Spark中的资源调优
Posted 曹军
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark中的资源调优相关的知识,希望对你有一定的参考价值。
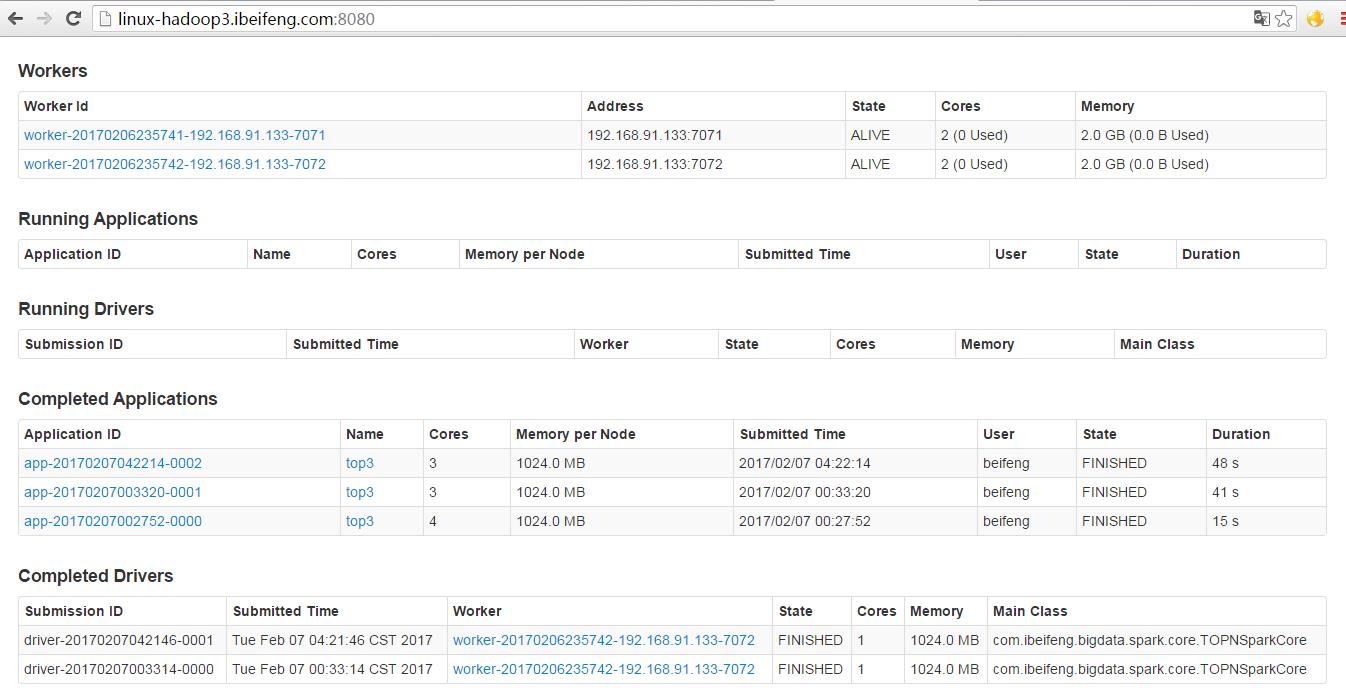
1.平常的资源使用情况
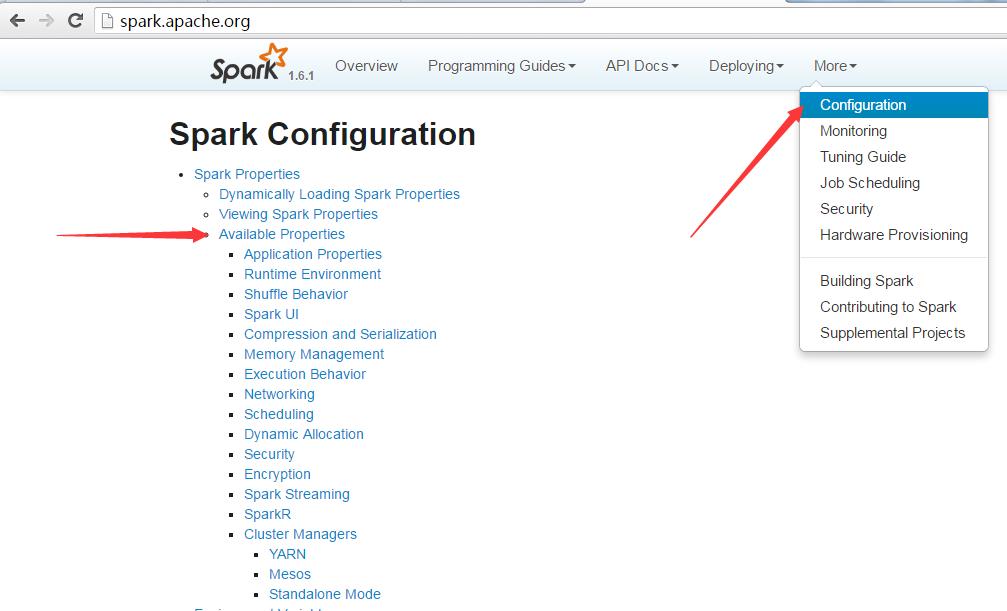
2.官网
3.资源参数调优
cores
memory
JVM
4.具体参数
可以在--conf参数中给定资源配置相关信息(配置的一般是JVM的一些垃圾回收机制)
--driver-memory
MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
给定driver运行的时候申请的内存,默认是1G
--executor-memory
MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
给定Executor运行的时候申请的内存,默认1G
--driver-cores
NUM Cores for driver (Default: 1).
