英特尔® 至强融核? 处理器优化教程
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了英特尔® 至强融核? 处理器优化教程相关的知识,希望对你有一定的参考价值。
1. 简介
本教程将介绍多种优化应用,以支持其在英特尔? 至强融核? 处理器上运行。 本教程中的优化流程分为三个部分:
- 第一部分介绍用于对代码进行矢量化(数据并行化)处理的通用优化技巧。
- 第二部分介绍如何添加线程层并行化,以充分利用处理器中的所有可用内核。
- 第三部分将通过在英特尔至强融核处理器上启用内存优化,以优化代码。
最后的结论部分将通过图表方式展示各优化步骤所实现的性能提升。
优化过程如下:以串行、性能有待提升的示例代码为基础。 然后采用优化技巧处理该代码,获得矢量化版本的代码,并对该矢量化代码进行进一步的线程并行化处理,以使其成为并行版代码。 最后使用英特尔? VTune? Amplifier 分析该并行代码的内存带宽,以使用高带宽内存进一步优化性能。 本教程以附件形式提供这三个版本的代码(mySerialApp.c、myVectorizedApp.c 和 myParallelApp.c)。
示例代码为一个流处理应用,带有两个包含输入和输出的缓冲区。 第一个输入数据集包含二次方程系数。 第二个输出数据集用于保留每个二次方程式的根。 为简单起见,选择的系数可确保二次方程式始终求得两个实根。
考虑二次方程式:

两个根为已知公式的解:

求得两个实根的条件是 ![]() 和
和 
2. 硬件和软件
该程序在预生产英特尔? 至强融核? 处理器(型号 7250,68 个内核,时钟速度为 1.4 GHz,96 GB DDR4 RAM、16 GB 多通道动态随机存取存储器 (MCDRAM))上运行。 每内核 4 个硬件线程,因此该系统运行时共有 272 个硬件线程。 我们在该系统中安装了 Red Hat Enterprise Linux* 7.2、英特尔? 至强融核? 处理器软件版 1.3.1 和英特尔? Parallel Studio XE 2016 更新版 3。
如果需要查看系统的处理器类型和数量,可以使用 /proc/cpuinfo 显示输出。 例如:
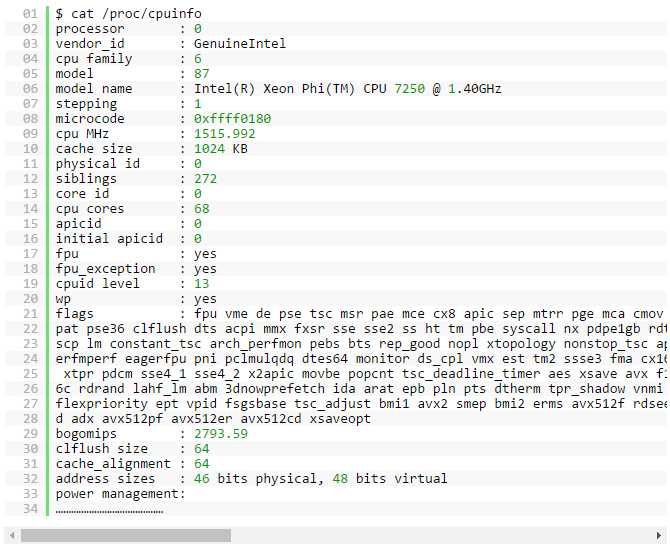
测试系统的完整输出显示了 272 个 CPU 或硬件线程。 请注意,标记字段显示了指令扩展 avx512f、avx512pf、avx512er、avx512cd;它们均为英特尔至强融核处理器支持的指令扩展。
还可以运行lscpu,显示有关 CPU 的信息:
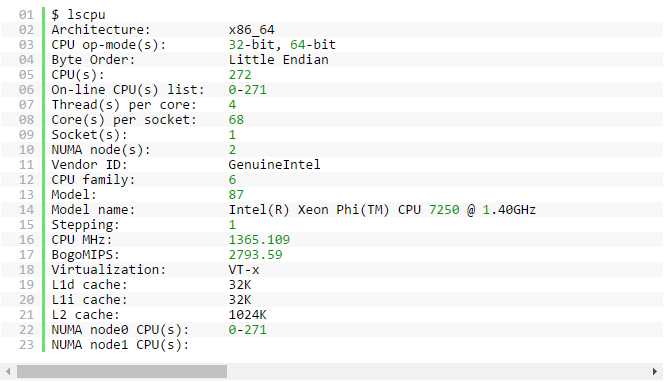
以上命令显示系统包含 1 个插座、68 个内核和 272 个 CPU。 它还显示该系统有 2 个 NUMA 节点,272 个 CPU 全部属于 NUMA 节点 0。 更多有关 NUMA 的信息敬请参阅 Knights Landing 上的 MCDRAM(高带宽内存)简介。
分析和优化示例程序之前,请编译该程序并运行二进制代码以获取基准性能。
3. 评测基准代码
随附的程序 mySerialApp.c 中展示了简单的解决方案实施。 系数 a、b 和 c 分成结构 Coefficients 组,根 x1和 x2 分成结构 Roots 组。 系数和根为单精度浮点数。 每个系数元组分别对应一个根元组。 程序将分配N 个系数元组和 N 个根元组。 N 的数值很大(N = 512M 元素,准确来说为 512*1024*1024 = 536,870,912 个元素)。 系数结构和根结构如下所示:

简单程序根据上述公式计算实根 x1 和 x2。 我们还使用标准系统计时器测量计算时间。 不测量缓冲区分配时间和初始化时间。 简单程序将计算流程重复 10 次。
开始时,通过使用英特尔? C++ 编译器编译基准代码,以评测应用的基准性能:
$ icc mySerialApp.c
默认情况下,编译器借助开关 -O2(面向最大速度优化)进行编译。 然后运行该应用:
$ ./a.out
No. of Elements : 512M
Repetitions = 10
Start allocating buffers and initializing ....
SERIAL
Elapsed time in msec: 461,222 (after 10 iterations)
输出显示,系统耗费了 461,222 毫秒对数量庞大的条目(N = 512M 元素)进行了 10 次迭代,以流处理数据、计算根并保存结果。 该程序为每个系数元组计算根元组。 注意,该基准代码无法充分利用系统中的大量可用内核或 SIMD 指令,因为它以串行和标量模式运行(每次仅一个线程处理一个元组元素)。 因此,仅一个硬件线程 (CPU) 处于运行状态,其他 CPU 均处于闲置状态。 你可以使用编译器选项 -qopt-report=5 -qopt-report-phase:vec 生成矢量化报告 (*.optrpt) 来验证这点。
$ icc mySerialApp.c -qopt-report=5 -qopt-report-phase:vec
测量基准代码性能后,我们开始对代码进行矢量化处理。
4. 代码矢量化
4.1. 将结构阵列改为阵列结构。 不要使用缓冲区分配中的多个层级。
提升代码性能的第一个方法是将结构阵列 (AoS) 改为阵列结构 (SoA)。 (SoA) 可增加单位步长访问的数据量。 我们不定义大量系数元组(a、b、c)和根元组的(x1、x2),而是重新安排数据结构,以便将其分配至 5 个大型阵列:a、b、c、x1 和 x2(参考程序 myVectorizedApp.c)。 另外,我们不使用 malloc 分配内存,而使用 _mm_malloc 使数据对齐 64 位边界(见下一章节)。

4.2. 其他性能提升方法:消除类型转换、数据对齐
下一步是消除不必要的类型转换。 例如,函数 sqrt() 将双精度视作输入。 但由于我们将单精度作为本程序的输入,因此编译器需要将单精度转化为双精度。 为了消除不必要的数据类型转换,我们可以使用 sqrtf(),而非 sqrt()。 同样,我们不使用整数,而使用单精度。 例如,我们不使用 4,而使用 4.0f。 注意,4.0(没有后缀 f)为双精度浮点数,而 4.0f 为单精度浮点数。
数据对齐有助于数据高效地在内存之间移动。 对英特尔至强融核处理器而言,当数据起始地址位于 64 字节边界时,内存数据移动可达到最佳状态,就像英特尔? 至强融核? 协处理器一样。 为帮助编译器进行矢量化,需要借助 64 位对齐进行内存分配,并使用编译指示/指令,其中数据可用于告知编译器内存访问已对齐。 最好借助适当对齐的数据进行矢量化。 本文中所述的矢量化指能够用单指令处理多个数据 (SIMD)。
