爬虫记一次某视频网站的加密解密
Posted 代码诠释的世界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫记一次某视频网站的加密解密相关的知识,希望对你有一定的参考价值。
1、起因
由于女友想看某网站付money视频,咱又不想充money,所以咱去网络上找在线解析的那种网站,下载下来,让其不用卡顿,不用手动复制黏贴,畅快的看视频
2、首先我们抓取电视剧的所有剧集链接
https://so.iqiyi.com/so/

反正输入视频链接搜索就完了,然后拿到页面的url

然后使用selenium和xpath去抓取即可

3、获取解析地址
由于要money,那么自然咱们是不能通过他们的网站去下载,所以只能去网上找那些免费的
自己随便找找好了, F12抓请求过程
可能遇到的问题,就是会进入调试模式
点击右上角,然后重新点击解析即可
4、获取视频的vkey
跟踪请求中的vkey,vkey的生成在一个html的js脚本中

一看就很懵是吧
本质上还是取得上面的数组

一看又很懵,16进制
那咱们给这些值打印出来看看下,将需要的东西都复制到一个python文件中

这一看不就有点头绪了吧, 这个不就是vkey的加密方式吗
那其实就是对url做了一层加密,然后作为vkey,然后去请求m3u8的视频地址,正是下载需要的地址
咱们只要可以生成vkey, 然后去请求解析地址,不就可以获取到m3u8的视频地址了吗
5、自动生成vkey
可以参考链接:https://blog.csdn.net/u010741112/article/details/121945796
6、那么咱就可以遍历视频地址获取m3u8地址了
7、然后咱们就可以下载视频了,可以使用ffmpeg获取其他工具
参考链接:
https://blog.csdn.net/u010741112/article/details/121945796
本文仅做学习使用,请勿用于非法用途
省略了很多东西,只提供思路
记一次破解前端加密详细过程
应工作需要爬过各种各样的航空公司网站,大到B2B平台,小到东南亚某某航空官网,从最初使用webdriver+selenium爬虫到现在利用http请求解析html,经历过各种各样的问题,webdriver+selenium这种办法虽然万能,而且可以用JS写解析脚本方便调试,但是用久了才发现这玩意不管是效率还是稳定性都非常差,放到服务器上动不动就挂掉,两三天就需要重启一次。后面头说让我们改用发http请求(我第一次接触项目的时候就在想为什么不直接用发http请求这种方式,我猜他也是第一次接触爬虫这个技术领域,没什么经验。而我,本来是招JAVA进的公司,后来JAVA、JS、Python写了个遍,emmm... 没事,反正技多不压身 ^_^),这种方式稳定且快,但是用Python编写解析脚本的时候你就知道进行调试有多烦,虽然可以用PyQuery或者BeautifulSoup这种解析库,但是还是不如写JS脚本在浏览器里调试来得舒服。
进入爬虫主题
要爬取的官网:https://www.jcairlines.com
接口地址:https://www.jcairlines.com/TicketSale/FlightQuery/QuerySeat
目标:根据参数爬取对应的航班信息
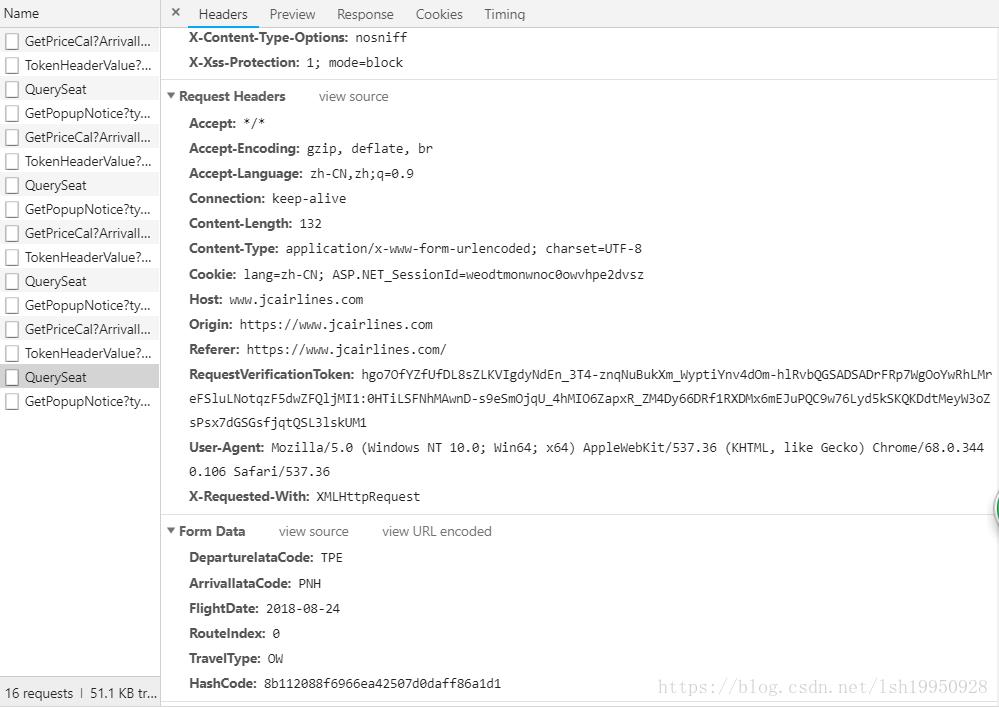
请求信息:
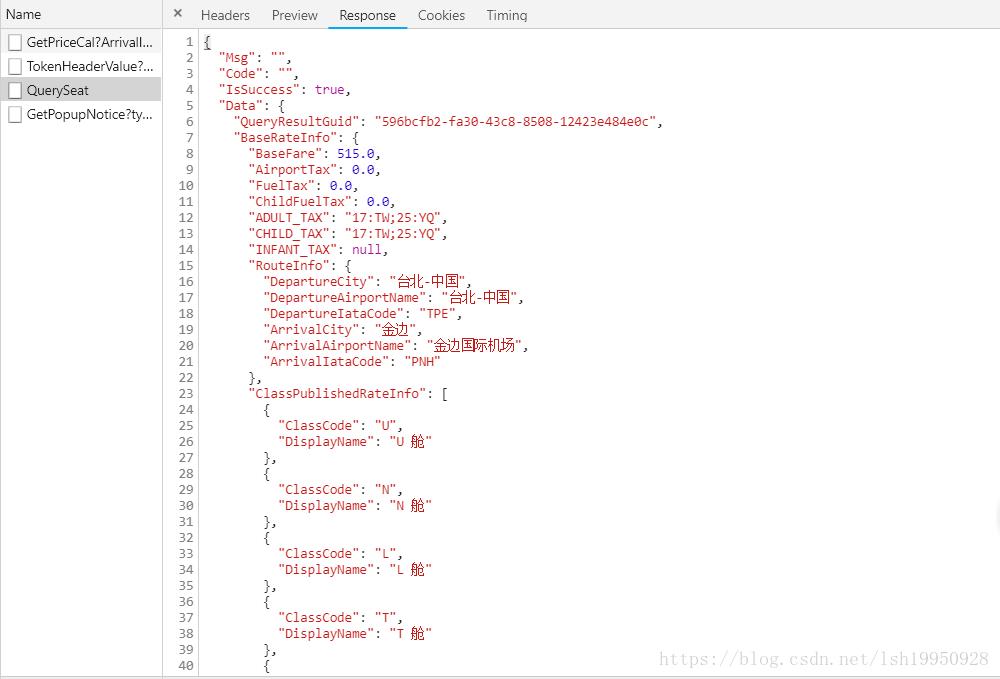
响应结果:
接口测试
从上面的第一张图可以看到有一个类似加密过的参数:HashCode,而其他的都是根据需要进行直接填充
{"DepartureIataCode":"TPE","ArrivalIataCode":"PNH","FlightDate":"2018-08-24","RouteIndex":"0","TravelType":"OW","HashCode":"8b112088f6966ea42507d0daff86a1d1"}下面将这个请求的完整信息放到Postman中跑一下,看看结果:
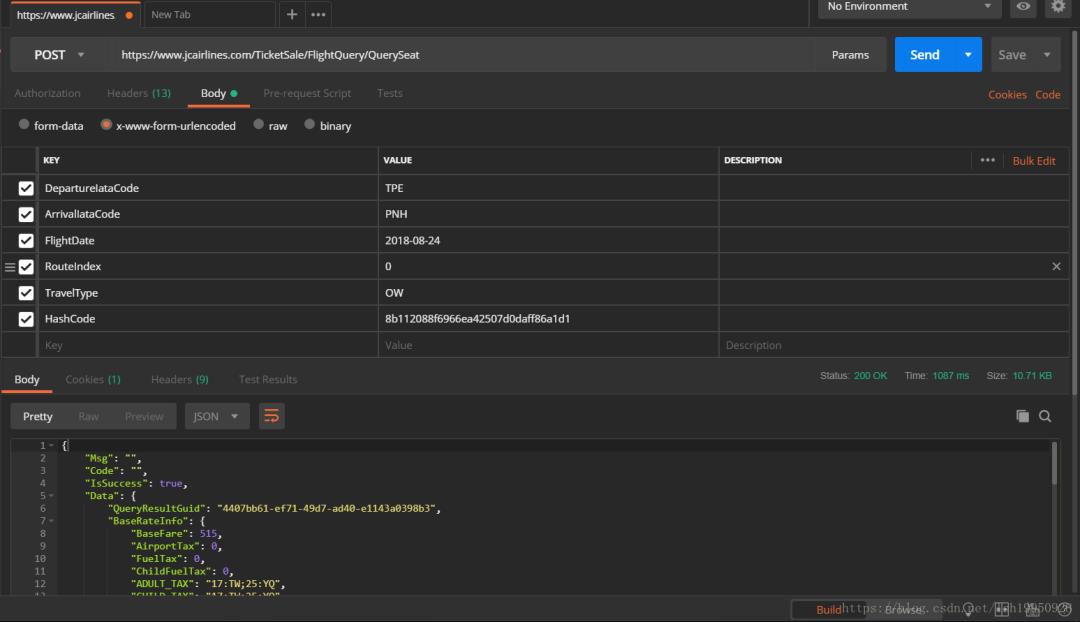
可以看到是没有问题的,能拿到结果,下面我们准备把HashCode去掉再请求一遍
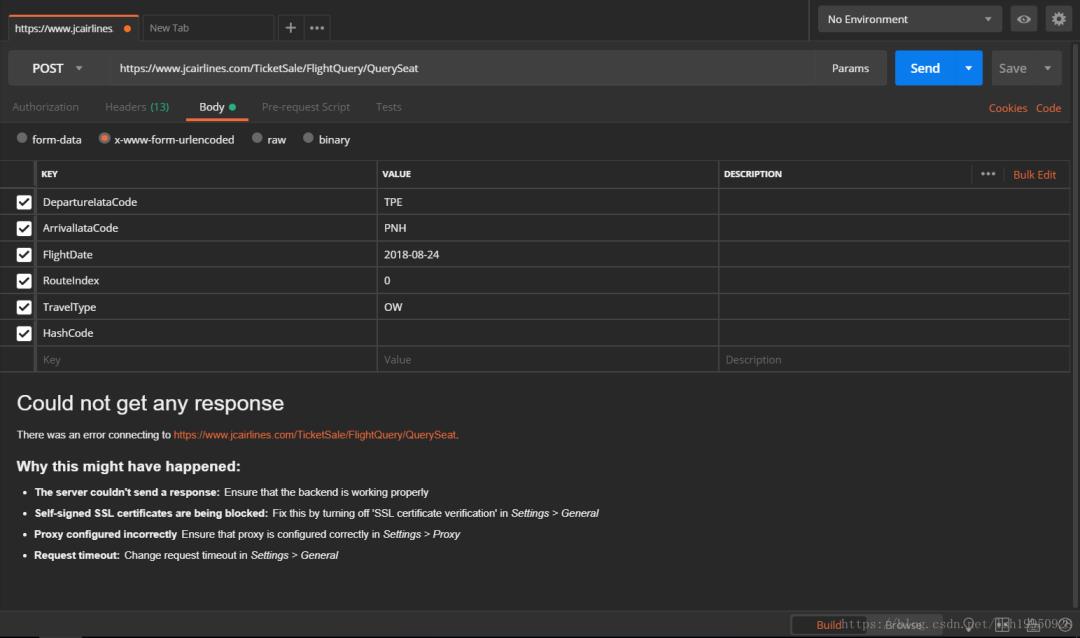
emmm... 直接不响应!!!
好吧,搞定这个问题就需要破解这个加密参数是怎么来的
正式破解
【逆向思维】这个肯定是Ajax请求之前生成的,那就用关键字找这个Ajax请求, 在Chrome中开发者模式,找到这网站的所有Source
