Spark中的日志聚合的配置
Posted 曹军
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark中的日志聚合的配置相关的知识,希望对你有一定的参考价值。
一:History日志聚合的配置
1.介绍
Spark的日志聚合功能不是standalone模式独享的,是所有运行模式下都会存在的情况
默认情况下历史日志是保存到tmp文件夹中的
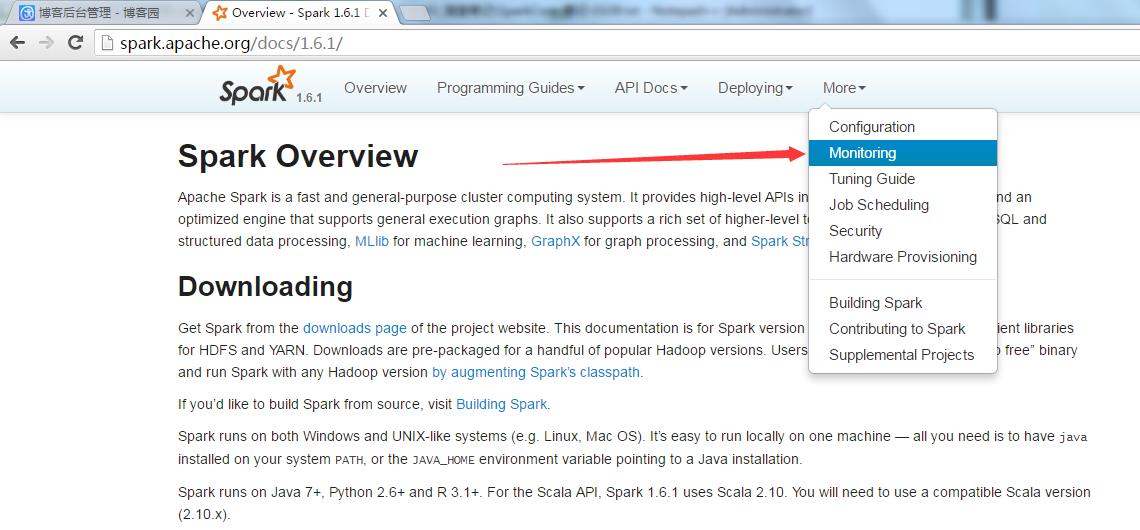
2.参考官网的知识点位置
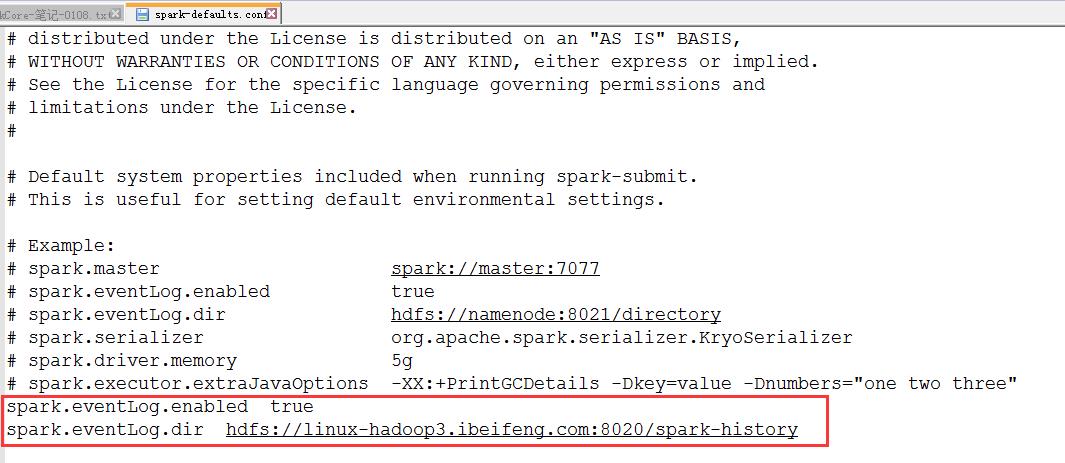
3.修改spark-defaults.conf
