借助 SIMD 数据布局模板和数据预处理提高 SIMD 在动画中的使用效率
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了借助 SIMD 数据布局模板和数据预处理提高 SIMD 在动画中的使用效率相关的知识,希望对你有一定的参考价值。
简介
为发挥 SIMD1 的最大作用,除了对其进行矢量化处理2外,我们还需作出其他努力。可以尝试为循环添加 #pragma omp simd3,查看编译器是否成功进行矢量化,如果性能有所提升,则达到满意状态。 然而,可能性能根本不会提升,甚至还会降低。 无论处于何种情况,为了最大限度发挥 SIMD 执行的优势并实现性能提升,通常需要重新设计算法和数据布局,以便生成的 SIMD 代码尽可能高效。 另外还可收到额外的效果,即标量(非矢量化)版代码会表现得更好。
本文将通过一个 3D 动画算法示例,逐步介绍除添加“#pragma”之外我们还可使用哪些方法。 在这一过程中,其他技巧和方法也可为您的下一步矢量化工作提供帮助。 我们还集成了算法与 SIMD 数据布局模板 (SDLT) — 英特尔? C++ 编译器的一项特性,以提高数据布局和 SIMD 的效率。 本文的所有源代码均可下载,并包含此处未提及的其他详细信息。
背景知识和问题陈述
有时,对循环进行矢量化处理并不足以提升算法的性能。 英特尔? C++ 编译器可能会提示“可以矢量化但效率可能非常低”。 但仅仅因为循环可以进行矢量化,并不意味着生成的代码比未进行矢量化的循环更高效。 如果矢量化无法提升性能,您可以选择查明其背后的原因。 通常,为了获取高效的 SIMD 代码,要求重新设计数据布局和算法。 许多情况下,无论是否进行矢量化,有利于 SIMD 的优化方法是实现性能提升的主要原因。 不过,通过提升算法的效率,SIMD 性能将会显著提高。
本文将介绍示例源代码及其四个其他版本的循环,说明我们为提高 SIMD 效率所作出的更改。 图 1 将用作本文参考以及已下载的源代码。 有关版本 0 - 3 的部分是本文的核心部分。 额外的版本 4 部分将介绍能够消除 SIMD 转化开销的高级 SDLT 特性。
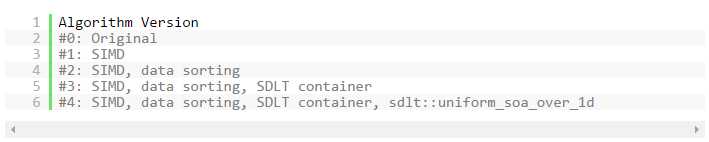
图 1: 版本编号图例以及可用源代码中有关代码集修改的相应描述。 版本编号同样包含修改顺序。
要求数据收集与分散的算法会对标量和 SIMD 的性能造成影响。 而且,如果您拥有收集(分散)链,会进一步降低性能。 如果循环中包含间接访问(或非单位步长内存访问4),如图 2 所示,编译器可能会生成收集指令(显式收集指令或多个模拟数据收集的指令)。 而且由于需要间接访问大型指令,收集指令的数量将随着数据基元数量的增加而呈指数级增长。 例如,如果指令“A”包含 4 次加倍,间接访问这一指令将会生成 4 个收集指令。 有些情况下,算法中会不可避免地出现间接访问。 不过,如有可能,您应该找出解决方法避免间接访问。 避免出现收集(或分散)等低效行为,可显著提升 SIMD 性能。
另外,数据对齐也可提升 SIMD 性能。 如果循环在未对齐 SIMD 数据通道的数据上运行,性能会有所降低。