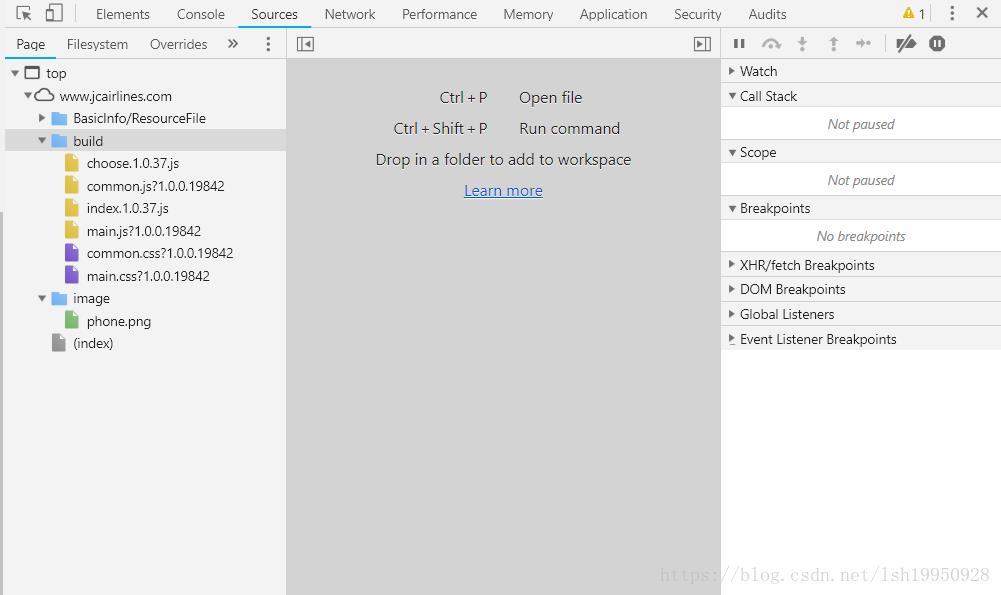
【关键字】"QuerySeat" 一大堆js文件一个一个找吧,运气很好,第一个就是,可以清楚的看到“POST”一词,那这一定就是一个Ajax请求咯,这里有一个技巧,一般情况下,服务器会对静态资源进行压缩,所以需要format才能看个大概
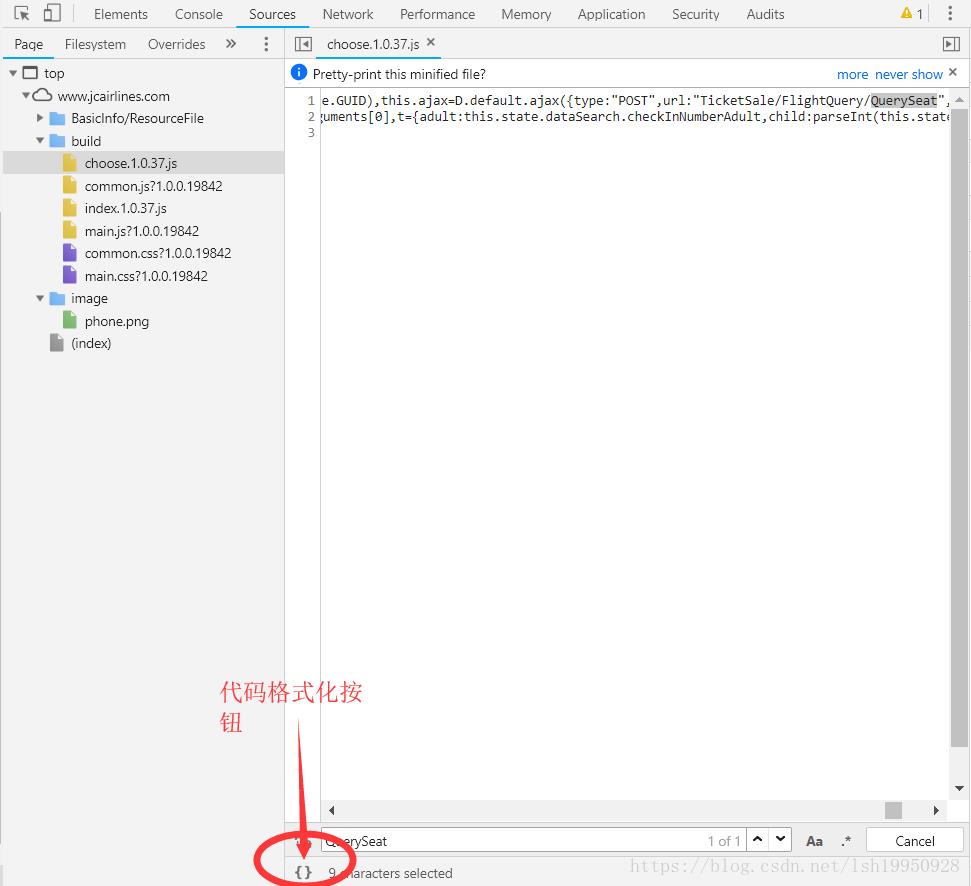
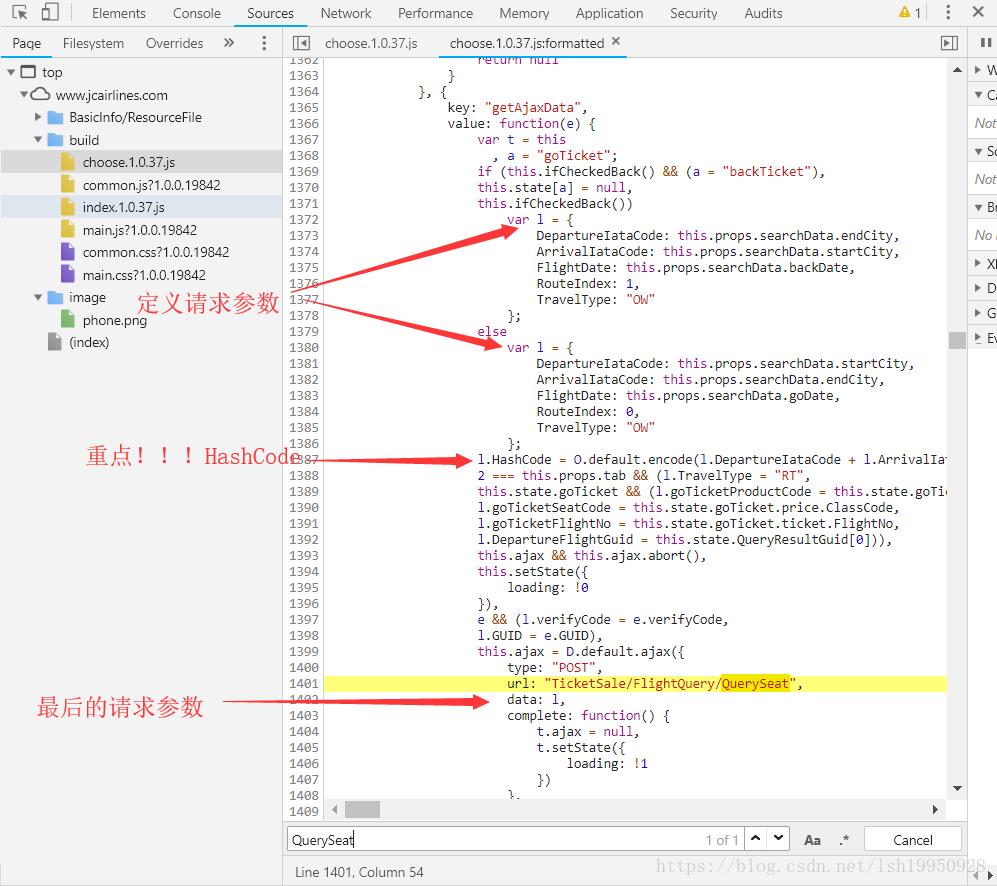
这样可以阅读代码了,然后轻松找到设置HashCode的地方,然后打一个断点,随便查一条航线的数据,如下图。
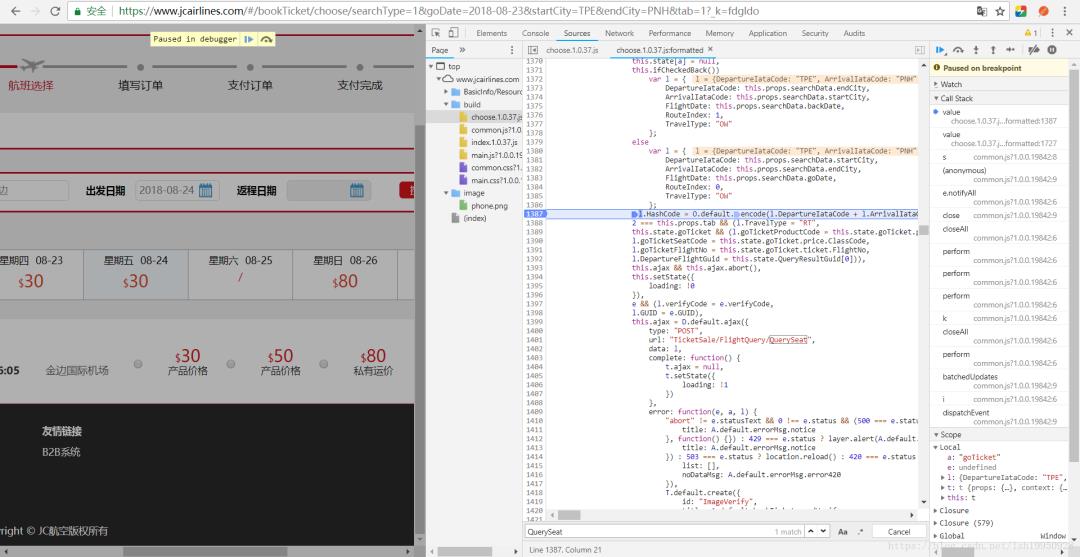
单步执行走到这一步,有些眉目了,执行到了encode指向的匿名函数这,里面代码看似应该是各种加密函数,不用读懂它,因为目标只是执行它,得到相应的结果就行了
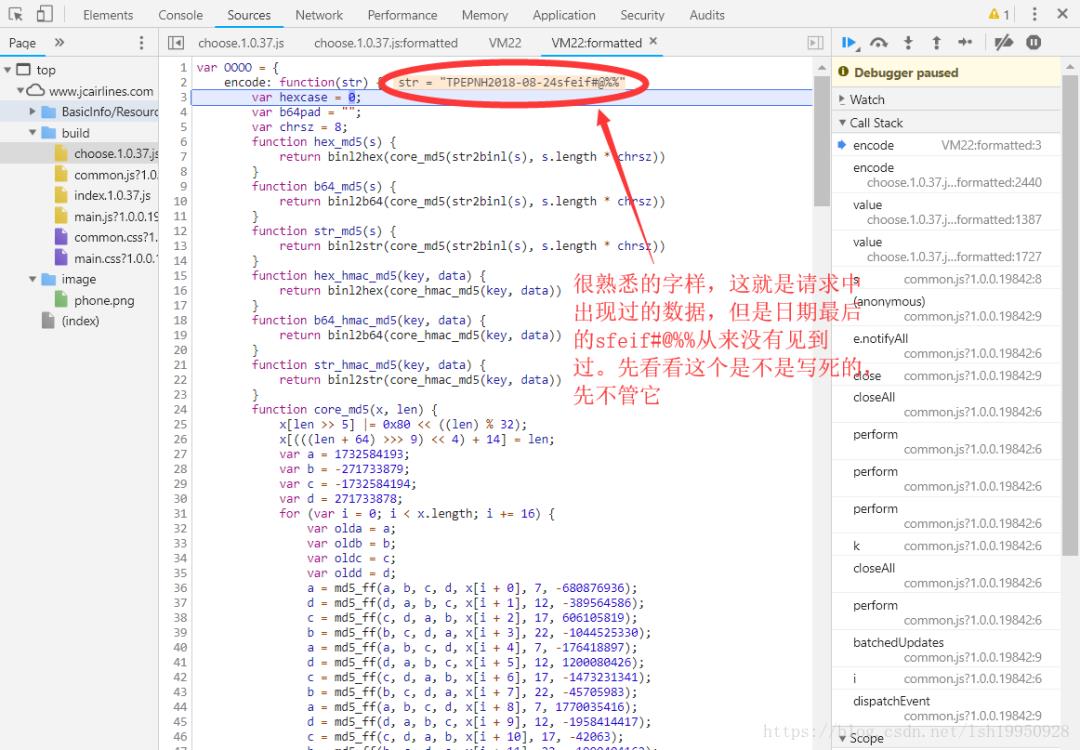
继续单步:

继续...
