流处理基本介绍
Posted Ransom0512
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了流处理基本介绍相关的知识,希望对你有一定的参考价值。
1. 什么是流处理
一种被设计来处理无穷数据集的数据处理系统引擎
2. 流处理的几个概念
1. 无穷数据(Unbounded data):一种持续生成,本质上是无穷尽的数据集。它经常会被称为“流数据”。然而,用流和批次来定义数据集的时候就有问题了,因为如前所述,这就意味着用处理数据的引擎的类型来定义数据的类型。现实中,这两类数据的本质区别在于是否有限,因此用能体现出这个区别的词汇来定性数据就更好一些。因此我更倾向于用无穷数据来指代无限流数据集,用有穷数据来指代有限的批次数据。
2. 无穷数据处理(Unbounded dataprocessing):一种发展中的数据处理模式,应用于前面所说的无穷数据类型。尽管我本人也喜欢使用流式计算来代表这种类型的数据处理方式,但是在本文这个环境里,这个说法是误导的。用批处理引擎循环运行来处理无穷数据这个方法在批处理系统刚开始构思的时候就出现了。相反的,设计完善的流计算系统则比批处理系统更能承担处理有穷数据的工作。因此,为了清晰明了,本文里我就只用无穷数据处理。
3. 低延迟,近似和/或推测性结果(Low-latency,approximate,and/or speculative results):这些结果和流处理引擎经常关联在一起。批处理系统传统上不是设计来处理低延迟或推测性结果这个事实仅仅是一个历史产物,并无它意。当然,如果想,批处理引擎也完全能产生近似结果。因此就如其他的术语,最好是用这些术语是什么来描述这些结果,而不是用历史上它们是用什么东西(通过流计算引擎)产生的来描述。
3. 流处理的六种方式
3.1. Event Sourcing
Event Sourcing是由老马(Martinfowler)提出来的一种模式,可以解释为事件溯源,该模式从事件源开始保存应用程序状态,保证每次更改都可以被保存为事件序列,也就是说,它不仅保存时间的自身,还保存时间的所有状态变化,在有需要的时候,可以随时根据时间日志重建当时状态,即不仅能做到知道在哪里,也能做到知道如何到那里去的,它会完整的描述对象的整个生命周期中经历的所有事件。
这方面典型的架构就是LMAX。
3.2. Reactive
反应式编程,也称为响应式编程。顾名思义,就是根据用户的输入来做出响应。这种动作一般是实时的。
根据响应式编程宣言所述,反应式变成一般具有如下几个特点:
响应:响应性是系统高可用的基础,但更重要的是,响应性意味着可以快速检测问题并处理问题。响应系统专注于提供快速一致的响应时间,建立可靠的上限,以便提供一致的服务质量,从而简化错误处理,建立用户信息,并鼓励做出更进一步的交互。
弹性:系统在面对失败时候,仍然保持响应。
弹性:系统在负载变化的时候仍然保持响应。我们可以通过增加或者减少分配给这些服务的资源来对负载变化做出响应。这意味着整个设计没有竞争和单点瓶颈。
消息驱动:响应式系统依靠异步消息在组件之间建立一个边界,确保组件之间的松耦合和隔离性。这个边界还提供了失败委托,负载均衡,弹性和流控等手段来保证系统的高可用性,这是响应式系统的一个必备特点。
3.3. CEP
Complex event processing。复杂事件处理。
事件即事物的状态信息变化,事物之间的作用的动作。复杂事件处理描述的就是系统如何持续地处理这些事件,对系统对变化的持续反应。不论是个体还是系统,都需要从大量的实践中过滤提取,按照既定的处理反应规则做处理。CEP主要依靠规则语言或者持续查询语言来完成事件的过滤、判断和处理。
这类典型应用比如Esper,TIBCO,IBM Streams等。
3.4. Stream Processing
