张冬:OpenPOWER CAPI为什么这么快?(二)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了张冬:OpenPOWER CAPI为什么这么快?(二)相关的知识,希望对你有一定的参考价值。
张冬:OpenPOWER CAPI为什么这么快?(二)
PMC公司数据中心存储架构师张冬
有了CAPI的FPGA是怎么做的?
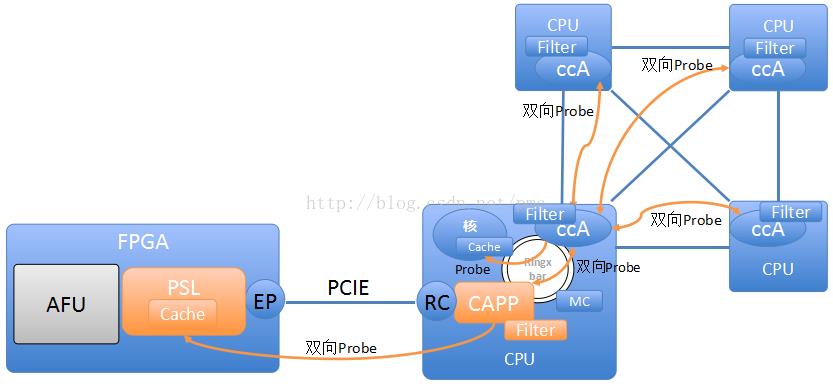
首先认识一下这个体系里的三个角色:
AFU(Acceleration Function Unit),主加速逻辑部分就是FPAG的加速芯片。用户能够把自己的加速逻辑和Firmware写进去。
PSL—Power Service Layer,提供接口给AFU用于读写主存和V2P地址翻译(与CPU側使用同一个页表,并包括TLB),同一时候负责Probe CAPP实现全局cc,并提供Cache。PSL由IBM作为硬核IP提供给FPGA开发人员。
CAPP—Coherent Attached Processor Proxy,相当于FPGA側的ccAgent,可是被放在了CPU側,其维护一个filter文件夹并接受来自其它CPU的Probe。未过滤掉的Probe转发PSL。
操作要点能够简要的概括为下面6点:
-
针对专用场景、PCIE专用加速卡进行优化;
-
FPGA直接訪问当前进程的所有虚拟地址空间。无需转成PCIE地址。
-
加速卡上能够使用Cache并通过CAPP的Probe操作自己主动与主存cc;
-
加速卡与CPU看到相同的地址空间而且cc;
-
提供API,包含打开设备、传递任务描写叙述信息等。相当于驱动程序;
-
PSL由IBM提供,硬核IP。
AFU通过opcode及地址控制PSL收发数据。
在此过程中,CAPI致力于把FPGA当成CPU的对等端,但这是一个特殊的CPU,对计算加速很快的,很高效的一个CPU。
优势在于:两边看到了一样的地址空间,FPGA看到的不再是PCIe空间了。所以就省去了映射地址这一环节。再就是FPGA一側能够有Cache,能够缓存主存里的数据,并且Cache是与主存一致的。
如今FPGA可直接訪问主存空间,但它不会訪问全部的物理空间,由于CAPI 1.0每一个时刻仅仅能给一个进程来用。CAPI会为进程会提供一个接口,打开FPGA之后发数据和指令。CAPI 2.0会让FPGA有一个分时复用机制,比方。每10毫秒跳一个线程,可是当前的FPGA不具备这个功能,仅仅能是谁用谁打开。
谁打开了FPGA就看到谁的虚拟空间。有了这样的机制以后就不须要映射了,再就是能够直接訪问内存地址了。还有Cache,基本就融入了全部的CPU了。就是一个对等、对称的关系。
性能能提高多少?
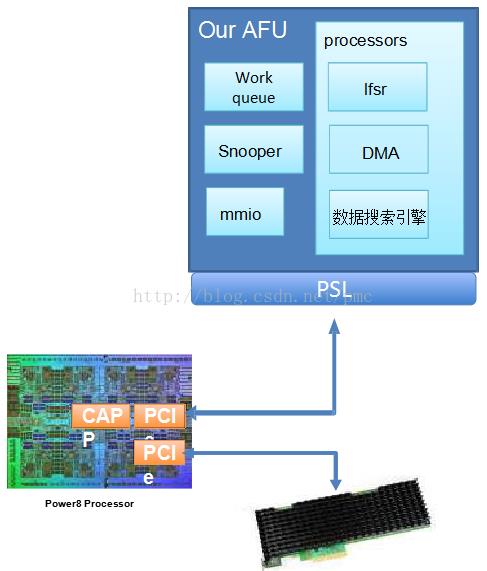
硬件配置是这种:
IBM Power8 Server, S822L
Ubuntu, kernel 3.18.0-14-generic
Nallatech 385 CAPI card
Samsung SM1715 1.6TB NVM ExpressSSD
測试时,?PMCproject师用FPGA制作了一个文本搜索引擎,如上图。
測试过程中,Host端主程序从NVMe SSD读入数据,并生成任务描写叙述链表,?AFU採用pooling的方式訪问主存获取任务描写叙述链表并运行搜索任务。Snooper用来debug和性能监控。
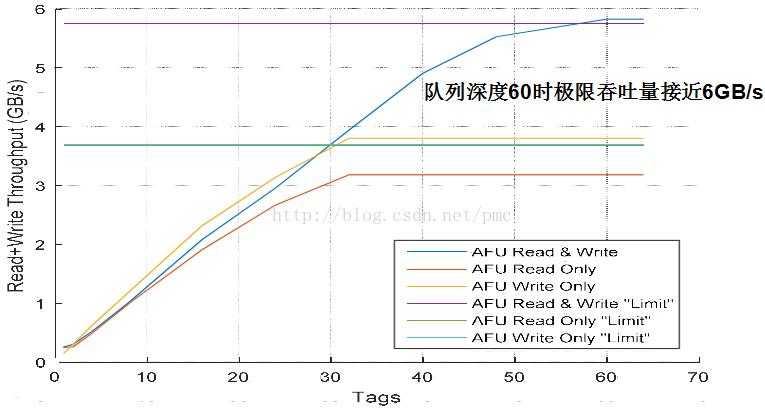
性能 – P8<->AFU
当队列深度60时的时候,获得一个极限吞吐量,接近6GB/s的带宽,带宽很大。

延时也非常小。仅仅有1.5微秒。平均90%读写在1.5微秒完毕。
CAPI1.0临时做不到的事情
如今CPU的线程看不到AFU上的地址空间(MMIO控制寄存器地址除外)。并且。AFU仅仅能给一个进程使用。
假设未来能够把FPGA直接接入CPU的FSB,是不是会更快?
以上是关于张冬:OpenPOWER CAPI为什么这么快?(二)的主要内容,如果未能解决你的问题,请参考以下文章
对话张冬洪 | 全面解读NoSQL数据库Redis的核心技术与应用实践
新的PGI编译器可将支持GPU的HPC应用从Linux/x86无缝迁移到支持NVLink的OpenPOWER+Tesla