在上述示例中,为对齐堆分配的数据,我们使用 _mm_malloc() 和 _mm_free() 来分配阵列。 注意,_mm_malloc() 相当于 malloc(),但它将对齐参数(以位为单位)用作第二个参数,即面向英特尔至强融核处理器的 64 位。 我们需要在数据前面插入一个子句,告知编译器使用的 assume_aligned(a, 64)表示阵列 a 已对齐。 为告知编译器特定循环中访问的所有阵列均已对齐,可在循环前面添加子句 #pragma vector aligned。
4.3. 使用自动矢量化、运行编译器报告,并通过编译器开关禁用矢量化
矢量化指使用矢量处理单元 (VPU) 同时运算多个值的编程技巧。 自动矢量化指编译器能够识别循环中的机会并执行相应的矢量化。 你可以充分利用英特尔编译器的自动矢量化功能,因为自动矢量化默认支持优化层 –O2 或更高层级。
例如,使用英特尔编译器 icc 编译 mySerialApp.c 示例代码时,编译器默认查找循环中的矢量化机会。 但编译器需要遵循一定的规则(必须知晓循环运行、单进单出、直线式代码、嵌套的最内层循环等等),以对这些循环进行矢量化处理。 你可以提供更多信息,帮助编译器对循环进行矢量化处理。
为确定代码是否已经实现矢量化,可以通过指定选项 -qopt-report=5 -qopt-report-phase:vec,生成矢量化报告。 之后编译器会生成一份矢量化报告 (*.optrpt)。 该报告会告诉你各循环是否已完成矢量化,并简要介绍循环矢量化。 注意,矢量化报告选项为 –qopt-report=<n>,其中的 n 用于规定细节等级。
4.4. 借助优化层 –O3 进行编译
现在我们可借助优化层 –O3 进行编译。 该优化层可实现最高速度,其优化程度远高于默认优化层 –O2 。
借助自动矢量化,编译器将 16 个单精度浮点数打包在矢量寄存器中并对该矢量执行运算,而不是在每个迭代循环中一次处理一个元素。
$ icc myVectorizedApp.c –O3 -qopt-report -qopt-report-phase:vec -o myVectorizedApp
编译器生成以下输出文件:二进制文件 myVectorizedApp 和矢量化报告 myVectorizedApp.optrpt。 如要运行二进制文件:
$ ./myVectorizedApp
No. of Elements : 512M
Repetitions = 10
Start allocating buffers and initializing ....
Elapsed time in msec: 30496 (after 10 iterations)
该二进制文件运行时仅使用一个线程,但使用了矢量化。 myVectorizedApp.optrpt 报告应确认是否所有内层循环都已完成矢量化。
进行对比时,还需使用 -no-vec 选项编译该程序:
$ icc myVectorizedApp.c –O3 -qopt-report -qopt-report-phase:vec -o myVectorizedApp-noVEC -no-vec
icc: remark #10397: optimization reports are generated in *.optrpt files in the output location
现在运行 myVectorizedApp–noVEC 二进制文件:
$ ./myVectorizedApp-noVEC
No. of Elements : 512M
Repetitions = 10
Start allocating buffers and initializing ....