这个流处理架构,从大数据量领域发展起来的实时数据处理模型,其主要强调分布式,高性能,高可靠性。目前主要有Storm,Flink,Spark Streaming等,这类介绍的比较多,这里就不详细介绍了。
3.5. Actors/SEDA
SEDA(Staged event-driven architecture) 阶段事件驱动架构,也成为阶段是服务器模型,其主要是将复杂的,事件驱动的应用分解为一系列通过队列连接的阶段,从而避免线程的并发模型带来高负载问题,同时还可以达到解耦,负载均衡,分布式等特性。
Actor模型包装了消息传输和封装机制,用户只需要面对消息和业务逻辑,因此天然就具有分布式、高并发、无状态的特性;对外提供简单编程接口。
这类应用,典型的有Apache Gearpump(基于Akka),Kafka Streams等。
3.6. Change Capture
变更数据捕获,捕捉数据库插入、更新和删除的动作并作出相应反应。
目前很多数据库都提供这样的功能,能够将数据操作日志导出并可以由其他工具导入Kafka等系统中来做二次处理。比如Kafka,mysql等都提供这样的功能。
4. 流处理的发展目标
但是Kafka Streams的作者提出了一个观点,个人非常赞同,
So what did we learn?Lots. One of the key misconceptions we had was that stream processing would beused in a way sort of like a real-time MapReduce layer. What we eventually cameto realize, though, was that the most compelling applications for streamprocessing are actually pretty different from what you would typically do witha Hive or Spark job—they are closer to being a kind of asynchronousmicroservice rather than being a faster version of a batch analytics job.
What do I mean by this? What Imean is that these stream processing apps were most often software thatimplemented core functions in the business rather than computing analyticsabout the business.
翻译过来的核心观点就是:
我们曾经有过的一个关键的错觉是以为流处理将会被以一种类似于实时的MapReduce层的方式使用。我们最终却发现,大部分对流处理有需求的应用实际上和我们通常使用Hive或者Spark job所做的事情有很大不同,这些应用更接近于一种异步的微服务,而不是批量分析任务的快速版本。
大部分流处理程序是用来实现核心的业务逻辑,而不是用于对业务进行分析。
流处理当前需要在如下几个方面进行进入以保证自己的核心竞争力。
1. 强一致性:这保证流计算能和批处理平起平坐。
本质上,准确性取决于存储的一致性。流计算系统需要一些类似于checkpoint的方法来保证长时间的持久化状态。几年前,当Spark刚刚出现在大数据领域的时候,它几乎就是照亮了流计算黑暗面的灯塔(因为Spark支持强一致)。在这之后,情况越来越好。但是还是有不少流计算系统被设计和开发成尽量不去支持强一致性。目前Flink,Kafka Streams也能够支持强一致性,这简直就是流处理的福音。