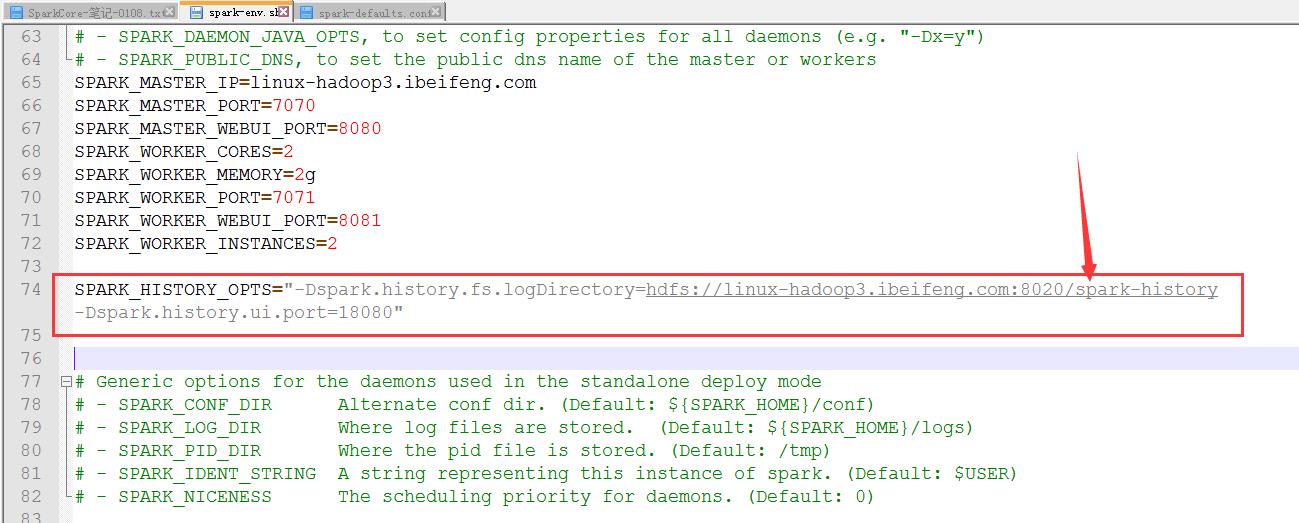
4.修改env.sh
5.在HDFS上新建/spark-history
bin/hdfs dfs -mkdir /spark-history
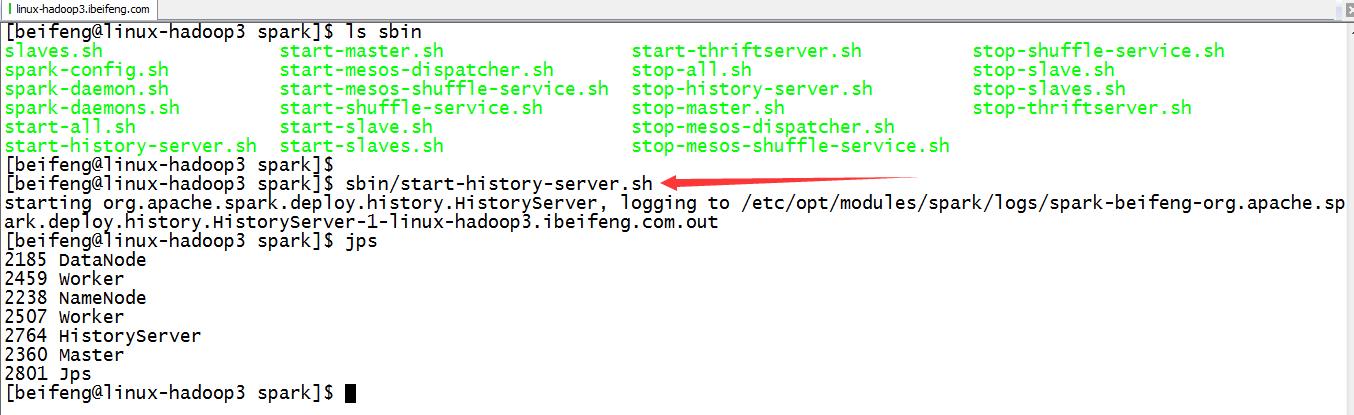
6.启动历史服务
sbin/start-history-server.sh
7.测试
webUI: http://192.168.187.146:18080/
local模式:bin/spark-shell
standalone模式:bin/spark-shell --master spark://linux-hadoop3.ibeifeng.com:7070
