带你认识FusionInsight Flink:既能批处理,又能流处理
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了带你认识FusionInsight Flink:既能批处理,又能流处理相关的知识,希望对你有一定的参考价值。
摘要:本文主要介绍了FusionInsight Flink组件的基本原理、Flink任务提交的常见问题、以及最佳实践FAQ。
本文分享自华为云社区《FusionInsight HD Flink组件基本原理和常见问题解析》,作者:FI小粉丝 。
Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供数据分发以及并行化计算的流数据处理引擎。
它的最大亮点是流处理,是业界最顶级的开源流处理引擎。
Flink最适合的应用场景是低时延的数据处理(Data Processing)场景:高并发pipeline处理数据,时延毫秒级,且兼具可靠性。
本文主要介绍了FusionInsight Flink组件的基本原理、Flink任务提交的常见问题、以及最佳实践FAQ。
基本概念
基本原理
简介
Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及并行化计算的流数据处理引擎。它的最大亮点是流处理,是业界最顶级的开源流处理引擎。
Flink最适合的应用场景是低时延的数据处理(Data Processing)场景:高并发pipeline处理数据,时延毫秒级,且兼具可靠性。
Flink技术栈如图所示:

Flink在当前版本中重点构建如下特性,其他特性继承开源社区,不做增强,具体请参考:https://ci.apache.org/projects/flink/flink-docs-release-1.4/
- DataStream
- Checkpoint
- Stream SQL
- 窗口
- Job Pipeline
- 配置表
架构
Flink架构如图所示。
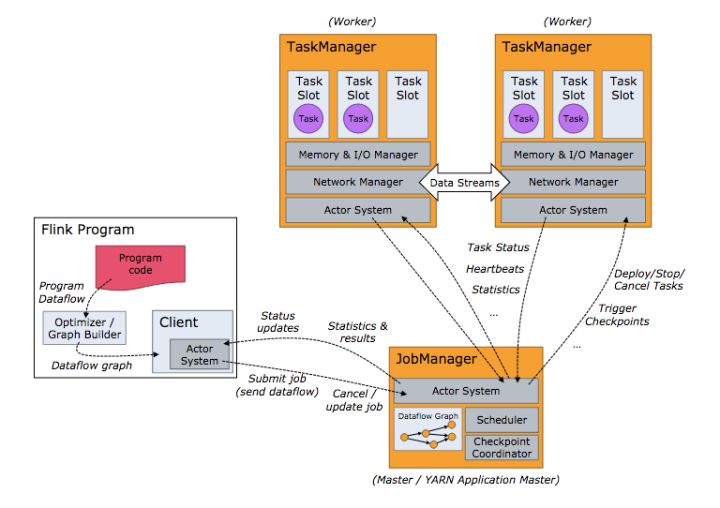
Flink整个系统包含三个部分:
- Client
Flink Client主要给用户提供向Flink系统提交用户任务(流式作业)的能力。
- TaskManager
Flink系统的业务执行节点,执行具体的用户任务。TaskManager可以有多个,各个TaskManager都平等。
- JobManager
Flink系统的管理节点,管理所有的TaskManager,并决策用户任务在哪些Taskmanager执行。JobManager在HA模式下可以有多个,但只有一个主JobManager。
Flink系统提供的关键能力:
- 低时延
提供ms级时延的处理能力。
- Exactly Once
提供异步快照机制,保证所有数据真正只处理一次。
- HA
JobManager支持主备模式,保证无单点故障。
- 水平扩展能力
TaskManager支持手动水平扩展。
原理
- Stream & Transformation & Operator
用户实现的Flink程序是由Stream和Transformation这两个基本构建块组成。
-
- Stream是一个中间结果数据,而Transformation是一个操作,它对一个或多个输入Stream进行计算处理,输出一个或多个结果Stream。
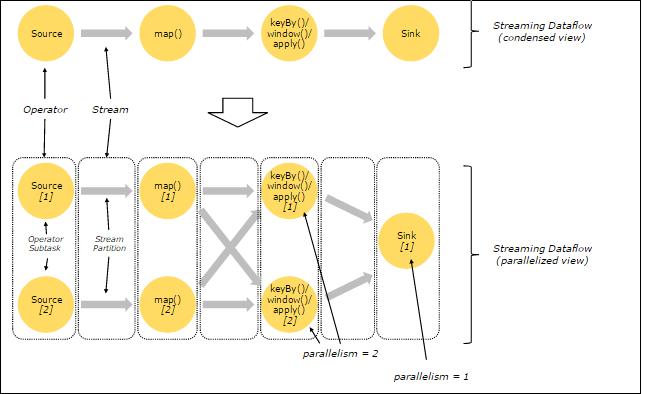
- 当一个Flink程序被执行的时候,它会被映射为Streaming Dataflow。一个Streaming Dataflow是由一组Stream和Transformation Operator组成,它类似于一个DAG图,在启动的时候从一个或多个Source Operator开始,结束于一个或多个Sink Operator。
下图为一个由Flink程序映射为Streaming Dataflow的示意图。