Elapsed time in msec: 180375 (after 10 iterations)
这次 myVectorizedApp.optrpt 报告显示由于禁用了自动矢量化功能,因此循环没有完成矢量化,与预期一样。
现在我们可以观察到两次性能提升。 从原始版本(461,222 毫秒)到 no-vec 版本(180,375 版本)的性能提升主要得益于采用通用优化技巧。 从未矢量化版本(180,375 毫秒)到矢量化版本(30,496 毫秒)的性能提升主要得益于自动矢量化。
即使实现了性能提升,仍然只有一个线程执行运算。 支持多个线程并行运行,可进一步增强代码,从而充分利用多核架构。
5. 启用多线程化
5.1. 线程层并行化: OpenMP*
为充分利用英特尔至强融核处理器中数量庞大的内核(本系统中 68 个内核),可以通过并行运行 OpenMP 线程来扩展应用。 OpenMP 是面向共享内存的标准 API 和编程模型。
使用 OpenMP 线程时,需要包含头文件"omp.h"并连接代码和标记 –qopenmp。 在 myParallelApp.c 程序中,可在 for-loop 前添加以下指令:
#pragma omp parallel for simd
添加在 for-loop 前的编译指示可告知编译器生成一组线程并将 for-loop 中的工作分成多个数据块。 每个线程按照 OpenMP 运行时调度执行几个数据块。 SIMD 结构仅显示使用 SIMD 指令可同时执行的多次循环迭代。 它会告知编译器忽略循环中的假定矢量依赖性,因此需谨慎使用。
在本程序中,线程并行化和矢量化在同一个循环中进行。 每个线程从循环的下限开始。 为确保 OpenMP(静态调度)取得良好的对齐效果,我们可以限制并行循环的数量,并以串行方式处理其他循环。
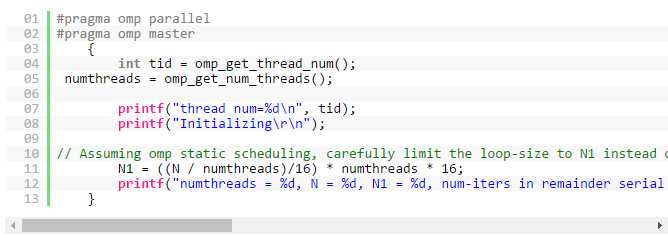
另外,计算根的函数将变成
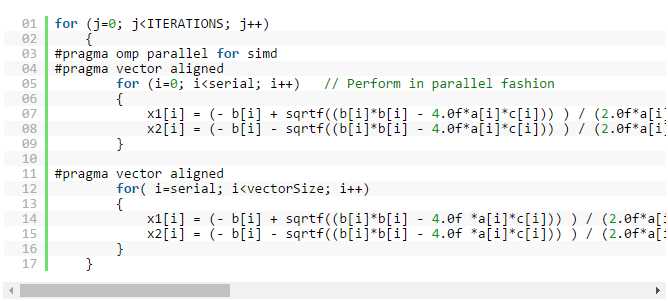
现在你可以编译该程序,并将其连接至 –qopenmp:
$ icc myParallelApp.c –O3 -qopt-report=5 -qopt-report-phase:vec,openmp -o myParallelAppl -qopenmp
查看 myParallelApp.optrpt 报告,确认循环是否已借助 OpenMP 完成了矢量化和并行化。
5.2. 使用环境变量设置线程数量和相似性
OpenMP 实施可同时启动几个线程。 默认情况下,线程数量设为系统中的最多硬件线程。 本案例中将默认运行 272 个 OpenMP 线程。 不过我们还可以使用 OMP_NUM_THREADS 环境变量设定 OpenMP 线程的数量。 例如,以下命令可启动 68 个 OpenMP 线程:
$ export OMP_NUM_THREADS=68
使用 KMP_AFFINITY 环境变量可设置线程相似性(能够将 OpenMP 线程绑定至 CPU)。 为使线程均匀分布于系统,可将变量设置为分散 (scatter):
$ export KMP_AFFINITY=scatter
现在可使用系统中的全部内核来运行程序,并改变每内核运行的线程数。 以下是测试输出,测试对每内核分别运行 1、2、3、4 个线程时的性能进行了对比。
测试系统中每内核运行 1 个线程:
$ export KMP_AFFINITY=scatter
$ export OMP_NUM_THREADS=68
$ ./myParallelApp
No. of Elements : 512M
Repetitions = 10
Start allocating buffers and initializing ....