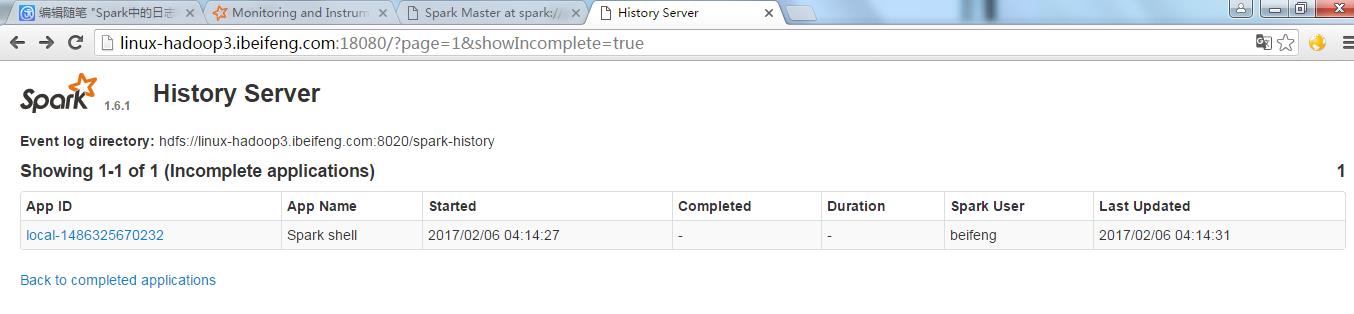
8.local模式的测试
bin/spark-shell
然后输入程序。
在
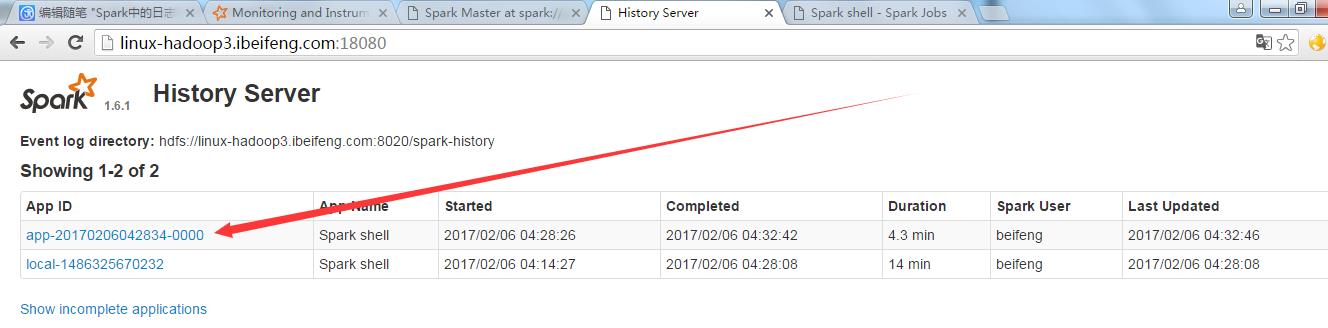
9.standalone模式
bin/spark-shell --master spark://linux-hadoop3.ibeifeng.com:7070
输入程序
二:RestApi
返回应用程序的执行结果。
1.关于RestApi的官网
也是属于monitor的部分
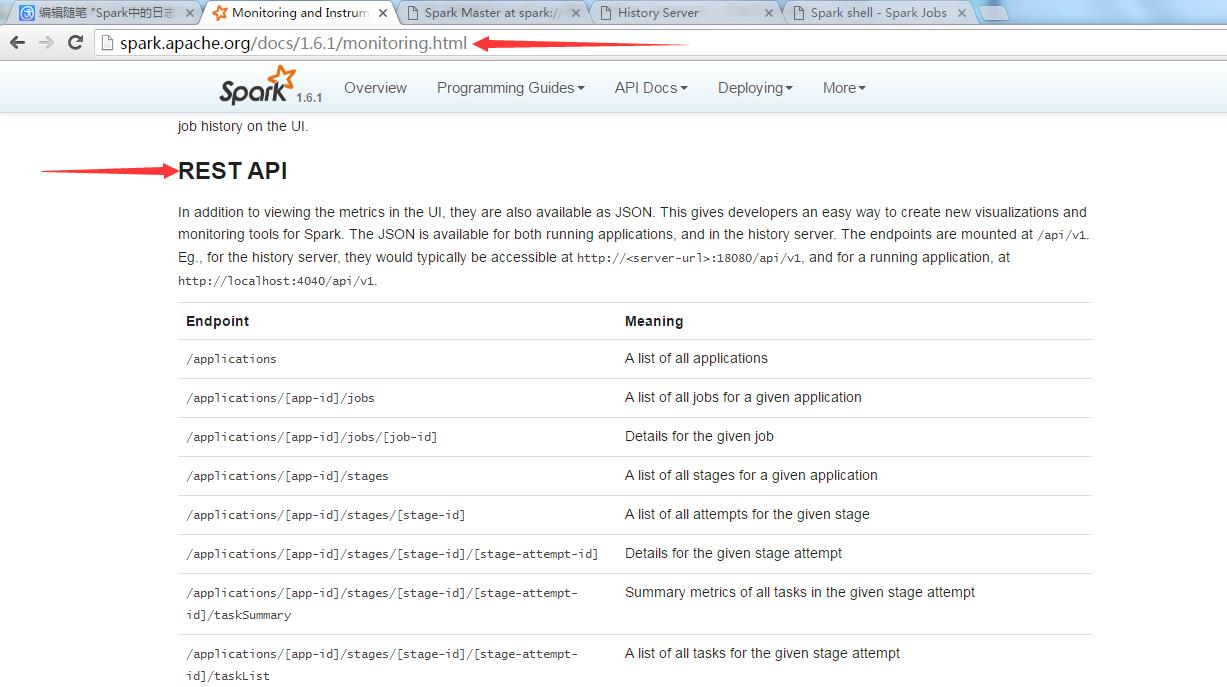
2.介绍
专门用于获取历史应用的执行结果