上图中“FlinkKafkaConsumer”是一个Source Operator,Map、KeyBy、TimeWindow、Apply是Transformation Operator,RollingSink是一个Sink Operator。
- Pipeline Dataflow
在Flink中,程序是并行和分布式的方式运行。一个Stream可以被分成多个Stream分区(Stream Partitions),一个Operator可以被分成多个Operator Subtask。
Flink内部有一个优化的功能,根据上下游算子的紧密程度来进行优化。
-
- 紧密度低的算子则不能进行优化,而是将每一个Operator Subtask放在不同的线程中独立执行。一个Operator的并行度,等于Operator Subtask的个数,一个Stream的并行度(分区总数)等于生成它的Operator的并行度。如下图所示。
Operator
-
- 紧密度高的算子可以进行优化,优化后可以将多个Operator Subtask串起来组成一个Operator Chain,实际上就是一个执行链,每个执行链会在TaskManager上一个独立的线程中执行,如下图所示。
Operator chain

-
-
- 上图中上半部分表示的是将Source和map两个紧密度高的算子优化后串成一个Operator Chain,实际上一个Operator Chain就是一个大的Operator的概念。图中的Operator Chain表示一个Operator,keyBy表示一个Operator,Sink表示一个Operator,它们通过Stream连接,而每个Operator在运行时对应一个Task,也就是说图中的上半部分有3个Operator对应的是3个Task。
- 上图中下半部分是上半部分的一个并行版本,对每一个Task都并行化为多个Subtask,这里只是演示了2个并行度,sink算子是1个并行度。
-
日志介绍
日志描述
日志存储路径:
- Executor运行日志:“$BIGDATA_DATA_HOME/hadoop/data$i/nm/containerlogs/application_$appid/container_$contid”

运行中的任务日志存储在以上路径中,运行结束后会基于Yarn的配置确定是否汇聚到HDFS目录中。
- 其他日志:“/var/log/Bigdata/flink/flinkResource”
日志归档规则:
- Executor日志默认50MB滚动存储一次,最多保留100个文件,不压缩。
- 日志大小和压缩文件保留个数可以在FusionInsight Manager界面中配置。
Flink日志列表

日志级别
Flink中提供了如下表所示的日志级别。日志级别优先级从高到低分别是ERROR、WARN、INFO、DEBUG。程序会打印高于或等于所设置级别的日志,设置的日志等级越高,打印出来的日志就越少。
日志级别

如果您需要修改日志级别,请执行如下操作:
- 登录FusionInsight Manager系统。
- 选择“服务管理 > Flink > 服务配置”。
- “参数类别”下拉框中选择“全部”。
- 左边菜单栏中选择所需修改的角色所对应的日志菜单。
- 选择所需修改的日志级别。
- 单击“保存配置”,在弹出窗口中单击“确定”使配置生效。
配置完成后立即生效,不需要重启服务。
日志格式

