python怎样抓取网页中的文字和数字数据
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python怎样抓取网页中的文字和数字数据相关的知识,希望对你有一定的参考价值。
以下代码在 py2 下运行通过:
import urllib2req = urllib2.Request('https://www.baidu.com/') # 创建一个 Requset 对象
response = urllib2.urlopen(req) # 调用 urlopen
the_page = response.read() # 返回一个 response 对象 在 response 中调用 read()
print the_page
运行效果:
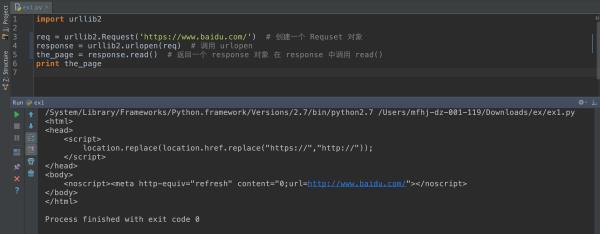
python怎样抓取securecrt上的数据
通过execl执行是有区别的,通过命令行执行解释器文件就像通过命令行执行普通程序一样,程序名称作为第一个参数,命令行后面依次作为后续参数。正因为对于解释器文件的execl方式和命令行方式执行时选取第一个参数的方式不同,所以对于解释器文件a.py:(1) 在命令行输入:./a.py arg1 arg2;
(2) execl("./a.py","arg1","arg2",(char*)0));
(3) execl("./a.py",”xxx”,"arg1","arg2",(char*)0));
方式(1)和方式(2)不等价,因为方式(1)中arg1会被当做第二个参数传递给解释器,而方式(2)中arg2会被当做第二个参数传递给解释器。方式(1)和方式(3)是等价的。
对于普通文件foo:
(1) 在命令行输入: ./foo arg1 arg2;
(2) execl("./foo","arg1","arg2",(char*)0))
方式(1)和方式(2)是等价的。 参考技术A 抓取网页数据的方法:
1,BeautifulSoup 处理一下, 修复一些格式上的问题;
2,用lxml提供的xpath解析器抽取网页内容到dict中;
3,用json库将dict转变成JSON;
4,用pymysql库提供的数据库api, 将JSON存储到数据库中。 参考技术B 围观python的众多功能,学习中。。 参考技术C securecrt有脚本功能,支持python语言 参考技术D python有ssh模块,请百度关键字:python ssh
以上是关于python怎样抓取网页中的文字和数字数据的主要内容,如果未能解决你的问题,请参考以下文章