OpenMP 并行编程
Posted Joekk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenMP 并行编程相关的知识,希望对你有一定的参考价值。
OpenMP 并行编程
最近开始学习并行编程,目的是为了提高图像处理的运行速度,用的是VS2012自带的OpenMP。
如何让自己的编译器支持OpenMP: 1) 点击 项目属性页 2)点击 配置 3)点击 [C/C++] 4)点击 语言 5)选中OpenMP支持
OpenMP 的构成:编译器指令 + 运行时例程;
编译器指令: 以 #pragma omp 开头,用以告知编译器哪一段代码需要并行。
运行时例程:必须包括omp.h 设置和获取执行环境相关的信息,也包括一系列用以同步的API;
编译器指令格式如下: #pragma omp <directive> [clause[ [,] clause]…] #pragma omp <指令> [子句,子句....]
dierctive(指令)包含如下几种:parallel,for,parallel for,section,sections,single,master,criticle,flush,ordered和atomic。这些指令指定要么是用以工作共享要么是用以同步。
对指令而言,子句是可选的,子句可以影响到指令的行为。五个指令(master,cirticle,flush,ordered和atomic)不能使用子句!!
最常用,最重要的指令: parallel
parallel:这条指令为动态长度的结构化程序块创建一个并行区域。
这条指令告知编译器这一程序块应被多线程并行执行。每一条指令都执行一样的指令流,但可能不是完全相同的指令集合。这可能依赖于if-else这样的控制流语句
int i = 0; #pragma omp parallel { i++; printf(" %d ",i); } Sleep(10000);
这一段代码的输出可以判断自己的电脑是几个核的;
#pragma omp for:工作共享指令 告诉OpenMP将紧随的for循环的迭代工作分给线程组并行处理;
如
#pragma omp parallel { #pragma omp for for(int i = 1; i < size; ++i) x[i] = (y[i-1] + y[i+1])/2; }#pragma omp parallel for
//下面一段代码是上面一段代码的简写
for(int i = 1; i < size; ++i)
x[i] = (y[i-1] + y[i+1])/2;
这一程序在并行区域的结束处需要同步,即所有的线程将阻塞在并行区域结束处,直到所有线程都完成。
注意:::
如果前面的代码没有使用#pragma omp for指令,那么每一个线程都将完全执行这个循环,造成的后果就是线程冗余计算;
要使用并行循环,必须你必须确保没有循环依赖,即循环中的某一次迭代不依赖于其它迭代的结果。
另外,OpenMP对在#pragma omp for或#pragma omp parallel for里的循环体有形式上的限制,循环必须使用下面的形式:
for([integer type] i = loop invariant value;
i {<,>,=,<=,>=} loop invariant value;
i {+,-}= loop invariant value)
这样OpenMP才能知道在进入循环时需要执行多少次迭代。
共享数据与私有数据:
OpenMP让共享和私有的差别显而易见,并且你能手动干涉。
共享变量在线程组内的所有线程间共享。因此在并行区域里某一条线程改变的共享变量可能被其它线程访问。反过来说,在线程组的线程都拥有一份私有变量的拷贝,所以在某一线程中改变私有变量对于其它线程是不可访问的。
默认地,并行区域的所有变量都是共享的。
除非如下三种特别情况:
一、在并行for循环中,循环变量是私有的。
如下里面的例子,变量i是私有的,变量j默认是共享的,但使用了firstprivate子句将其声明为私有的。
#pragma omp parallel { #pragma omp for firstprivate(j) lastprivate(i) reduction(+: sum)//变量i,j和sum是线程组里每一个线程的私有变量,它们将被拷贝到每一个线程。 for(i = 0; i < count; ++i) { int doubleI = 2 * i; for(; j < doubleI; ++j) { sum += myMatrix.GetElement(i, j); } } }
二、并行区域代码块里的本地变量是私有的。
三、所有通过private,firstprivate,lastprivate和reduction子句声明的变量为私有变量。
这四个子句每个都有一序列的变量,但它们的语义完全不同。private子句说明变量序列里的每一个变量都应该为每一条线程作私有拷贝。这些私有拷贝将被初始化为默认值(使用适当的构造函数),例如int型的变量的默认值是0。
firstprivate有着与private一样的语义外,它使用拷贝构造函数在线程进入并行区域之前拷贝私有变量。
lastprivate有着与private一样的语义外,在工作共享结构里的最后一次迭代或者代码段执行之后,lastprivate子句的变量序列里的值将赋值给主线程的同名变量,如果合适,在这里使用拷贝赋值操作符来拷贝对象。
reduction与private的语义相近,但它同时接受变量和操作符(可接受的操作符被限制为图4列出的这几种之一),并且reduction变量必须为标量变量(如浮点型、整型、长整型,但不可为std::vector,int[]等)。reduction变量初始化为图4表中所示的值。在代码块的结束处,为变量的私有拷贝和变量原值一起应用reduction操作符。
循环嵌套:
omp_set_nested()用于设置是否允许OpenMP进行嵌套并行,默认的设置为false。
什么是嵌套并行?就是在并行区域中嵌套另一个并行区域,如下:
#pragma omp parallel num_threads(5) { #pragma omp parallel num_threads(5) {/*do sth */} }
该如何执行?是执行5次?还是5×5次?这就是由是否嵌套并行来决定的,默认设置为不允许(false),所以会执行5次。
int main() { omp_set_nested(10); // none zero value is OK! #pragma omp parallel num_threads(2) { printf("ID: %d, Max threads: %d, Num threads: %d \\n",omp_get_thread_num(), omp_get_max_threads(), omp_get_num_threads()); #pragma omp parallel num_threads(5) printf("Nested, ID: %d, Max threads: %d, Num threads: %d \\n",omp_get_thread_num(), omp_get_max_threads(), omp_get_num_threads()); } return 0; }
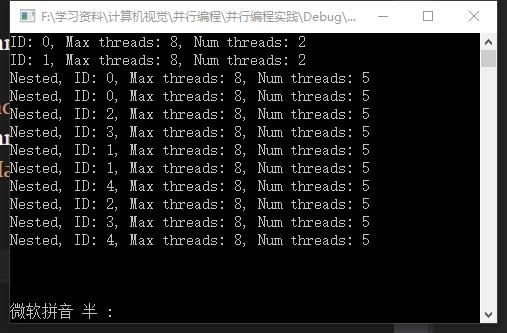
由调试结果可以看出来,运行过程中,先生成两个线程,再由这个两个线程各分出五个线程。
omp_get_thread_num,获取的ID是在当前嵌套层所在的线程组的ID。
omp_get_num_threads,获取的也是当前所在层的线程组的线程数量。
omp_get_max_threads,与线程的数量和执行等都无关,这是一个可以分析出来的值。
非循环并行
OpenMP经常用以循环层并行,但它同样支持函数层并行,这个机制称为OpenMP sections。sections的结构是简明易懂的,并且很多例子都证明它相当有用。
#pragma omp parallel sections { #pragma omp section //......一个并行区域 #pragma omp section //......另一个并行区域 }
参考链接:http://blog.csdn.net/augusdi/article/details/8807699
以上是关于OpenMP 并行编程的主要内容,如果未能解决你的问题,请参考以下文章