thread num=0
Initializing
numthreads = 68, N = 536870912, N1 = 536870336, num-iters in remainder serial loop = 576, parallel-pct = 99.999893
Starting Compute on 68 threads
Elapsed time in msec: 1722 (after 10 iterations)
每内核运行 2 个线程:
$ export OMP_NUM_THREADS=136
$ ./myParallelApp
No. of Elements : 512M
Repetitions = 10
Start allocating buffers and initializing ....
thread num=0
Initializing
numthreads = 136, N = 536870912, N1 = 536869248, num-iters in remainder serial loop = 1664, parallel-pct = 99.999690
Starting Compute on 136 threads
Elapsed time in msec: 1781 (after 10 iterations)
每内核运行 3 个线程:
$ export OMP_NUM_THREADS=204
$ ./myParallelApp
No. of Elements : 512M
Repetitions = 10
Start allocating buffers and initializing ....
thread num=0
Initializing
numthreads = 204, N = 536870912, N1 = 536869248, num-iters in remainder serial loop = 1664, parallel-pct = 99.999690
Starting Compute on 204 threads
Elapsed time in msec: 1878 (after 10 iterations)
每内核运行 4 个线程:
$ export OMP_NUM_THREADS=272
$ ./myParallelApp
No. of Elements : 512M
Repetitions = 10
Start allocating buffers and initializing ....
thread num=0
Initializing
numthreads = 272, N = 536870912, N1 = 536867072, num-iters in remainder serial loop = 3840, parallel-pct = 99.999285
Starting Compute on 272 threads
Elapsed time in msec: 1940 (after 10 iterations)
从上述结果可看出,每内核运行 1 个线程并使用全部 68 个内核时性能达到最佳。
6. 面向英特尔至强融核处理器优化内核
6.1. 内存带宽优化
系统中有两种内存:16 GB 封装内存 MCDRAM 和 96 GB 传统平台 6 通道 DDR4 RAM(借助选项最高可扩展至 384 GB)。 MCDRAM 带宽约为 500 GB/秒,而 DDR4 峰值性能带宽约为 90 GB/秒。
有三种适用于 MCDRAM 的配置模式:扁平模式、缓存模式或混合模式。 如果 MCDRAM 配置为可寻址内存(扁平模式),用户可明确地分配 MCDRAM 中的内存。 如果 MCDRAM 配置成缓存模式,整个 MCDRAM 都可用作二级缓存和 DDR4 内存之间的末级缓存。 如果 MCDRAM 配置成混合模式,部分 MCDRAM 可用作高速缓存,其余部分可用作可寻址内存。 下表列出了这些配置模式的优点和缺点:
| 内存模式 | 优点 | 缺点 |
| 扁平模式 |
|
|
| 缓存模式 |
|
|
| 混合模式 |
|
|
关于非一致性内存访问 (NUMA) 架构,根据 MCDRAM 配置方式的不同,英特尔至强融核处理器以一个或两个节点的形式出现。 如果 MCDRAM 配置为缓存模式,英特尔至强融核处理器将以 1 个 NUMA 节点的形式出现。 如果 MCDRAM 配置为扁平或混合模式,英特尔至强融核处理器将以 2 个 NUMA 节点的形式出现。 注意,集群模式可将英特尔至强融核处理器进一步划分成 8 个 NUMA 节点;不过本教程暂不涉及集群模式。