图 2: 间接内存寻址可能是收集或分散行为,而且支持循环索引用于查找另一索引。 收集是索引负载。 分散是索引保存。
我们通过一个简单的 3D 网格变形算法示例说明几项可用于提升生成代码效率的技巧,从而为标量和 SIMD 提供优势。 在图 3 中,3D 网格的每个顶点都有一个附件,其中包含可影响顶点变形的数据。 每个附件间接引用 4 个接合点。 附件和接合点保存在 1D 阵列中。

图 3: 3D 网格变形示例算法。
版本 0: 算法
在图 4 中,算法循环迭代“附件”阵列。 每个附件包含 4 个在“接合点”阵列中间接访问的接合点索引值。 而且每个接合点包含一个由 12 次加倍组成的转换矩阵 (3x4)。 因此每次循环迭代要求收集 48 次加倍(12 次加倍乘以 4 个接合点)。 收集如此多加倍会降低 SIMD 性能。 因此,如果减少或避免这种收集,SIMD 性能将会显著提升。

图 4: 版本 0: 每次循环迭代包含 48 次收集的示例算法。
版本 1: SIMD
关于版本 1,我们对循环进行矢量化处理。 在示例中,通过添加“#pragma omp simd”即可成功使循环实现矢量化(见图 5),因为它满足矢量化标准(例如,没有函数调用,单进单出,直线式代码5)。 另外,它遵循 SDLT 的矢量化策略,即限制对象以帮助编译器成功完成私有化。6然而,我们应注意,在许多情况下,简单添加编译指示会造成编译错误或错误生成代码。7通常需要进行代码重构,以使循环达到可矢量化状态。

图 5: 版本 1: 修改版本 0的第 8 行(见图 4)以对循环进行矢量化处理。
图 6 显示了英特尔? C++ 编译器 (ICC) XE 关于版本 1 循环的 Opt-报告。 对英特尔? 高级矢量扩展(英特尔? AVX)9构建而言,大家可以看出,Opt-报告显示即使循环实现了矢量化,性能预计只能提升 5%。 但在我们的案例中,版本 1 的实际性能比版本 0 低 15%。 无论 Opt-报告预计多大程度的性能提升,都应该进行测试以了解实际性能。
另外,图 6 显示了由全部 4 个 Joint 构成的转换矩阵中,每次加倍都有 48 项“间接访问”掩码索引负载。 同时相应地生成了 48 个“间接访问”备注,图 7 列举了其中的一个。 我们不应该忽视 Opt-报告备注;而应调查原因并尝试解决这些问题。

图 6: 版本 1: 关于循环的英特尔? C++ 编译器 Opt-报告。

图 7: 版本 1: 英特尔? C++ 编译器 Opt-报告,间接访问备注。
即使循环实现了矢量化,间接访问造成的大量收集行为仍然会阻碍 SIMD 提升性能。
解决方案
矢量化成功后,性能可能会有所提升,也可能不会。 无论何种情况,对循环进行矢量化处理都应只是优化过程的起点,而不是终点。 相反,我们可以使用工具(例如,Opt-报告、汇编代码,英特尔? VTune? Amplifier XE、英特尔? Advisor XE)帮助调查效率低下的原因,并通过实施解决方案来改进 SIMD 代码。
版本 2(第 1 部分): 通过整理对数据进行预处理以确保数据统一
在我们的示例中,Opt-报告报告了 48 次收集和相应的“间接访问”备注。 我们需要特别关注间接访问备注,因为该报告中几乎全是这种备注。 经过进一步调查,我们发现它们分别对应 4 个(矢量化循环内部间接访问的)接合点的 4x3 个矩阵值,总共 48 次收集。 我们知道收集(或分散)会影响性能。 那我们该如何解决这一问题呢。 必须进行收集,还是应想办法避免这些收集行为?
例如,我们问自己“是否有能够从循环体内部访问,并能够提升至循环外部的统一数据?” 最初的答案是“否”,然后我们问“是否能够重新设计算法,以便生成为循环不变式的统一数据?”

