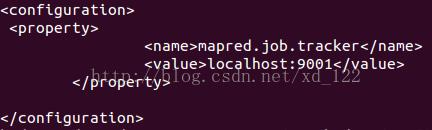
启动:因为前面配置 输入:
格式化节点:
hadoop namenode -format
启动:start-all.sh
jps 查看

停止:stop-all.sh
(8)安装eclipse
同上 先创建一个目录 解压安装....
进去启动eclipse 遇到个小问题:
eclipse找不到jdk 或是jre
解决:
cd /home/hadoop/eclipse (安装eclipse)
sudo ln -sf $JRE_HOME jre
就是这个:

进行eclipse 配置hadoop 将相关连的插件 拷贝到 eclipse下到plugins目录里面:

启动 eclipse:
window->perferences:

hadoop的安装文件夹。
设置:
右键以下的空白区域:
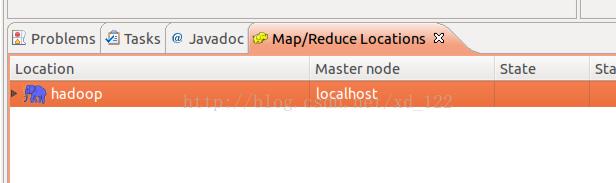
出现:并配置



点开左側小象:

eclipse配置完毕。
以后能够在eclipse书写作业 然后到终端进行运行。
配置遇到的问题:
namenode datanode 没有起来:
解决例如以下:
(1)删除 /usr/hadoop/tmp
(2)在创建 : sudo mkdir /usr/hadoop/tmp
(3)删除 /tmp目录下 全部以hadoop开头的文件:
sudo rm -rf /tmp/hadoop*
(4)又一次格式化:
hadoop namenode -format
(5)启动
start-all.sh
以上是关于ubuntu 下安装伪分布式 hadoop的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop在Ubuntu系统下伪分布式安装Hadoop,Spark和Hive
Ubuntu16.04 下 hadoop的安装与配置(伪分布式环境)
Ubuntu14.04或16.04下安装JDK1.8+Scala+Hadoop2.7.3+Spark2.0.2