standalone的cluster运行模式下,driver运行需要的core数量
--supervise
If given, restarts the driver on failure.
当运行在standalone上的时候如果driver宕机,会重启
--total-executor-cores
NUM Total cores for all executors.
给定针对所有executor上总共申请多少个cores,默认全部
--executor-cores
NUM Number of cores per executor. (Default: 1 in YARN mode,or all available cores on the worker in standalone mode)
Standalone模式下,每个executor分配多少cores,默认全部;
以及yanr模式下,每个executor分配多少cores,默认1个
--driver-cores
NUM Number of cores used by the driver, only in cluster mode(Default: 1).
yarn运行模式下(cluster),driver需要的cores数量,默认一个
--num-executors
NUM Number of executors to launch (Default: 2).
yarn运行模式下总的executors数量
5.示例
1.命令
为啥要设置,因为自己一个人把集群的资源给使用了,别人就会没有资源可以使用。
bin/spark-submit \\
--master spark://linux-hadoop3.ibeifeng.com:6066 \\
--deploy-mode cluster \\
--class com.ibeifeng.bigdata.spark.core.TOPNSparkCore \\
--conf "spark.ui.port=5050" \\
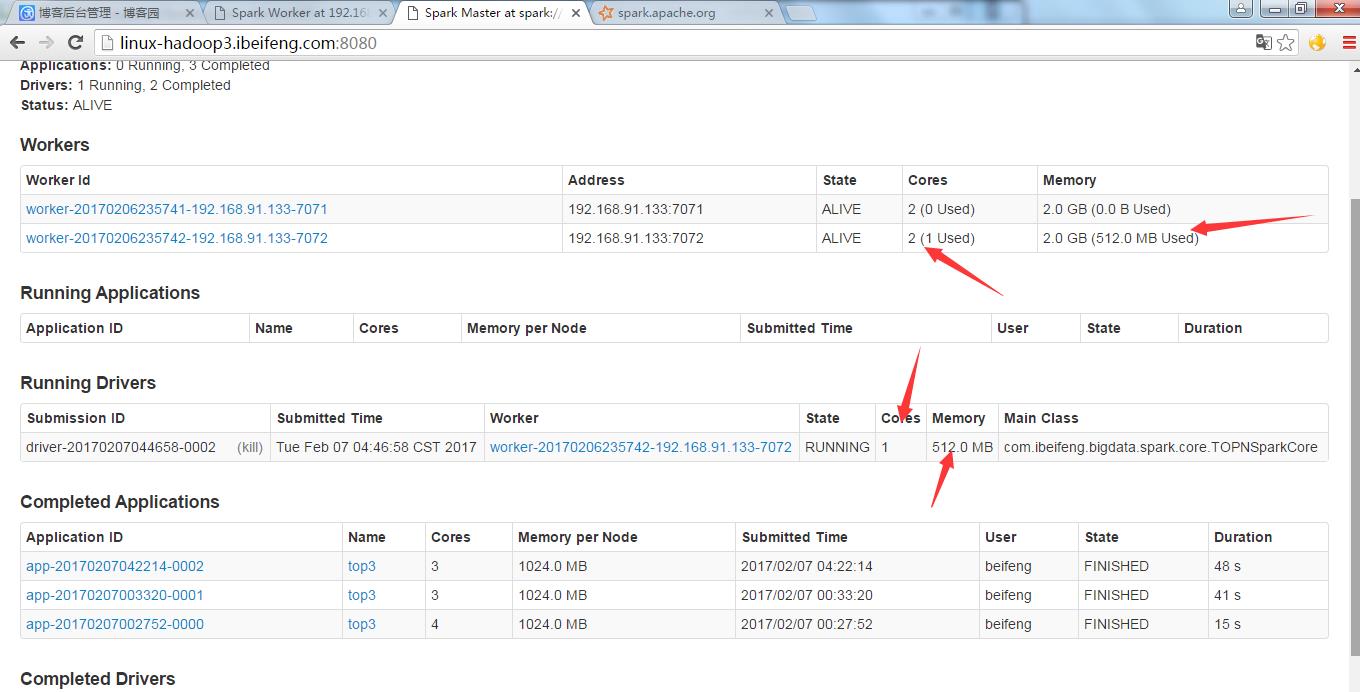
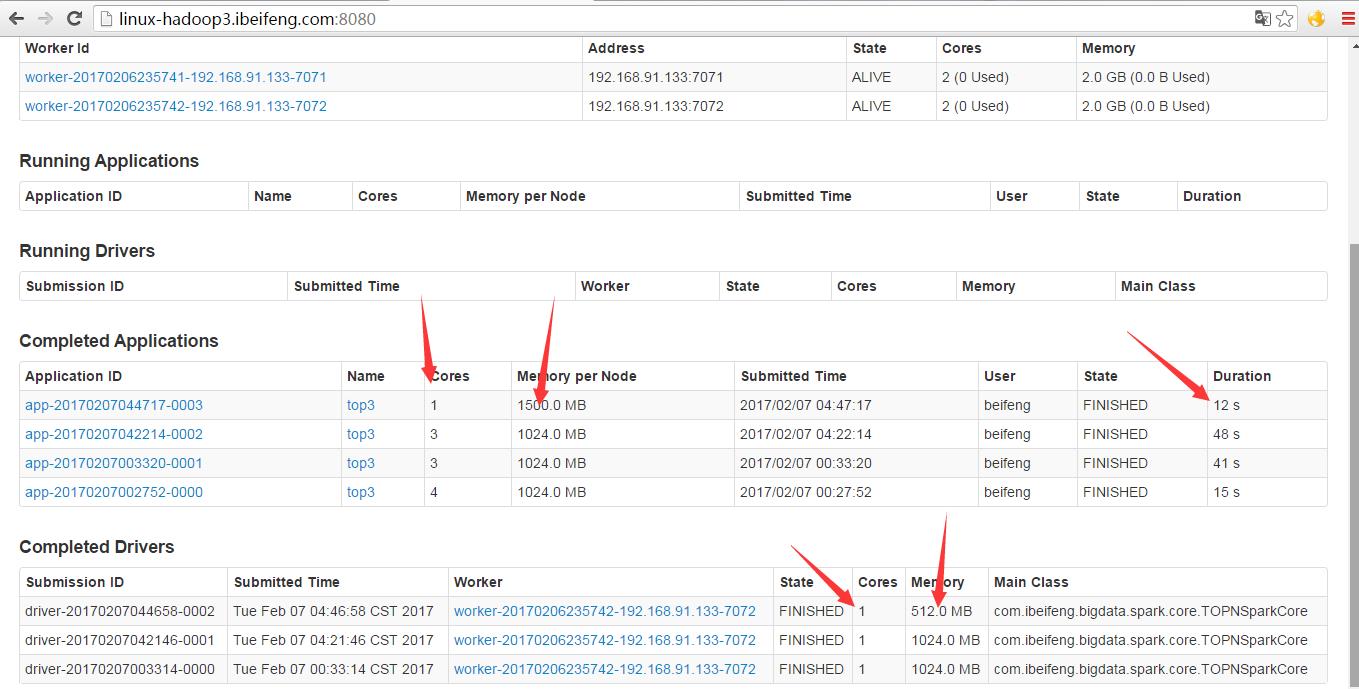
--driver-memory 512M \\
--supervise \\
--executor-memory 1500M \\
--total-executor-cores 1 \\
--executor-cores 1 \\
/etc/opt/datas/logs-analyzer.jar
2.运行
以上是关于Spark中的资源调优的主要内容,如果未能解决你的问题,请参考以下文章