python如何抓取网页源代码中的字符串
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python如何抓取网页源代码中的字符串相关的知识,希望对你有一定的参考价值。
我想提取一段字符串,如图中红圈表示
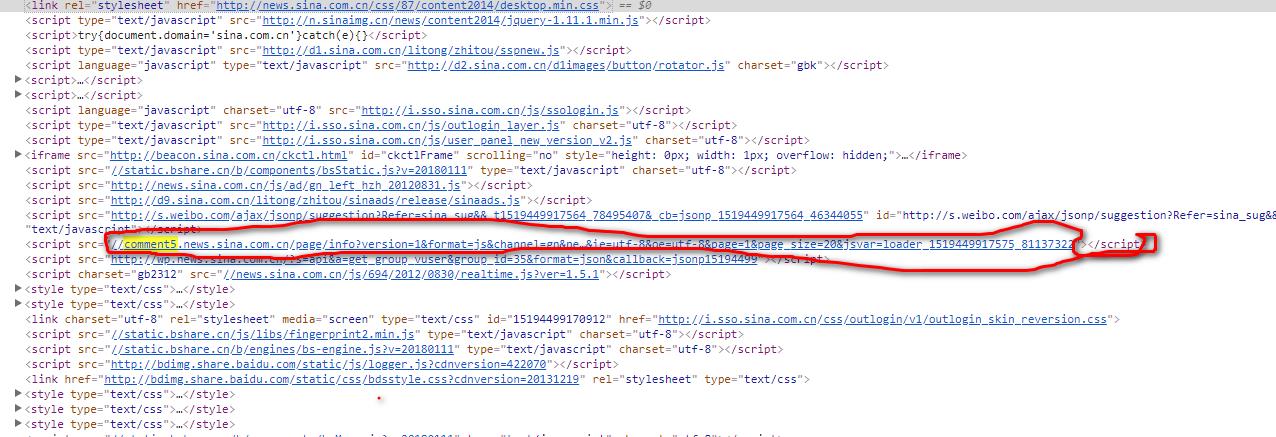
找前后关键字
python可以很方便地抓取网页并过滤网页的内容,那么,如何从如下的网页中提取良玉的博客blog.uouo123.com。
<script type="text/ecmascript">
window.quickReplyflag = true;
</script>
<div id="article_details" class="details">
<div class="article_title">
<span class="ico ico_type_Original"></span>
<h1>
<span class="link_title"><a href="/u013074465/article/details/44280335">
良玉的博客blog.uouo123.com
</a></span>
</h1>
</div>
如下是核心代码,使用正则表达式实现:
html2 = opener.open(page).read()
allfinds2 = re.findall(r'<span class="link_title"><a href="/u013074465/article/details/........">\r\n(.+?)</a></span>',html2, re.S)
print allfinds2[0].strip()
第一行:打开链接,page指向的是所要提取的文章标题的链接;
第二行:当读取到了连接的内容后,使用正则表达式进行匹配。这里要匹配的字符串的尾部是</a></span>,要匹配最近的</a></span>需要注意下面黑体字部分: 参考技术A
使用正则匹配,列:
import requestsimport re
req = requests.get(url)
r = re.findall('<script src="(.*?)"></script>', req.text) # (.*?) 非贪婪匹配
print(r)
自己网上找找python正则方面的知识
如何使用 Python 识别抓取网页中的完整句子
【中文标题】如何使用 Python 识别抓取网页中的完整句子【英文标题】:How to identify full sentences in a scraped web page with Python 【发布时间】:2022-01-23 06:38:28 【问题描述】:我目前正在从事一个学校项目,并尝试分析不同网页上的文章。在 BeautifulSoup 的帮助下,我能够从内容中清除所有代码部分。
现在,我想清除其他部分,例如菜单、站点地图条目、按钮等,以便仅将完整的句子作为网页中的文本。你知道我是如何识别完整句子的吗
The sequel trilogy is the third installment of films of the Star Wars saga to be produced.
但要清除作为一个组没有意义的单词,如导航
Explore Trending Navigation About Us Community
我已经使用了词的标记化,但这通常用于清理单数/复数、结尾、停用词等意义上的单词。我希望文本像它所写的那样,但没有“噪音”。
我希望我能够以一种可以理解的方式描述我的问题。
【问题讨论】:
创建一个set,其中包含您要列入黑名单的字词,然后检查该字词是否在set 中并跳过打印
@MendelG 不幸的是,单词总是会改变,因为它应该是从不同网页获取文本作为句子的通用解决方案(运行时未知)。
您可以尝试查找标签,这样您就不会从找不到您需要的文本的标签中获取文本,或者从可能位于文本的标签中获取文本,例如仅从段落和标题标签。此外,通过检查第一个字母是否大写并以逗号结尾,分别检查您从中获取文本的每组标签
【参考方案1】:
1.快速基于规则的解决方案:language-tool 该库允许您检测语法错误和拼写错误
示例用法:
import language_tool_python
tool = language_tool_python.LanguageTool('en-US')
text = 'A sentence with a error in the Hitchhiker’s Guide tot he Galaxy'
matches = tool.check(text)
len(matches)
2
查看一些 Match 对象属性:
matches[0].ruleId, matches[0].replacements # ('EN_A_VS_AN', ['an'])
('EN_A_VS_AN', ['an'])
matches[1].ruleId, matches[1].replacements
('TOT_HE', ['to the'])
打印一个匹配对象:
print(matches[1])
Line 1, column 51, Rule ID: TOT_HE[1]
Message: Did you mean 'to the'?
Suggestion: to the
2如果这对您不起作用,请尝试基于深度学习的解决方案。您必须为句子正确性训练一个文本分类模型。您可以在 语言可接受性语料库 (CoLA) 数据集上训练您的模型,如 this tutorial BERT 中所述。 colab-notebook 可能需要一些调试。 Another tutorial.
3. 更好的解决方案是修改基于 T5 的 sentence doctor。它试图纠正在句子中发现的错误或错误。您只需要知道一个句子是否正确,因此您必须修改此模型的最后一层,然后进行微调。 GPU 内存可能是一个限制,因为 T5 很大。
【讨论】:
以上是关于python如何抓取网页源代码中的字符串的主要内容,如果未能解决你的问题,请参考以下文章
[python 2.7抓取网页]如何抓取.js里面的内容(下拉框里面的中文字符列表)