游戏设计模式——面向数据编程(新)
Posted killeraery
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了游戏设计模式——面向数据编程(新)相关的知识,希望对你有一定的参考价值。
目录
随着软件需求的日益复杂发展,远古时期面的向过程编程思想才渐渐萌生了面向对象编程思想。
当人们发现面向对象在应对高层软件的种种好处时,越来越沉醉于面向对象,热衷于研究如何更加优雅地抽象出对象。
然而现代开发中渐渐发现面向对象编程层层抽象造成臃肿,导致运行效率降低,而这是性能要求高的游戏编程领域不想看到的。
于是现代游戏编程中,面向数据编程的思想越来越被接受(例如Unity2018更新的ECS框架就是一种面向数据思想的框架)。
面向数据编程是什么?
先来一个简单的比较:
面向过程思想:考虑解决问题所需的各个步骤(函数)。
面向对象思想:考虑解决问题所需的各个模型(类)。
面向数据思想:着重考虑数据的存取及布局(数据)。
那么所谓的考虑数据存储/布局是什么意思呢?
这里引入2个有关CPU处理数据的概念:
单指令流多数据流(SIMD)
CPU缓存(CPU Cache)
单指令流多数据流(SIMD)
什么是SIMD

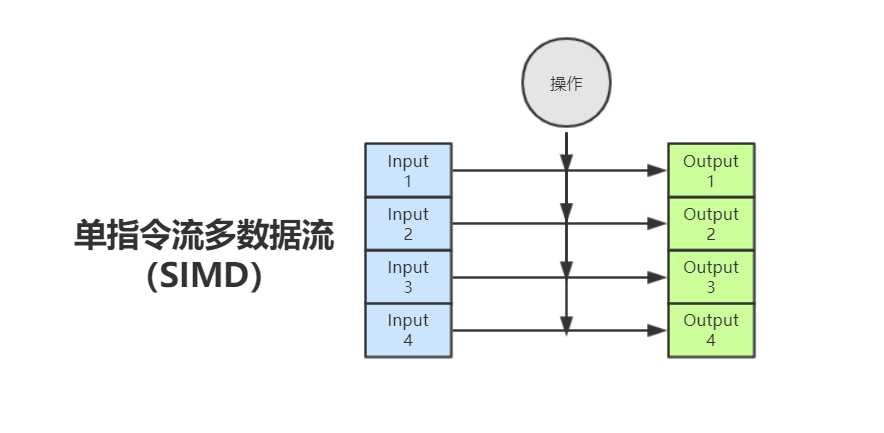
SIMD全称Single Instruction Multiple Data,单指令流多数据流,是一种采用一个控制器来控制多个处理器,同时对若干个数据分别执行相同的操作从而实现空间上的并行性的技术。
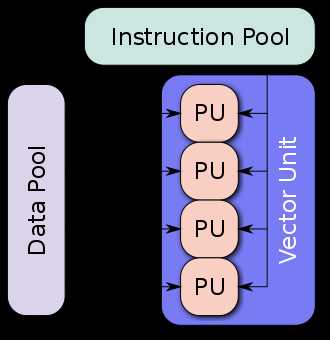
简单来说,SIMD技术可以让CPU在一个指令周期执行多个数据的操作(不过操作需要一样),而不是一个指令周期执行一个数据的操作。
为什么需要SIMD
