优酷电视剧爬虫代码实现一:下载解析视频网站页面补充知识点:XPath无效怎么办?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了优酷电视剧爬虫代码实现一:下载解析视频网站页面补充知识点:XPath无效怎么办?相关的知识,希望对你有一定的参考价值。
XPath无效怎么办?明明XPath是通过定位子节点,copy xpath得到的,理论上是正确的
XPath无效怎么办?明明XPath是通过按F12定位符再copy XPath得到的,可是放在代码里就是不对呢?
前提:优酷电视剧爬虫代码实现一:下载解析视频网站页面(2)工作量已经完成。基于这个基础,进一步完善代码
1.新建页面解析接口。
package com.dajiangtai.djt_spider.service;
import com.dajiangtai.djt_spider.entity.Page;
/**
* 页面解析接口
* @author Administrator
*
*/
public interface IProcessService {
public void process(Page page);
}
2.新建页面解析实现类
package com.dajiangtai.djt_spider.service.impl;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.htmlcleaner.HtmlCleaner;
import org.htmlcleaner.TagNode;
import org.htmlcleaner.XPatherException;
import com.dajiangtai.djt_spider.entity.Page;
import com.dajiangtai.djt_spider.service.IProcessService;
import com.dajiangtai.djt_spider.util.HtmlUtil;
import com.dajiangtai.djt_spider.util.LoadPropertyUtil;
import com.dajiangtai.djt_spider.util.RegexUtil;
/**
* 优酷页面解析实现类
* @author Administrator
*
*/
public class YOUKUProcessService implements IProcessService{
//总播放量:
private String parseAllNumber = "/html/body/div[4]/div/div[1]/div[2]/div[2]/ul/li[11]";
public void process(Page page) {
String content = page.getContent();
HtmlCleaner htmlCleaner = new HtmlCleaner();
//利用htmlCleaner对网页进行解析,得到根节点
TagNode rootNode = htmlCleaner.clean(content);
try {
Object[] evaluateXPath = rootNode.evaluateXPath(parseAllNumber);
if(evaluateXPath.length>0){
//通过xpath,定位到该子节点,输出子节点信息
TagNode node = (TagNode)evaluateXPath[0];
System.out.println(node.getText().toString());
}
} catch (XPatherException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
3.新建电视剧爬虫入口类StartDSJCount,定义downLoadService、processService并生成get/set方法,同时,通过set方法对这两个接口进行实例化。利用之前的工作,封装页面下载和解析方法。再对页面解析进行测试。
package com.dajiangtai.djt_spider.start;
import com.dajiangtai.djt_spider.entity.Page;
import com.dajiangtai.djt_spider.service.IDownLoadService;
import com.dajiangtai.djt_spider.service.IProcessService;
import com.dajiangtai.djt_spider.service.IStoreService;