图 8: 整理算法数据。 左侧,循环迭代接合点索引完全不同的附件。 右侧,附件经过整理,每个(内层)子循环都有相同的统一接合点数据集。
如图 8 所示,许多独立附件都可共享相同的接合点索引值。 通过整理附件,所有共享相同索引的附件可分在一组,这样将有机会循环附件的子集,其中接合点均匀(循环不变式)分布于子循环的迭代空间。 这样将有助于将接合点数据提升至矢量化内层循环的外部。 这样内层矢量化循环将不会出现任何收集行为。
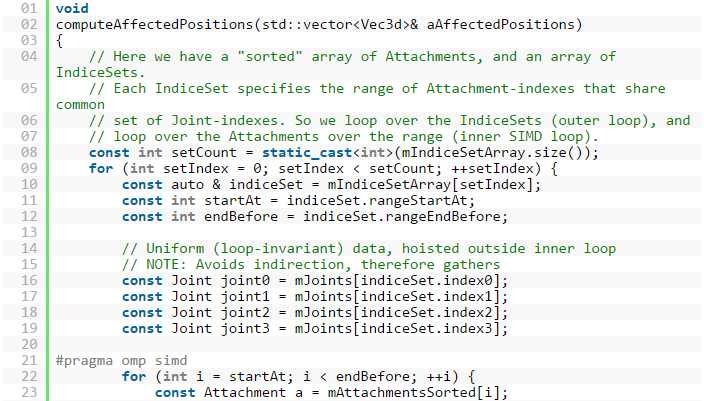
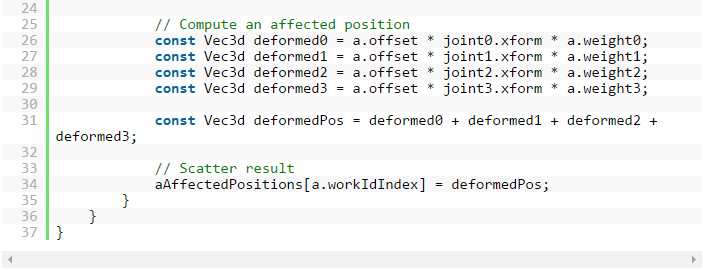
图 9: 版本 2: 重新设计算法以创建统一(循环不变式)数据。
图 9 显示了使用整理数据阵列后生成的代码,它将共享统一数据的元素分在一组,其中原始循环转化成可避免收集行为的外层和内层(矢量化)循环。 IndiceSet 的 mIndiceSetArray 阵列能够跟踪整理后阵列中的起始索引和终止索引。 因此我们有一个外层循环和一个内层循环。 而且,由于数据经过重新排序,所以需要添加 workIdIndex 以跟踪原始位置,以便写出结果。
现在 Opt 报告(见图 10)不再报告接合点造成的 48 次索引掩码负载(或收集行为)。 而且“预计”英特尔? AVX 性能将提升 2.35 倍。 在我们的案例中,实际性能提升了 2.30 倍。

图 10: 版本 2: 关于通过统一接合点数据重新设计后的循环的英特尔? C++ 编译器 Opt-报告。
在图 10 中,我们应注意,Opt-报告仍然报告了 8 次“收集”或“掩码步长负载”。 造成这种结果的原因是访问 mSortedAttatchments 阵列的结构阵列内存布局。 理想情况下,我们希望实现“非掩码对齐单元步长”负载。 稍后我们将验证如何借助 SDLT 实现这一目标。 同样值得注意的是,Opt-报告(见图 10)中出现了 3 次分散。 这是因为我们重新排列了输入数据,因此需要以正确的顺序将结果写出至输出(如图 9 第 29 行所示)。 但分散 3 个值要好于收集 48 个值,因为只需少量开销就可避免大量成本。
版本 2(第 2 部分): 数据填充
这时,Opt 报告预计性能将大幅提升。 然而,我们将最初的大型附件循环重新整理成多个小型的子循环,并且我们注意到,在实际循环执行过程中,处理短行程计数时,性能并未达到最佳状态。 就短行程计数而言,未完全矢量化的剥离循环或剩余循环中会消耗大量执行时间。 图 11 所提供的示例说明未对齐数据会导致在剥离循环、主循环或剩余循环中执行。 如果迭代空间的起始索引或终止索引(或两者)不是 SIMD 矢量通道数量的倍数,这种情况就会出现。 理想状态下,我们希望所有执行时间都出现在主 SIMD 循环中。