使用 numactl 实用程序可显示系统中的 NUMA 节点。 例如,在本系统执行“numactl –H” — 其中 MCDRAM 配置为扁平模式,将显示 2 个 NUMA 节点。 节点 0 包含 272 个 CPU 和 96 GB DDR4 内存,节点 1 包含 16 GB MCDRAM。
$ numactl -H
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271
node 0 size: 98200 MB
node 0 free: 92888 MB
node 1 cpus:
node 1 size: 16384 MB
node 1 free: 15926 MB
node distances:
node 0 1
0: 10 31
1: 31 10
在部分 NUMA 模式下,可使用"numactl" 工具分配内存。 本示例中,节点 0 包含所有 CPU 和平台内存 DDR4,节点 1 包含封装内存 MCDRAM。 可使用开关 –m 或 –-membind 迫使程序将内存分配至某个 NUMA 节点。
如果迫使应用分配 DDR 内存(节点 0),可运行以下命令:$ numactl -m 0 ./myParallelApp
这相当于:$ ./myParallelApp
现在使用 68 个线程来运行应用:
$ export KMP_AFFINITY=scatter
$ export OMP_NUM_THREADS=68
$ numactl -m 0 ./myParallelApp
No. of Elements : 512M
Repetitions = 10
Start allocating buffers and initializing ....
thread num=0
Initializing
numthreads = 68, N = 536870912, N1 = 536870336, num-iters in remainder serial loop = 576, parallel-pct = 99.999893
Starting Compute on 68 threads
Elapsed time in msec: 1730 (after 10 iterations)
如显示 NUMA 节点的其他视图,可运行命令“lstopo”。 该命令不仅显示 NUMA 节点,还显示与这些节点相关的一级高速缓存和二级高速缓存。
6.2. 分析内存使用率
应用是否受带宽限制? 使用英特尔 VTune Amplifier 分析内存访问。 DDR4 DRAM 峰值性能带宽约为 90 GB/秒,MCDRAM 内存峰值性能约为 500 GB/秒。
在系统上安装英特尔 VTune Amplifier,然后运行以下英特尔 VTune Amplifier 命令,以收集应用分配 DDR 内存时的内存访问信息:
$ export KMP_AFFINITY=scatter; export OMP_NUM_THREADS=68; amplxe-cl -collect memory-access -- numactl -m 0 ./myParallelApp
通过查看“带宽利用率直方图”字段,可以了解应用的带宽利用率。 该直方图显示 DDR 带宽利用率较高。

通过查看内存访问分析我们发现,DDR4 最高带宽为 96 GB/秒,这几乎是 DDR4 的峰值性能带宽。 该结果表明应用受带宽限制。

通过查看应用的内存分配,我们发现分配了包含 512 M 元素(即 512 * 1024 * 1024 个元素)的 5 个大型阵列。 每个元素都是单精度浮点(4 字节)数;因此每个阵列的大小约为 4*512 M 或 2 GB。 总内存分配为 2 GB * 5 = 10 GB。 这种内存大小非常适合 MCDRAM(16 GB 容量),因此分配 MCDRAM 中的内存(扁平模式)将有利于该应用。
分配 MCDRAM 中的内存(节点 1)时,需将参数–m 1 传递至命令 numactl,如下所示:
$ numactl -m 1 ./myParallelApp
No. of Elements : 512M
Repetitions = 10
Start allocating buffers and initializing ....