import com.dajiangtai.djt_spider.service.impl.ConsoleStoreService;
import com.dajiangtai.djt_spider.service.impl.HttpClientDownLoadService;
import com.dajiangtai.djt_spider.service.impl.YOUKUProcessService;
/**
* 电视剧爬虫入口类
* @author Administrator
*
*/
public class StartDSJCount {
//页面下载接口
private IDownLoadService downLoadService;
//页面解析接口
private IProcessService processService;
public static void main(String[] args) {
StartDSJCount dsj = new StartDSJCount();
//HttpClientDownLoadService实现DownLoadService接口
dsj.setDownLoadService(new HttpClientDownLoadService());
//YOUKUProcessService实现ProcessService接口
dsj.setProcessService(new YOUKUProcessService());
String url = "http://list.youku.com/show/id_z9cd2277647d311e5b692.html?spm=a2h0j.8191423.sMain.5~5~A!2.iCUyO9";
//下载页面
Page page = dsj.downloadPage(url);
//解析页面
dsj.processPage(page); //测试
}
//下载页面方法
public Page downloadPage(String url){
return this.downLoadService.download(url);
}
//解析页面方法
public void processPage(Page page){
this.processService.process(page);
}
public IDownLoadService getDownLoadService() {
return downLoadService;
}
public void setDownLoadService(IDownLoadService downLoadService) {
this.downLoadService = downLoadService;
}
public IProcessService getProcessService() {
return processService;
}
public void setProcessService(IProcessService processService) {
this.processService = processService;
}
}
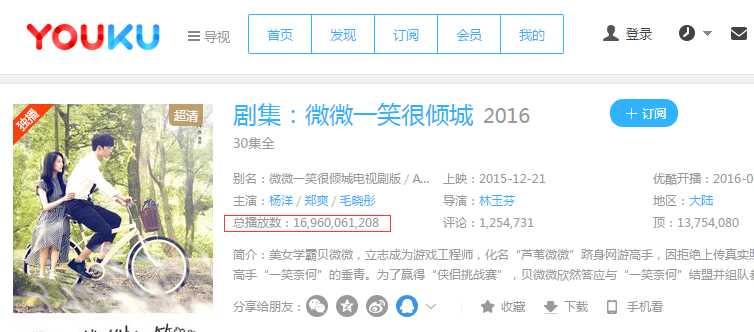
4.测试该main方法,若正确,则应该输出红色字段即: 总播放数:16,960,061,208
然而,控制台为空:
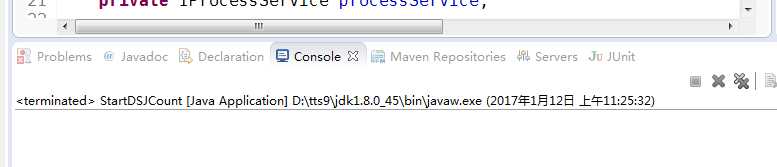
也就是,该xpath无效,解析失败。这里可以使用debug进行调试,一步步测试,最后发现,Object[] evaluateXPath = rootNode.evaluateXPath(parseAllNumber);的evaluateXPath 值为[],是什么原因导致解析失败呢?红色部分的xpath为"/html/body/div[4]/div/div[1]/div[2]/div[2]/ul/li[11]";,很明显,是绝对路径,具体为什么失败,目前我将它归结为绝对路径。自我总结,目前有两种解决方案:
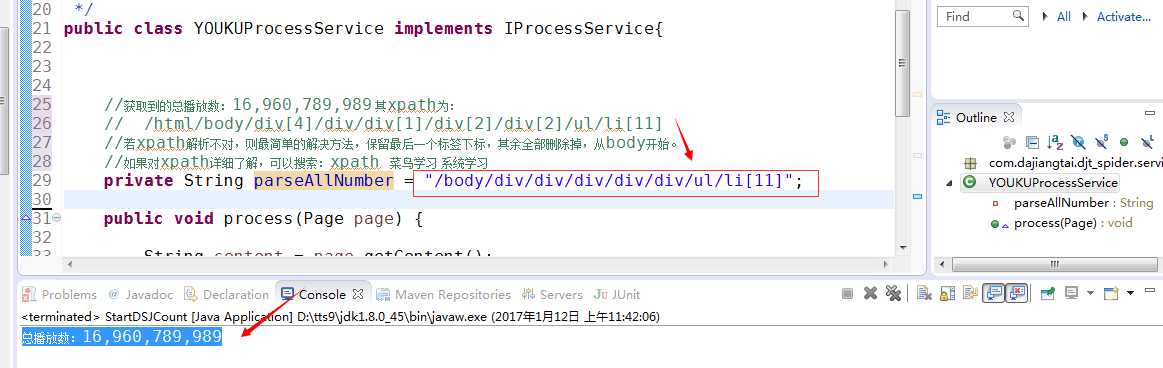
1.若xpath解析不对,则最简单的解决方法,保留最后一个标签下标,其余全部删除掉,从body开始。
2.自己改写成相对路径:"//div[@class=\\"p-base\\"]/ul/li[11]",这里是参考了http://www.cnblogs.com/miercler/p/5599465.html博客中xpath的写法。
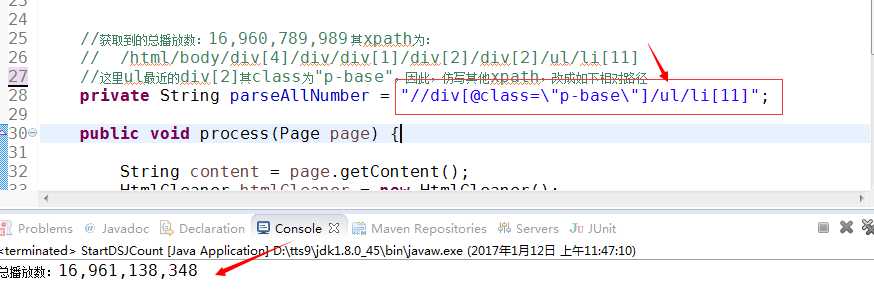
以上两种方法都可以解决xpath无效的问题!
以上是关于优酷电视剧爬虫代码实现一:下载解析视频网站页面补充知识点:XPath无效怎么办?的主要内容,如果未能解决你的问题,请参考以下文章