再次强调一遍重点:强一致性必须是“只处理一次(exactly-onceprocessing)”,这样才能保证正确性。只有这样的系统才能追平并最终超越批处理系统。除非你对计算的结果是否正确并不介意,否则我还是请你放弃任何不能保证强一致性的流计算系统。现有的批处理系统都保证强一致性,不会让你在使用前去检查计算结果是否正确。所以也不要浪费你的时间在那些达不到这样标准的流计算系统上。
2. 时间推理的工具:这一点让流计算超越批处理。
在处理无穷的、无序的、事件—时间分布不均衡的数据时,好的时间推理工具对于流计算系统是极其重要的。现在越来越多的数据已经呈现出上面的这些特征,而现有的批处理系统(也包括几乎所有的流计算系统)都缺少必要的工具来应对这些特性带来的难题。
3、弹性伸缩功能,即在保证Exactly-once 语义的情况下,流处理应用无需用户的介入也能自动修改并发数,实现应用的自动扩容和缩容。
4、流上的SQL查询功能以及完整SQL支持,包含窗口,模式匹配等语法支持。
5. 时间
流处理系统中的时间分为两种:事件时间和处理时间。
事件时间(Event Time): 事件发生的时间
处理时间(Processing Time) 事件处理的时间。
时间是流处理的基础,绝大部分场景都对时间又严格要求。(PS如果没有的话,那这个世界简直就太简单了。)
Kafka Streams系统中就要求必须以包含时间,如果没有事件时间,就必须在保存的时候添加系统时间。
我们能够基于时间来对数据做聚合,实现窗口功能,能够解决乱序问题,总之,时间是流处理最为重要的一个因素。
6. Lambda架构
Lambda架构最初是由Storm的创始人NatanMarz在2011年提出的。在他的文章《How to beat the CAP theorem》中提出了Lambda架构,通过流和批的融合,实现快速的实时数据处理,或者说是让批来为流提供服务。
一个典型的lambada的架构来自于下面的图。
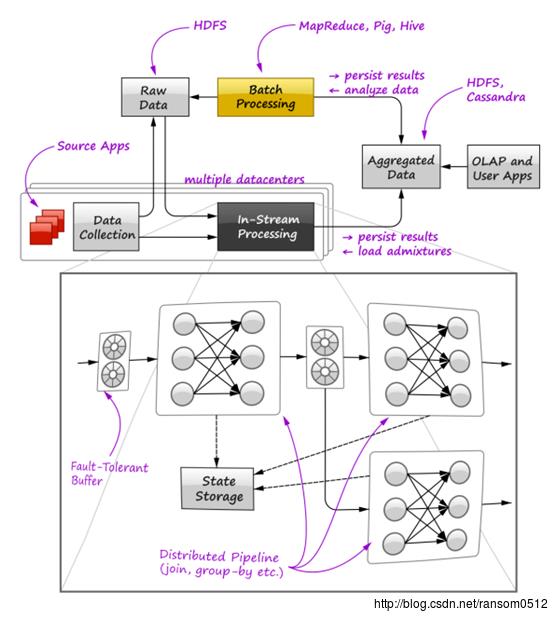
这在当时是一个影响力很大的架构,并且有很多产品是基于该架构的,但是随着技术的演进,在现在看来,还是有很大问题的。比如:
1、 lambda架构要搭建部署和维护两套队列的集群,并且对结果做合并,这是十分麻烦的,并且可靠性也是相当差的。
2、 数据冗余,数据要同时进入两套系统,存放两份。
7. 乱序问题
分布式的流处理系统,不可避免的会遇到数据的乱序问题,数据乱序就是指数据达到某一个节点的时候,已经不是按照原来发生的顺序了,期间可能有丢失,错乱等。
乱序问题一般的处理方式是使用时间排序窗口,不论是系统时间驱动还是事件时间驱动。其实就是数据在进入节点之后,按照时间进行排序,然后等待一段时间,等待事件都已经到达之后再来进行下一步操作。如果无法确定事件都已经到达,或者是由部分时间一直没有达到,那么就等到窗口超时为止,然后计算结果。
这个时候计算出来的结果,在有的系统里面已经作为最终结果,直接输出了,即使后续时间过了很长时间已经到达了,也是直接丢弃,不会影响最终结果。在另外一些系统中,比如google的MillWheel中,有水印(WaterMark)机制可以在事件最终到来之后,重新计算并刷新结果。
8. 数据可靠性问题
流上的可靠性一直是一个老大难问题,在和业界其他人交流的时候,也纷纷摇头,这个问题无解。目前流处理最广泛的应用还是做一些不怎么关注可靠性的计算。
不过这个问题在2016年有了很大的突破。
Intel在2016年终于发布了自己的内存快照技术,通过使用新的存储介质,能够达到内存一半的存取速度,这是一个很了不起的成就,已经基本可以商用了,在流计算领域,为了性能考虑,数据都是保存在内存中的,如果操作系统能够自动完成快照,那就很大程度上保证了数据的可靠性,流处理系统就可以完全不用关注这些什么状态,数据等信息,内存里面已经全部都有了。如果Intel能够做到增量式的内存快照,或者是快照速度和内存读取速度一致,甚至更快的时候,流处理系统的春天就会到来,哪个时候,流处理系统就会变得无比简单。