常见故障
1. Flink对接kafka-写入数据倾斜,部分分区没有写入数据
问题现象与背景
使用FlinkKafkaProducer进行数据生产,数据只写到了kafka的部分分区中,其它的分区没有数据写入
原因分析
- 可能原因1:Flink写kafka使用的机制与原生接口的写入方式是有差别的,在默认情况下,Flink使用了”并行度编号+分区数量”取模计算的结果作为topic的分区编号。那么会有以下两种场景:

-
- 并行度%分区数量=0,表示并行度是kafkatopic分区数的一倍或者多倍,数据的写入每个分区数据量是均衡的。
- 并行度%分区数量≠0,那么数据量势必会在个别分区上的数据量产生倾斜。
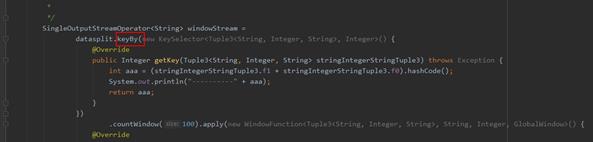
- 可能原因2:在业务代码的部分算子中使用了keyby()方法,由于现网中的数据流中,每个key值所属的数据量不一致(就是说某些key的数据量会非常大,有些又非常小)导致每个并行度中输出的数据流量不一致。从而出现数据倾斜。
解决办法
原因一:
方法1,调整kafka的分区数跟flink的并行度保持一致,即要求kafka的分区数与flink写kafka的sink并行度保持强一致性。这种做法的优势在于每个并行度仅需要跟每个kafka分区所在的 broker保持一个常链接即可。能够节省每个并发线程与分区之间调度的时间。
方法2,flink写kafka的sink的分区策略写成随机写入模式,如下图,这样数据会随即写入topic的分区中,但是会有一部分时间损耗在线程向寻址,推荐使用方法1。

原因二:
需要调整业务侧对key值的选取,例如:可以将key调整为“key+随机数”的方式,保证Flink的keyby()算子中每个处理并行度中的数据是均衡的。
2. Flink任务的日志目录增长过快,导致磁盘写满
问题现象
集群告警磁盘使用率超过阈值,经过排查发现是taskmanager.out文件过大导致

原因分析
代码中存在大量的print模块,导致taskmanager.out文件被写入大量的日志信息,taskmanager.out 一般是,业务代码加入了 .print的代码,需要在代码中排查是否有类似于以下的代码逻辑:
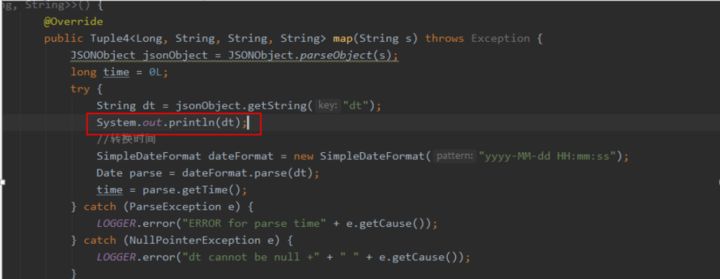
或者类似于这样的打印:

如果包含,日志信息会持续打印到taskmanager.out里面。
解决方案
将上图红框中的代码去掉,或者输出到日志文件中。
3. 任务启动失败,报资源不足:Could not allocate all requires slots within timeout of xxxx ms
问题现象
任务启动一段时间后报错,例如如下日志,需要60个资源实际上只有54个。