图 11: SIMD 循环解析。 当编译器执行矢量化时,会为 3 类循环(主 SIMD 循环、剥离循环和剩余循环)生成代码。 本图中有一个 4 矢量通道示例,其中循环迭代空间范围为 3-18。 主循环将一次性处理 4 个元素(从 SIMD 通道边界 4 开始,到 15 为止),剥离循环将处理元素 3,剩余循环将处理 16-18.
 可用于查看相应的汇编代码")
图 12: 英特尔? VTune? Amplifier XE (2016) 可用于查看相应汇编代码中时间消耗情况。 查看英特尔 VTune Amplifier XE 中的(已执行)汇编,及其滚动条时,蓝色横条表示执行时间。 通过识别汇编中的剥离循环、主循环和剩余循环,可以确定矢量化主循环外部消耗了多长时间(如有)。
因此,除了整理附件之外,填充附件数据以使其成为 SIMD 矢量通道数量的倍数,也可提升 SIMD 性能。 图 13 解释了填充数据阵列如何支持所有执行均发生在主 SIMD 循环中,这是一种理想状态。 结果可能各有差异,但填充数据通常是一项非常实用的技巧。

图 13: 填充数据阵列。 在 4 矢量通道示例中,显示了附件经过整理,可分成两组子循环。 (左侧)子循环 1 中,附件 0-3 在主循环中处理,剩下两个元素(4 和 5)由剩余循环处理。 子循环 2 中,仅有一个为 3 的行程计数,全部 3 个均由剥离循环处理。 (右侧)我们填充了所有子循环,以使其成为 4 条 SIMD 通道的倍数,从而支持所有附件均由矢量化循环来处理。
版本 3: SDLT 容器
由于我们重新设计了算法以避免收集行为并显著提升 SIMD 性能,现在我们可以利用 SDLT 进一步提高 SIMD 代码的效率。 到现在为止,所有负载都为“掩码”,且未对齐。 理想状态下,我们希望负载为非掩码、对齐、单位步长负载。 我们使用 SDLT 基元和容器来实现这一目标。 SDLT 有助于使 SIMD 循环中的局部变量成功完成私有化,即每个 SIMD 通道都有一个私有变量实例。 SDLT 容器和访问器将自动处理数据转换和对齐。
图 14 中,源代码显示了集成 SDLT 所需的修改。 主要的变化是为指令 AttachmentSorted 声明SDLT_PRIMITIVE,然后将用于附件阵列的输入数据容器从 std::vector 容器(结构阵列 (AOS) 数据布局)转化成 SDLT 容器。 编程人员可使用 SDLT 访问器上的运算符 [],就像它们是 C 阵列或 std::vector。 最初我们使用 SDLT 阵列结构 (SOA) 容器 (sdlt::soa1d_container),但阵列结构阵列 (ASA) 容器 (sdlt::asa1d_container) 也可显著提升性能。 转换(使用 typedef)SDLT 容器类型以测试是否获得最佳性能的方法非常简单,因此建议大家采用。 图 14 中,我们引入了 SDLT_SIMD_LOOP 宏指令,即 ICC 16.2 (SDLT v2) 中的“预览”特性,且兼容 ASA 和 SOA 两种容器类型。
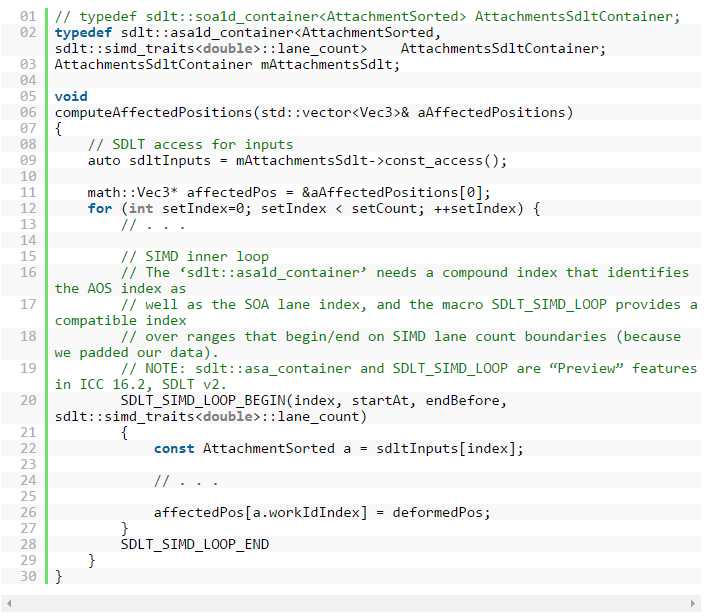
图 14: 版本 3。 集成 SDLT 容器(第 1–3 行,以及第 7 行)和访问器(第 8 和 19 行);同样使用 SDLT_SIMD_LOOP 宏指令的“预览”特性(第 17 和 23 行)。 仅显示版本 2 的不同之处。

图 15: 版本 3: 使用 SDLT 基元和容器时的英特尔? C++ 编译器 Opt-报告。
图 15 中,Opt-报告预计版本 3 将实现 1.88 倍的性能提升。 但请记住,这只是预估值,而不是实际性能提升。 事实上,我们的案例实现了 3.17 倍的实际性能提升。 另外,回忆一下,版本 2 的 Opt 报告(图 10)报告了“掩码步长”负载。 现在(图 15)的负载为“非掩码”、“对齐”、“单位步长”。 这是最理想的性能状态,可通过使用 SDLT 容器改进数据布局并提高内存访问效率来实现。
版本 4:sdlt::uniform_soa_over1d
在版本 4 的算法中,我们还发现了许多其他的性能提升机会。 请注意,从一个子循环到下一个子循环,4 个接合点数据中的 3 个都可提取出来供内层循环中统一访问。 而且大家还应了解,为每次进入 SIMD 循环准备统一数据会产生较大的开销,而且我们在针对统一数据的每次外层循环迭代过程中都要承担这种成本。
就 SIMD 循环而言,根据 SIMD 指令集的不同,10迭代开始前准备统一数据会产生开销。 对每个统一值来说,编译器可以 1) 将标量加载至寄存器,2) 将寄存器中的标量值传播至 SIMD 寄存器的所有通道,然后 3) 将 SIMD 寄存器保存在堆栈上的新位置,以供 SIMD 循环体使用。 就长行程计数而言,这一开销可轻松摊销。 但就短行程计数而言,它可能会影响性能。 在版本 3 中,每次外层循环迭代都会产生有关 4 个接合点的开销,总共 48 次加倍(每个接合点 12 次加倍)。