用法: http://<server-url>:18080/api/v1
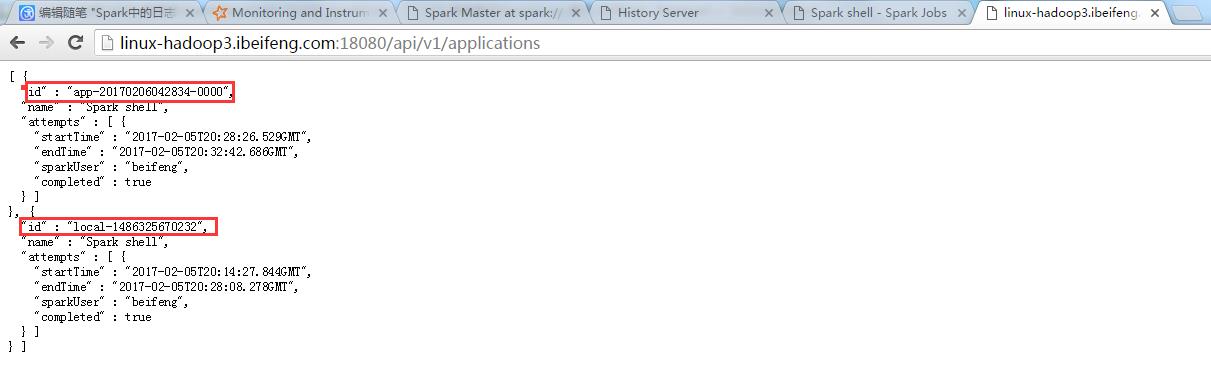
3.使用
http://linux-hadoop3.ibeifeng.com:18080/api/v1/applications
4.进一步使用
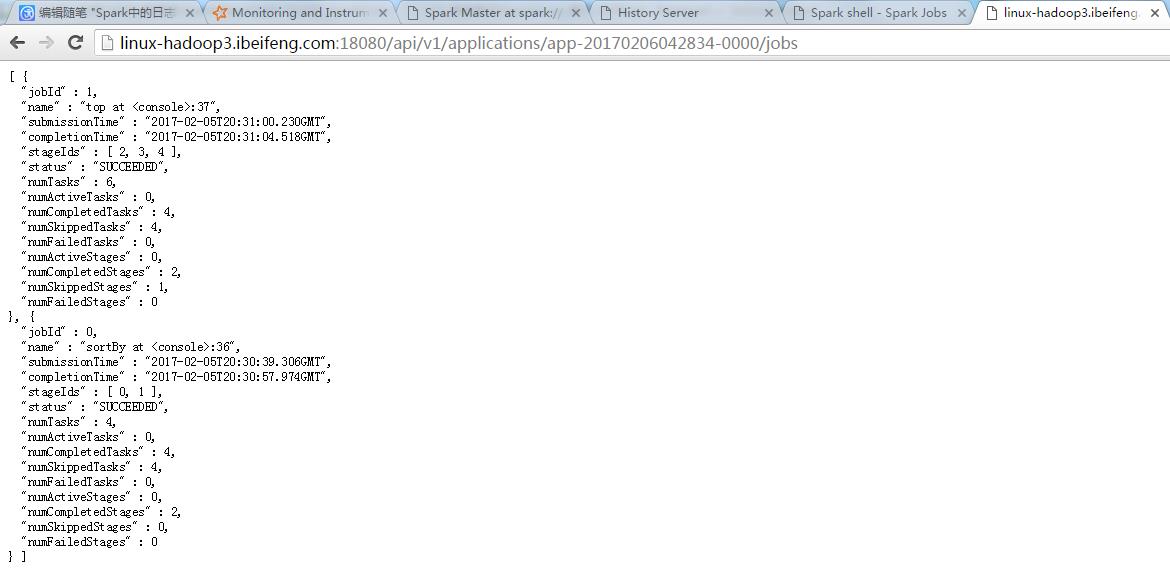
http://linux-hadoop3.ibeifeng.com:18080/api/v1/applications/app-20170206042834-0000/jobs
以上是关于Spark中的日志聚合的配置的主要内容,如果未能解决你的问题,请参考以下文章