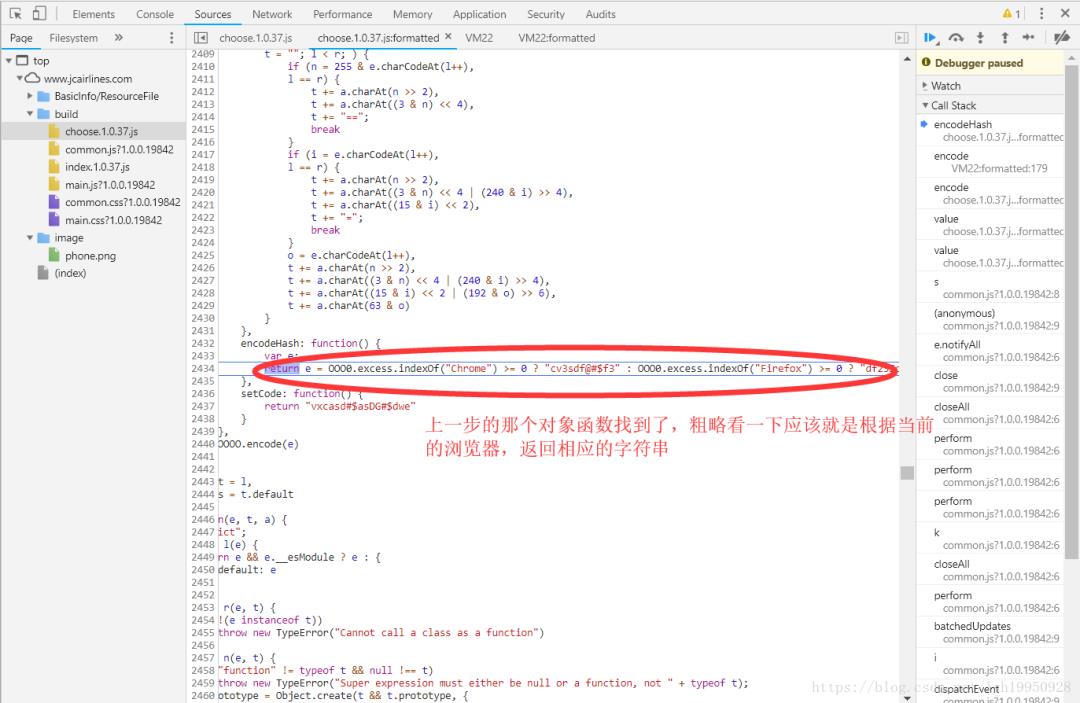
上图中重要的源码:
return e = OOO0.excess.indexOf("Chrome") >= 0 ? "cv3sdf@#$f3" : OOO0.excess.indexOf("Firefox") >= 0 ? "df23Sc@sS" : "vdf@s4df9sd@s2"返回到上层,没错和我想的一样,当前浏览器是Chrome,返回的是 cv3sdf@#$f3

继续...
