深圳房价线性回归分析及预测= =
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深圳房价线性回归分析及预测= =相关的知识,希望对你有一定的参考价值。
1.数据清洗
data = data.rename(columns={‘Unnamed: 0‘: ‘id‘})
给第一列起名id
data = data[data[‘Rooms‘] != ‘Unknown‘]
data[‘Rooms‘] = data[‘Rooms‘].astype(int)
data[‘Living Rooms‘] = data[‘Living Rooms‘].astype(int)
data[‘Height‘] = data[‘Height‘].astype(int)
data = data[data[‘Undergroud‘] != ‘Unknown‘]
data[‘Undergroud‘] = data[‘Undergroud‘].astype(int)
data[‘Distance To Underground‘] = data[‘Distance To Underground‘].astype(int)
# print data.describe()
挑出datda中‘Room‘这一列中的‘Unknown‘,并将这一列转化成int形式的数据,然后对‘Living Rooms‘,‘Height‘等数值型数据做了同样的处理(应该可以做个循环?)
# print data.groupby(‘Rooms‘).count()
data = data[(data[‘Rooms‘] > 0) & (data[‘Rooms‘] < 8)]
data = data[data[‘Rooms‘] > data[‘Living Rooms‘]]
把‘Rooms‘计数,发现有0间房间,8间以上房间的屋子,故剔除并重新赋值给data,又剔除‘Living Rooms‘比‘Rooms‘还多的异常数据。
(另,# print data.groupby(‘Rooms‘).count()这个跑出来有好多列相同的,所以后来后面加了[‘price‘])
# plt.plot(data[‘Price‘],‘o‘,alpha = 0.5)
# plt.show()
# plt.plot(data[‘Height‘],‘-‘,alpha = 0.5)
# plt.show()
data = data[(data[‘Price‘] < 5000)]
然后‘Price‘,‘Height‘画图,‘Height‘没有异常值,约束‘Price‘小于5000
dummy_decoration = pd.get_dummies(data[‘Decoration‘], prefix=‘decoration‘)
dummy_Region = pd.get_dummies(data[‘Region‘], prefix=‘Region‘)
dummy_Orientation = pd.get_dummies(data[‘Orientation‘], prefix=‘Orientation‘)
dummy_Floor = pd.get_dummies(data[‘Floor‘], prefix=‘Floor‘)
dummy_Elevator = pd.get_dummies(data[‘Has Elevator‘], prefix=‘Elevator‘)
处理字符型变量,都用的哑变量(或许?可以建立个函数直接调用?)
data = pd.merge(data, dummy_decoration, right_index=True, left_index=True)
data = pd.merge(data, dummy_Region, right_index=True, left_index=True)
data = pd.merge(data, dummy_Orientation, right_index=True, left_index=True)
data = pd.merge(data, dummy_Floor, right_index=True, left_index=True)
data = pd.merge(data, dummy_Elevator, right_index=True, left_index=True)
把新建的哑变量粘到data上(靠,好傻,应该写个函数调用的)
# X=data.loc[:,(‘Size‘,‘Rooms‘,‘Living Rooms‘,‘Height‘,‘Undergroud‘,
# ‘Distance To Underground‘,‘dummy_decoration‘,‘dummy_Region‘,
# ‘dummy_Orientation‘,‘dummy_Floor‘,‘dummy_Elevator‘)]
# print X
到这里报错了,后来明白了,因为data里面并没有dummy_decoration,而是decoration_delicate/simple之类,故。。。弃
X = data
# print X.columns
看一下X里面的变量名
X = X.drop([‘id‘, ‘Built Year‘, ‘Region‘, ‘Decoration‘, ‘Floor‘, ‘Orientation‘, ‘Has Elevator‘, ‘Price‘,
‘Year Of Property‘, ‘Tag‘], axis=1)
# print X.info()
Y = data[‘Price‘]
不再选,而是舍弃data中的一些变量,作为X(可是为什么要看X的空值来着?),把‘Price‘赋给Y,到这里,我的数据就处理完了。
然后就可以对‘Train.csv‘动手了,但是对‘Test.csv‘依旧要做一样的数据处理,所以写了个函数:
def SZ(data):
。。。
中间就是上面的数据处理过程
。。。
return X,Y
数据处理,以上#
2.线性回归
读取数据:
data1=pd.read_csv(‘Train.csv‘)
X_train=SZ(data1)[0]
Y_train=SZ(data1)[1]
data2=pd.read_csv(‘Test1.csv‘)
X_test=SZ(data2)[0]
Y_test=SZ(data2)[1]
对Train中数据做线性回归,求线性系数,并带入X_test,得到Y_pred:
linreg=LinearRegression()
linreg.fit(X_train,Y_train)
print linreg.get_params()
print linreg.coef_
print linreg.intercept_
Y_pred = linreg.predict(X_test)
求MAPE等评价上面求得的线性模型:
print "MAE:",metrics.mean_absolute_error(Y_test, Y_pred )
m=(Y_test - Y_pred )/Y_test
a=map(abs,m)
p=sum(a)/len(m)
print "MAPE:",p*100
print "R2:", metrics.r2_score(Y_test, Y_pred )
plt.plot(Y_test, Y_pred,‘o‘,alpha = 0.5)
plt.plot([0,4000],[0,4000],‘r--‘)
plt.show()
附一些结果:
MAE: 123.090078901
MAPE: 23.7656379369
MSE: 34517.8775484
RMSE: 185.78987472
R2: 0.805982042193
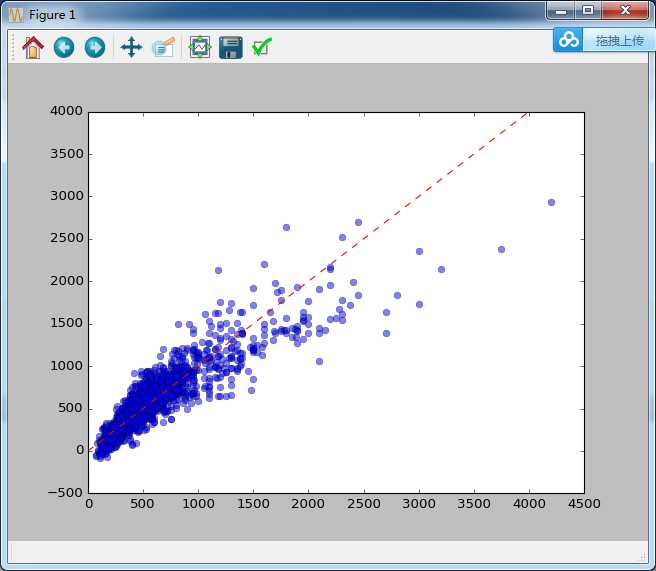
卒。。。
、
以上是关于深圳房价线性回归分析及预测= =的主要内容,如果未能解决你的问题,请参考以下文章
机器学习之利用线性回归预测波士顿房价和可视化分析影响房价因素实战(python实现 附源码 超详细)