thread num=0
Initializing
numthreads = 68, N = 536870912, N1 = 536870336, num-iters in remainder serial loop = 576, parallel-pct = 99.999893
Starting Compute on 68 threads
Elapsed time in msec: 498 (after 10 iterations)
显然,应用分配 MCDRAM 中的内存时,性能得到了明显提升。
为进行对比,我们运行英特尔 VTune Amplifier 命令,收集应用分配 MCDRAM 内存时的内存访问信息:
$ export KMP_AFFINITY=scatter; export OMP_NUM_THREADS=68; amplxe-cl -collect memory-access -- numactl -m 1 ./myParallelApp
该直方图显示 DDR 带宽利用率较低,而 MCDRAM 的利用率较高:


通过查看内存访问分析我们发现,DDR4 峰值带宽为 2.3 GB/秒,而 MCDRAM 峰值带宽达到了 437 GB/秒。

6.3. 使用编译器手柄 –xMIC-AVX512 进行编译
英特尔至强融核处理器支持 x87、英特尔? SIMD 流指令扩展(英特尔? SSE)、英特尔? SSE2、英特尔? SSE3、SIMD 流指令扩展 3 补充版、英特尔? SSE4.1、英特尔? SSE4.2、英特尔? 高级矢量扩展指令集(英特尔? AVX)、英特尔? 高级矢量扩展指令集 2(英特尔? AVX2)和英特尔? 高级矢量扩展指令集 512 (英特尔? AVX-512)指令集架构 (ISA), 但不支持英特尔? 交易同步扩展。
英特尔 AVX-512 在英特尔至强融核处理器中实施。 英特尔至强融核处理器支持以下组: 英特尔 AVX-512F、英特尔 AVX-512CD、英特尔 AVX-512ER 和英特尔 AVX-FP。 英特尔 AVX-512F(英特尔 AVX-512 基础指令)包括适用于 512 位适量寄存器的英特尔 AVX 和英特尔 AVX2 SIMD 流指令;英特尔 AVX-512CD(英特尔 AVX-512 冲突检测)有助于高效检测冲突,以支持更多循环完成矢量化;英特尔 AVX-512ER(英特尔 AVX-512 指数和倒数指令)为以 2 为底的指数函数、倒数和平方根倒数提供指令。 英特尔 AVX-512PF(英特尔 AVX-512 预取指令)有助于降低内存操作延迟。
为充分利用英特尔 AVX-512,可借助编译手柄 –xMIC-AVX512 编译程序
$ icc myParallelApp.c -o myParallelApp-AVX512 -qopenmp -O3 -xMIC-AVX512
$ export KMP_AFFINITY=scatter
$ export OMP_NUM_THREADS=68
$ numactl -m 1 ./myParallelApp-AVX512
No. of Elements : 512M
Repetitions = 10
Start allocating buffers and initializing ....
thread num=0
Initializing
numthreads = 68, N = 536870912, N1 = 536870336, num-iters in remainder serial loop = 576, parallel-pct = 99.999893
Starting Compute on 68 threads
Elapsed time in msec: 316 (after 10 iterations)
注意,现在可以运行以下命令,生成名为 myParallelApp.s 的汇编文件:
$ icc -O3 myParallelApp.c -qopenmp -xMIC-AVX512 -S -fsource-asm
通过检查汇编文件,可以确认是否生成了英特尔 AVX512 ISA。
6.4. 使用 –no-prec-div -fp-model fast=2 优化标记。
如果不要求高精度,我们可以使用 -fp-model fast=2进行编译,大胆使用浮点模型,从而进一步优化浮点数(但不太安全)。 编译器实施更快速、精度较低的平方根和除法运算。 例如:
$ icc myParallelApp.c -o myParallelApp-AVX512-FAST -qopenmp -O3 -xMIC-AVX512 -no-prec-div -no-prec-sqrt -fp-model fast=2
$ export OMP_NUM_THREADS=68
$ numactl -m 1 ./myParallelApp-AVX512-FAST
No. of Elements : 512M
Repetitions = 10
Start allocating buffers and initializing ....