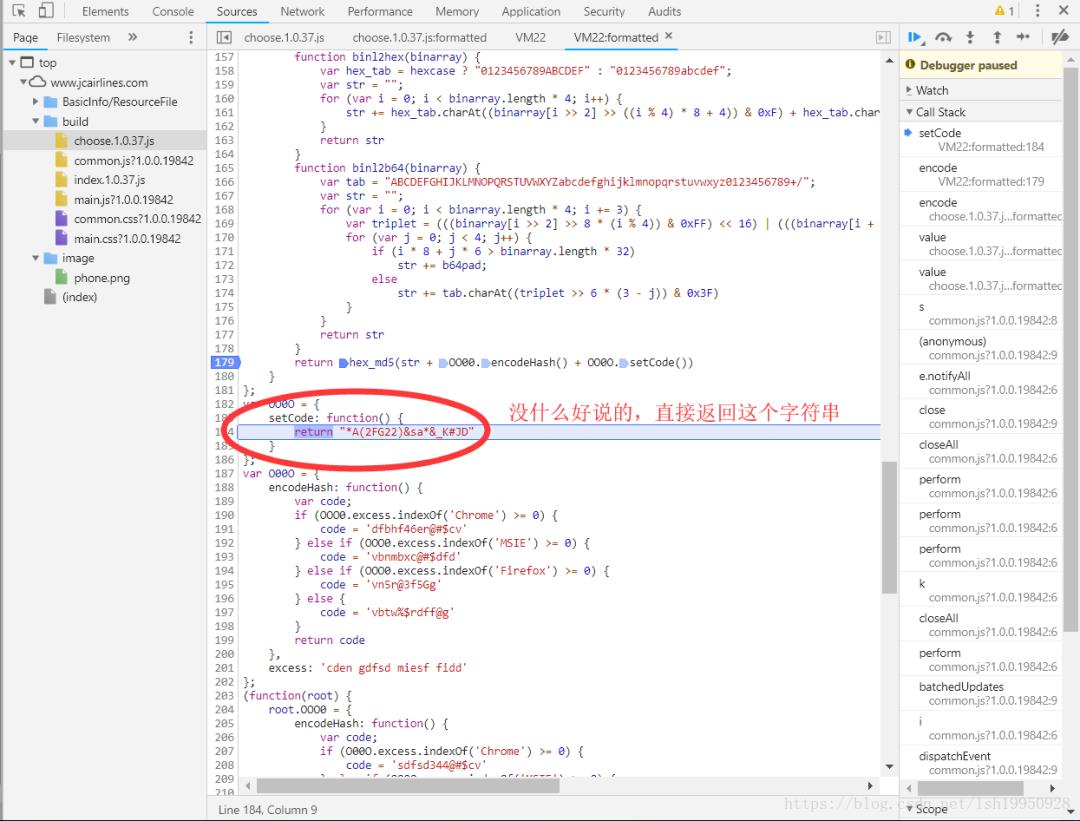
继续...

继续...
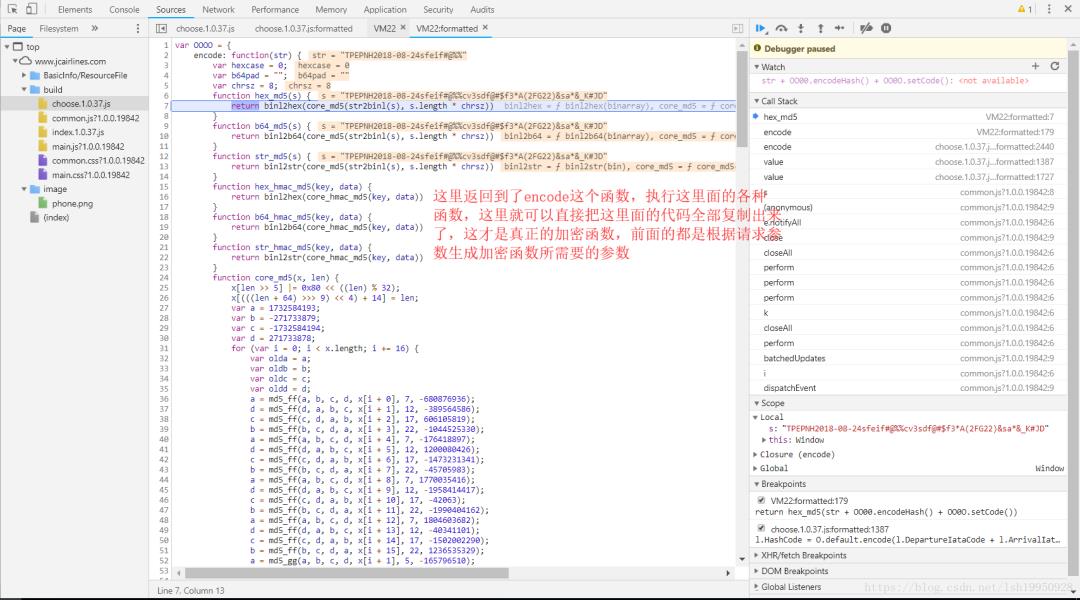
最终找到了这个匿名函数,复制encode所指向的函数,然后随便取一个名字,方便调用,另外,在另一个窗口中打开Console粘贴代码,如下图:
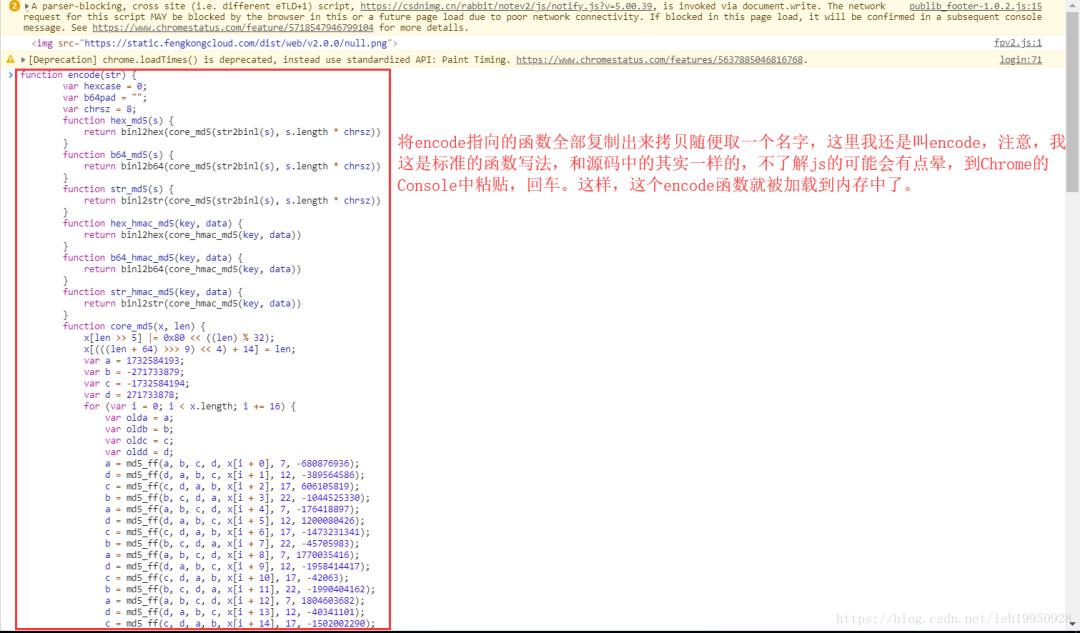
调用...(报错了)

替换成对应的字符串继续...