原因分析
Flink任务在启动过程中的资源使用是先增长在下降到当前值的,实际在启动过程中需要的资源量等于每个算子并行度之和。等到任务开始运行后,Flink会对资源进行合并。
例如如下算子,在启动过程中需要“1+6+6+5+3=21”个资源。
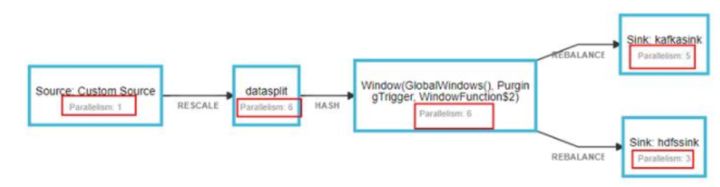
但是运行稳定后会降低到6。这个是Flink的机制。假如任务在启动过程中不满足21个资源的启动资源量,任务就会出现NoResourceAvailableException的异常。
解决方案
减少任务的启动并发,或者将其它任务kill掉再启动Flink任务。
4. 算子的部分节点产生背压,其它节点正常
问题现象
业务运行一段时间以后,算子的部分节点出现背压。

原因分析
通过Flink原生页面排查这个并发的算子所在的节点,通过上图我们能够看出是异常算子的第44个并发。通过前台页面能够查看并确认第44并发所在的节点,例如下图:

通过查找这个节点在taskmanager列表,例如下图位置:

整理taskmanager在每个nodemanager节点的数量发现,背压节点启动的taskmanager数量过多。
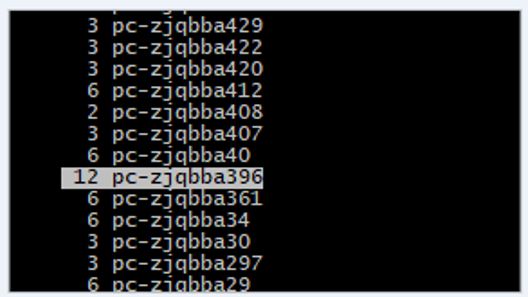
经过排查,该yarn集群资源相对比较紧张,每个节点启动的taskmanager数量不一致,如果部分节点启动的较多容易出现数据倾斜。
解决方案
建议一个节点启动多个slot。避免多个taskmanager出现在一个nodemanager节点上。启动方式见:slot优化。
FAQ
Flink如何加载其它目录的jar包
需求描述
Flink业务一般在运行过程中默认加载的jar包路径为:“xxx/Flink/flink/lib”的目录下,如果添加其它路径的jar包会报错,如何添加其它外部依赖。
实现方案
创建一个外部的lib目录,将部分依赖包放到外部lib目录下,如下图:

修改启动脚本的参数配置脚本,config.sh将jar包路径传给环境变量中。

此时正常启动任务即可,不需要加其它参数。

HDFS上也能看到第三方jar的目录。

如何收集任务taskmanager的jstack和pstree信息
需求描述
在任务运行过程中我们通常需要对taskmanager的进程进行查询和处理,例如:打jstack,jmap等操作,做这些操作的过程中需要获取任务的taskmanager信息。
实现方案
获取一个nodemanager节点上面所有taskmanager的进程信息的方法如下:
ps -ef | grep taskmanager | grep -v grep | grep -v "bash -c"

其中红框中的内容就是taskmanager的进程号,如果一个节点上面存在多个taskmanager那么这个地方会有多个进程号。获取到进程号后我们可以针对这个进程号收集jstack或者pstree信息。
收集jstack
1.通过上面流程获取到进程信息,然后从中获取进程ID和application id,如上图中进程id为“30047 applicationid为application_1623239745860_0001”。

2.从FI前台界面获取这个进程的启动用户。如下图为flinkuser。

3.在对应的nodemanager节点后台切换到这个用户,人机用户机机用户即可。

4. 进入到节点所在的jdk目录下

5. 给taskmanager进程打jstack。


不同用户提交的taskmanager只能由提交任务的用户打jstack。
收集pstree信息
使用pstree –p PID 的方式能够获取taskmanager的pstree信息,这个地方提供一个收集脚本。内容如下:
#!/bin/bash
searchPID()
local pids=`ps -ef | grep taskmanager | grep -v grep | grep -v "bash -c" | grep -v taskmanagerSearch.sh | awk 'print $2'`;
time=$(date "+%Y-%m-%d %H:%M:%S")
echo "checktime is --------------------- $time" >> /var/log/Bigdata/taskManagerTree.log
for i in $pids
do
local treeNum=$(pstree -p $i | wc -l)
echo "$i 's pstree num is $treeNum" >> /var/log/Bigdata/taskManagerTree.log
done
searchPID该脚本的功能为获取节点上所有taskmanager pstree的数量,打印结果如下:

slot优化
需求描述
Slot可以认为是taskmanager上面一块独立分配的资源,是taskmanager并行执行的能力的体现。Taskmanager中有两种使用slot的方法:
- 一个taskmanager中设置了一个slot。
- 一个taskmanager中设置了多个slot。
每个task slot 表示TaskManager 拥有资源的一个固定大小的子集。假如一个taskManager 有三个slot,那么它会将其管理的内存分成三份给各个slot。资源slot化意味着一个subtask 将不需要跟来自其他job 的subtask 竞争被管理的内存,取而代之的是它将拥有一定数量的内存储备。需要注意的是,这里不会涉及到CPU 的隔离,slot 目前仅用来隔离task 的受管理的内存。通过调整task slot 的数量,允许用户定义subtask 之间隔离的方式。如果一个TaskManager 一个slot,那将意味着每个task group运行在独立的JVM 中(该JVM可能是通过一个特定的容器启动的),而一个TaskManager 多个slot 意味着更多的subtask 可以共享同一个JVM。而在同一个JVM 进程中的task 将共享TCP 连接(基于多路复用)和心跳消息。它们也可能共享数据集和数据结构。因此,对于资源密集型任务(尤其是对cpu使用较为密集的)不建议使用单个taskmanager中创建多个slot使用,否则容易导致taskmanager心跳超时,出现任务失败。如果需要设置单taskmanager多slot,参考如下操作。
单taskmanager多slot的设置方法
方式一:在配置文件中配置taskmanager.numberOfTaskSlots,通过修改提交任务的客户端配置文件中的配置flink-conf.yaml配置,如下图:将该值设置为需要调整的数值即可。

方式二:启动命令的过程中使用-ys命令传入,例如以下命令:
./flink run -m yarn-cluster -p 1 -ys 3 ../examples/streaming/WindowJoin.jar
在启动后在一个taskmanager中会启动3个slot。
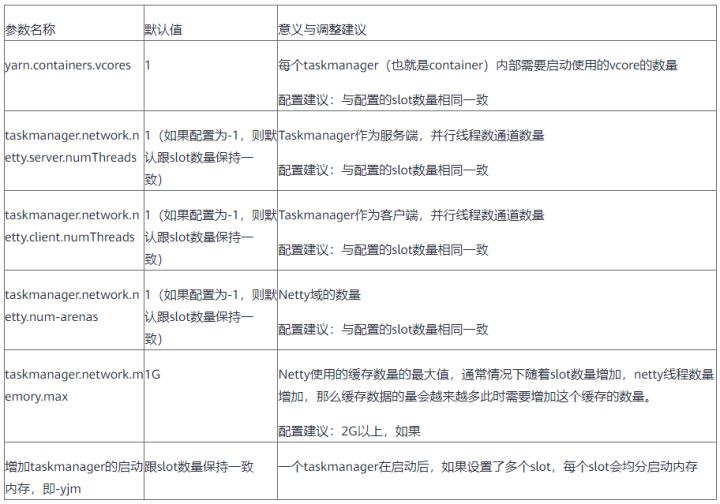
单taskmanager多slot需要优化哪些参数
设置单taskmanager多slot需要优化以下参数
以上是关于带你认识FusionInsight Flink:既能批处理,又能流处理的主要内容,如果未能解决你的问题,请参考以下文章
FusionInsight MRS Flink DataStream API读写Hudi实践
Superior Scheduler:带你了解FusionInsight MRS的超级调度器