图 16: 查找行程计数: 英特尔? Advisor XE (2016) 具有一项能够为循环执行提供行程计数的实用功能。 它可帮助大家轻松识别短行程计数和长行程计数。
在这种场景下,SDLT 可支持通过确定何时产生开销,明确管理这种 SIMD 数据转化,而不会自动产生开销成本。 SDLT 的这种高级功能为 sdlt::uniform_soa_over1d。 它有助于消除循环中的 SIMD 转化开销,并帮助用户控制产生开销的时间。 其原理是以 SIMD 就绪型格式保存循环不变式数据,以便 SIMD 循环不经过转化就可直接访问数据。 它支持统一数据实现部分更新和重复利用,从而帮助提升性能。
为了说明 SIMD 数据转化开销何时出现,以及 SDLT 如何帮助消除这一开销,我们在图 17 和 18 中提供了一个伪代码示例。 图 17 显示每次外层循环迭代(第 18 行)和每次加倍(通过统一数据访问)(12 次加倍)都会产生开销。 图 18 显示了 sdlt::uniform_soa_over1d 的用途,它能够使这种开销仅产生一次(第 6 行),从而降低总体成本。 这种高级功能会为特定场景带来巨大优势。 用户应进行试验。 实际结果可能有所不同。

图 17: 进入第 12 行的 SIMD 循环之前,对每个统一值来说,编译器可以 1) 将标量加载至寄存器,2) 将寄存器中的标量值传播至 SIMD 寄存器的所有通道,然后 3) 将 SIMD 寄存器保存在堆栈上的新位置,以供 SIMD 循环体使用。 就长行程计数而言,这一开销可轻松摊销。 但就短行程计数而言,它可能会影响性能。

图 18: 通过使用 sdlt::uniform_soa_over1d,确定何时产生开销,可明确管理这种 SIMD 数据转化,而不会自动产生成本。 SDLT 的这项高级功能有助于消除循环中的 SIMD 转化开销,并帮助您控制产生开销的时间。 其原理是以 SIMD 就绪型格式保存循环不变式数据,以便 SIMD 循环不经过转化就可直接访问数据。
因此第一步是在短行程计数情况下进一步提升性能,我们重新设计算法,以便重复利用从外层循环索引 i至 i+1 的 4 个接合点中的三个,如图 19 所示。 使用 SDLT 功能可帮助消除为子循环准备 SIMD 数据时所累计的开销。
的统一数据可重复用于下一子循环")
图 19: 版本 3: 面向其中 3 个接合点(共 4 个)的统一数据可重复用于下一子循环 可部分更新统一数据,以最大限度地减少负载(或外层循环中的收集)。 而且使用 sdlt::uniform_soa_over1d 以 SIMD 就绪型格式保存统一数据,还可最大限度地降低涉及所有子循环的 SIMD 转化开销。
通过重构循环以便将统一数据重复运用于各个子循环,而且只需进行部分更新,平均来说,我们只需更新 1/4 的统一数据。 因此,设置用于 SIMD 循环的统一数据时所产生的开销将降低 75%。
结论