在硬件得到突破的同时,软件方面也在不断的取得突破。
Flink的流处理系统实现了CheckPoint功能,能够将窗口数据保存到内存当中,当流计算发生故障的时候,得到快速恢复,目前功能已经可用,不过性能还是会差一些,在百万TPS级别,快照速度在秒级,还是稍微有些慢,不过已经可用。
Kafka Streams的推出,利用Kafka消息队列自身Offset的特性,再加上新开发的compact功能,成功实现了流和表的结果,并且也可以通过重放来实现可靠性,状态信息通过数据库保存,这也是流处理在可靠性方面的突破,利用外界第三方组件来实现自身的可靠性。
流处理系统可靠性处理还有一种趋势就是数据库。数据库系统天然具有可靠性和事务性的特点,能够很好的适应金融等事务性和可靠性比较高的场景,唯一就是数据量和拓展性存在问题,但是随着分布式内存数据库等的发展,也许后面分布式内存数据库替代流处理系统也不是不可能的。但是无论怎么说,我们最求的是实时计算,而不是流处理系统,我们的目标是Fast Data。
9. 流上的SQL
以前,CEP和其他流处理平台上面的SQL是五花八门,各有各的特点,包括我们的StreamCQL,都属于类SQL的范畴,但是从现在来看,流上的SQL目前发展趋势已经很明显了,那就是兼容标准SQL,语义不能和标准SQL冲突,这个是第一步;然后就是做尽可能少的拓展,尽可能的利用其他数据库SQL中已有的语法,比如Oracle的Match recognize等语法来实现模式匹配功能,这样用户最容易接受。窗口等特性,使用函数功能或者是复用SQL的 over语法即可。不支持的场景可以适当做少量拓展。总的来说,流式SQL还在拓展阶段,大家都在拼命抢地盘,想占领制高点,然后推广自己的语法。
9.1. 流和表的关系
流和表的关系是理解流上SQL的基础,也是最重要的
流和表实际上是一体的。
流很容易理解,就是一个管道,当有窗口存在的时候,数据才会发生汇聚。
表就是我们通常理解的数据库的表。
流上窗口中的数据,实际上就是一张表。同样的,当表上数据在不断发生变化的时候,这种changelog,就是流。
这种观点现在已经基本成为流处理领域概念理解的标准。而且绝大部分数据库都支持的data capture,也是传统数据库为了和流处理相结合而做出的改变。Kafka Streams就包含data capture的工具,支持将数据从数据库中导入kafka成为一个流。
9.2. 流和表的转换
1) 流和计算结果是表,这一点在分组窗口上体现的特别明显。而且我们的使用习惯也和表一致。
比如:
我们统计最近10分钟各区域的用户点击次数,输出每个区域的总点击次数,那么一次性就会输出多行结果,每个地区一行记录,这个就是流上的聚合结果,也是流的中间状态;而为了可靠性,我们一般会将这些计算结果保存到数据库中,以便于故障时候的恢复。
2) 表中每一次的数据变化,用change log体现就是流。
3) 表和流之间的Join,实际上是窗口和表之间的Join
10. 参考
https://www.oreilly.com.cn/ideas/?p=18&from=timeline
http://www.cnblogs.com/devos/p/5616086.html
http://www.oreilly.com/data/free/stream-processing.csp
http://www.martinfowler.com/eaaDev/EventSourcing.html
http://www.reactivemanifesto.org/
http://nathanmarz.com/blog/how-to-beat-the-cap-theorem.html
以上是关于流处理基本介绍的主要内容,如果未能解决你的问题,请参考以下文章
带你认识FusionInsight Flink:既能批处理,又能流处理
带你认识FusionInsight Flink:既能批处理,又能流处理