thread num=0
Initializing
numthreads = 68, N = 536870912, N1 = 536870336, num-iters in remainder serial loop = 576, parallel-pct = 99.999893
Starting Compute on 68 threads
Elapsed time in msec: 310 (after 10 iterations)
6.5. 将 MCDRAM 配置成缓存
在 Bios 设置中,将 MCDRAM 配置成缓存并重启系统。 numactl 实用程序可确认是否只有一个 NUMA 节点,因为 MCDRAM 配置成缓存后,对该实用程序来说是透明的:
$ numactl -H
available: 1 nodes (0)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271
node 0 size: 98200 MB
node 0 free: 94409 MB
node distances:
node 0
0: 10
重新编译该程序:
$ icc myParalledApp.c -o myParalledApp -qopenmp -O3 -xMIC-AVX512 -no-prec-div -no-prec-sqrt -fp-model fast=2
并运行该程序:
$ export OMP_NUM_THREADS=68
$ ./myParalledApp-AVX512-FAST
No. of Elements : 512M
Repetitions = 10
Start allocating buffers and initializing ....
thread num=0
Initializing
numthreads = 68, N = 536870912, N1 = 536870336, num-iters in remainder serial loop = 576, parallel-pct = 99.999893
Starting Compute on 68 threads
Elapsed time in msec: 325 (after 10 iterations)
观察该应用中将 MCDRAM 用作高速缓存是否没有其他优势。
7. 总结和结论
本教程介绍了以下主题:
- 内存对齐
- 矢量化
- 生成编译器报告以协助代码分析
- 使用命令行实用程序
cpuinfo、lscpu、numactl、lstopo - 使用 OpenMP 添加线程层并行化
- 设置环境变量
- 使用英特尔 VTune Amplifier 分析带宽利用率
- 使用
numactl分配 MCDRAM 内存 - 使用英特尔 AVX512 标记进行编译,以提升性能
下表显示了从基准代码完成每一个优化步骤后所实现的性能提升:基于数据对齐的通用优化、矢量化、添加线程层并行化、以扁平模式分配 MCDRAM 内存、借助英特尔 AVX512 进行编译、借助无精度标记进行编译,以及将 MCDRAM 用作高速缓存。
")
通过使用全部可用内核、英特尔 AVX-512 矢量化和 MCDRAM 带宽,我们能够大幅缩短执行时间。
参考资料:
- 面向英特尔? 至强融核? 处理器以及英特尔? AVX-512 ISA 的编译
- Knights Landing 上的 MCDRAM(高带宽内存)简介
- 英特尔? C++ 编译器矢量化指南
- 在 Stream Triad 上优化 Knights Landing 的内存带宽
- 英特尔? 至强融核? 协处理器上的流处理
- 数据对齐有助于实现矢量化
- 为在英特尔? 至强? 处理器上实现最佳性能的内存管理: 对齐和预取
- 英特尔? MIC 架构高级优化
- 使用 OpenMP 4.0 在程序中启用 SIMD
- 英特尔? 至强? 处理器 — 内存模式和集群模式: 配置和用例
关于作者
Loc Q Nguyen 拥有达拉斯大学 MBA 学位、麦吉尔大学电子工程专业硕士学位以及蒙特利尔理工学院电子工程专业学士学位。 目前在英特尔公司软件及服务事业部担任软件工程师。 研究领域包括计算机网络、并行计算和计算机图形。
性能测试中使用的软件和工作负载可能仅在英特尔? 微处理器上进行了性能优化。 诸如SYSmark和MobileMark等测试均系基于特定计算机系统、硬件、软件、操作系统及功能, 上述任何要素的变动都有可能导致测试结果的变化。 请参考其他信息及性能测试(包括结合其他产品使用时的运行性能)以对目标产品进行全面评估。 如欲了解更多信息,请访问http://www.intel.com/performance.
以上是关于英特尔® 至强融核? 处理器优化教程的主要内容,如果未能解决你的问题,请参考以下文章