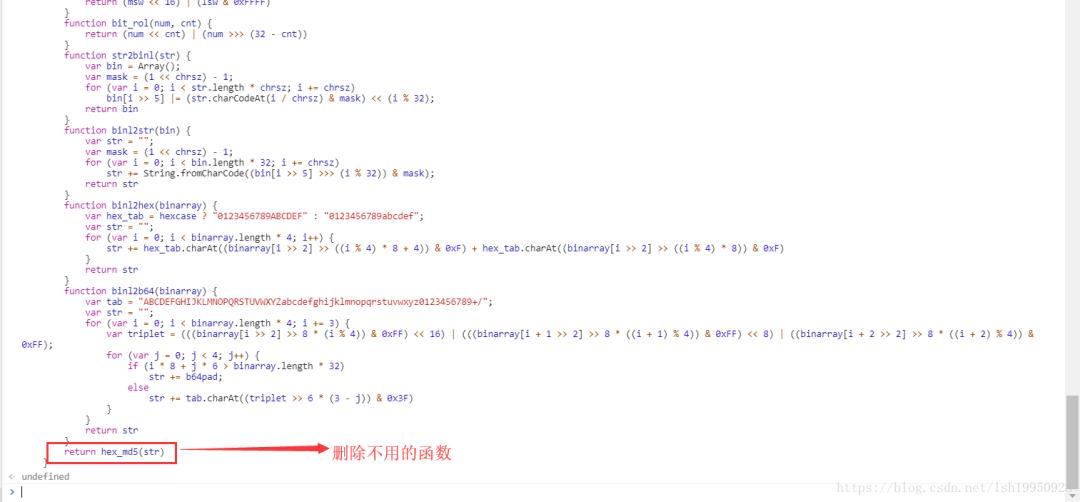
重新调用注入到Console 的encode函数,调用,得到结果!!!

对比最开始用Postman请求的地方,结果也一致!!!
还没有完,这里只是得到了js脚本,所以还需嵌入到Python代码中使用,常规方式有两种:使用Python第三方类库js2py和PyV8这两个都是能都执行js的Python类库,但是我还是推荐使用js2py,因为PyV8安装十分繁琐,具体使用我就不再赘述,网上有很多的教程和Case。
最后需要交代的:“sfei#@%%”这的到底是哪来的,也没有寻根,我就直接告诉答案,其实这个值就在当前的网页中,是一个js变量,且是一个固定值,这也是我不想寻根的原因,意义不大。另外在使用http爬虫的时候headers里面的内容也必须和HashCode相匹配,什么意思呢,之前代码出现过通过浏览器种类,生成不同的字符串,也就是说具体HashCode是和浏览器有关,所以在构造headers时需要填写对应的User-Agent,不然服务器进行校验的时候还是不会响应的,可以猜测服务器中也有一段功能相同的代码,它根据请求参数和headers中User-Agent进行加密计算,得到HashCode以此来验证请求的HashCode是否合法。
总结
前端加密还是能够破解出来的,关键在于锁定JS加密源码位置,并且提取出有用的加密代码,只要有使用过js的同学问题都不大。还有很多小细节得注意,服务器需要对请求做进一步验证,方式其实和前端是一样的以此来判断请求是否合法,至少这个网站是如此。
本文作者:TheUmbra
本文链接:https://blog.csdn.net/lsh19950928/article/details/81585881
推荐阅读
关注下方「前端开发博客」,回复 “加群”
加入我们一起学习,天天进步

如果觉得这篇文章还不错,来个【分享、点赞、在看】三连吧,让更多的人也看到~
以上是关于爬虫记一次某视频网站的加密解密的主要内容,如果未能解决你的问题,请参考以下文章