图 20: 基于英特尔? 至强? CPU 处理器 E5-2699 v3 (代号 Haswell)构建的英特尔? 高级矢量扩展所实现的性能提升i
对代码进行矢量化处理只是实现 SIMD 性能加速的开始,而不是结尾。 矢量化之后应该使用可用资源和工具(例如优化报告、英特尔 VTune Amplifier XE、英特尔 Advisor XE)了解已生成代码的效率。 经过分析后,可以发现对标量和 SIMD 代码有用的优化机会。 然后使用并测试各项技巧,无论是常见技巧还是本文提到的技巧。 你可能需要重新考虑算法和数据布局,以最大限度地提高代码(尤其是已生成的汇编代码)的效率。
通过示例我们可以看出,对算法实施数据预处理以消除所有间接访问(收集)的版本 2 收到了最大成效。 版本 3 使用 SDLT,通过非掩码对齐单位步长负载改进内存访问,并填充数据以对齐 SIMD 通道边界,显著提升了性能。 在短行程计数场景中,我们使用 SDLT 高级功能,最大限度地降低了统一数据开销的总体成本。
参考资料
- 下载包含源代码的示例:
https://software.intel.com/sites/default/files/managed/de/3f/animation-simd-sdlt-whitepaper.tar.gz - SDLT 文档(包含部分代码示例):
https://software.intel.com/zh-cn/code-samples/intel-compiler/intel-compiler-features/intel-sdlt - SIGGRAPH 2015: DreamWorks 动画 (DWA): 如何借助 SIMD 将皮肤变形性能提升 4 倍:
http://www.slideshare.net/IntelSoftware/dreamwork-animation-dwa - “先试后买”英特尔? Parallel Studio XE 评估版:
http://software.intel.com/intel-parallel-studio-xe/try-buy - 面向合格学生、教育工作者、学术研究人员和开源工作者的英特尔? Parallel Studio XE 免费版本:
https://software.intel.com/zh-cn/qualify-for-free-software - 英特尔? VTune? Amplifier 2016:
https://software.intel.com/zh-cn/intel-vtune-amplifier-xe - 英特尔? Advisor:
https://software.intel.com/zh-cn/intel-advisor-xe
脚注
1 单指令多数据 (SIMD) 指利用数据层并行化,单条指令同时处理多个数据。 它与传统“标量操作”(使用单条指令处理单个数据)正好相反。
2 矢量化指计算机程序从标量实施转化为矢量(或 SIMD)实施。
3 pragma simd: https://software.intel.com/zh-cn/node/583427。 pragma omp simd: https://software.intel.com/zh-cn/node/583456
4 非单位步长内存访问指在循环连续增量的过程中,从内存的非相邻位置访问数据。 这样会严重影响性能。 相反,以单位步长(或顺序)形式访问内存会显著提高效率。
5 以供参考: https://software.intel.com/sites/default/files/8c/a9/CompilerAutovectorizationGuide.pdf
6 SDLT 基元可限制对象,有助于编译器成功完成 SIMD 循环中针对局部变量的私有化,即每个 SIMD 通道都有一个私有变量实例。 为满足这一标准,对象必须是 Plain Old Data (POD),拥有行内对象成员,没有嵌套阵列,而且没有虚拟函数。
7 在矢量化过程中,开发人员应该试验各种不同的编译指示(比如 simd、omp simd、ivdep 和矢量 {always [assert]}),并使用 Opt-报告。
8 我们为基于 Linux* 的英特尔? C++ 编译器 16.0 (2016) 添加了命令行选项“-qopt-report=5 –qopt-report-phase=vec”,以生成 Opt-报告 (*.optrpt)。
9 使用英特尔? C++ 编译器 16.0 生成英特尔? 高级矢量扩展(英特尔? AVX) 指令时,可将选项 “-xAVX” 添加至编译命令行。
10AVX512 指令集包含传播负载指令,可降低迭代开始之前准备统一数据时所产生的 SIMD 开销。
i 在性能检测过程中涉及的软件及其性能只有在英特尔微处理器的架构下方能得到优化。
诸如 SYSmark* 和 MobileMark* 等测试均系基于特定计算机系统、硬件、软件、操作系统及功能。 上述任何要素的变动都有可能导致测试结果的变化。 请参考其他信息及性能测试(包括结合其他产品使用时的运行性能)以对目标产品进行全面评估。 更多信息请访问 http://www.intel.com/content/www/cn/zh/benchmarks/intel-product-performance.html。
配置: 英特尔? 至强? 处理器 E5-2699 v3(45M 高速缓存,2.30 GHz). CPU: 两个 18 核 C1,2.3 GHz。 非内核: 2.3 GHz. 英特尔? 快速通道互联技术: 9.6 GT/秒。 RAM: 128 GB,DDR4-2133 MHz (16 x 8 GB)。 磁盘: 7200 RPM SATA 磁盘。 800 GB 固态盘。 关闭超线程技术,关闭睿频加速。 Red Hat Enterprise Linux* Server 7.0 版。 3.10.0-123.el7.x86_64。
以上是关于借助 SIMD 数据布局模板和数据预处理提高 SIMD 在动画中的使用效率的主要内容,如果未能解决你的问题,请参考以下文章