在上面的介绍里,我们可以直观的知道最大的好处在于:可以允许CPU利用并行性快速处理多个数据。
但是局限性还是有的,SIMD技术一般对矢量算术型操作(例如矢量相加,矢量相乘)支持的很好,而不支持其他类型操作(例如分支判断和跳转)。
所以SIMD技术常用于CPU数据计算密集型应用,例如:
- 人工智能
- 物理计算
- 粒子系统
- 光线追踪
- 图像处理
支持SIMD技术的指令集
X86架构的CPU所支持SSE/SSE2/SSE3指令集就是典型的重点针对/支持SIMD功能的指令集。
目前的PC的CPU架构绝大多数都是Intel的X86架构,而ARM架构的CPU可以在很多消费性电子产品上看到,从可携式装置(PDA、移动电话、多媒体播放器、掌上型电子游戏,和计算机)到电脑外设(硬盘、桌上型路由器)甚至在导弹的弹载计算机等军用设施中都有它的存在。
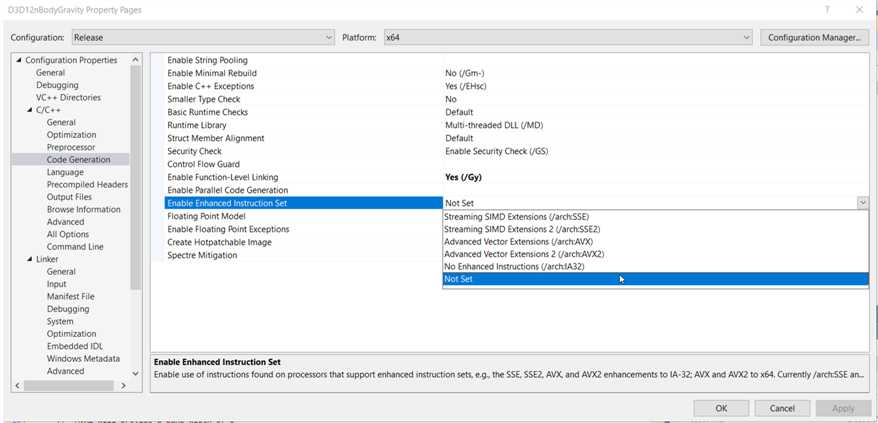
(vs2019里项目设置可以找到指令集设置选项)
我们可以在IDE/编译器里设置好支持SIMD技术的指令集选项。
使用SIMD编程
使用汇编内联

缺陷:
- 汇编代码需根据不同平台定制(无跨平台特性)
- 汇编代码复杂,开发效率低
使用指令集库
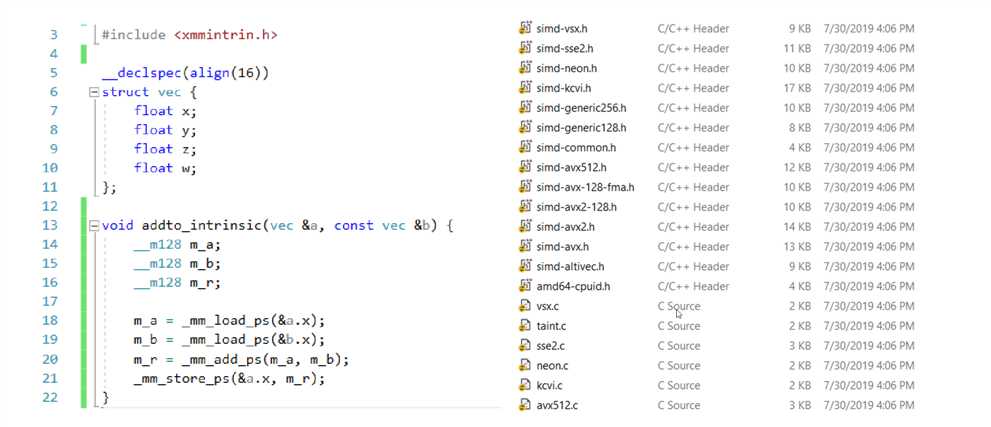
缺陷:
- 代码需根据不同平台指令集,包含不同指令集库头文件(无跨平台特性)
使用ISPC语言
ISPC是英特尔推出的面向CPU的着色器语言,它适用多种指令集的矢量指令(如SSE2、SSE4、AVX、AVX2等)。
ISPC是基于C语言的,所以它大部分语法和C语言是一致的,可以减少学习成本。
ISPC源代码,经过编译后输出.obj文件和.h文件。这样我们在编写C/C++程序时可以包含该头文件以使用ISPC代码。
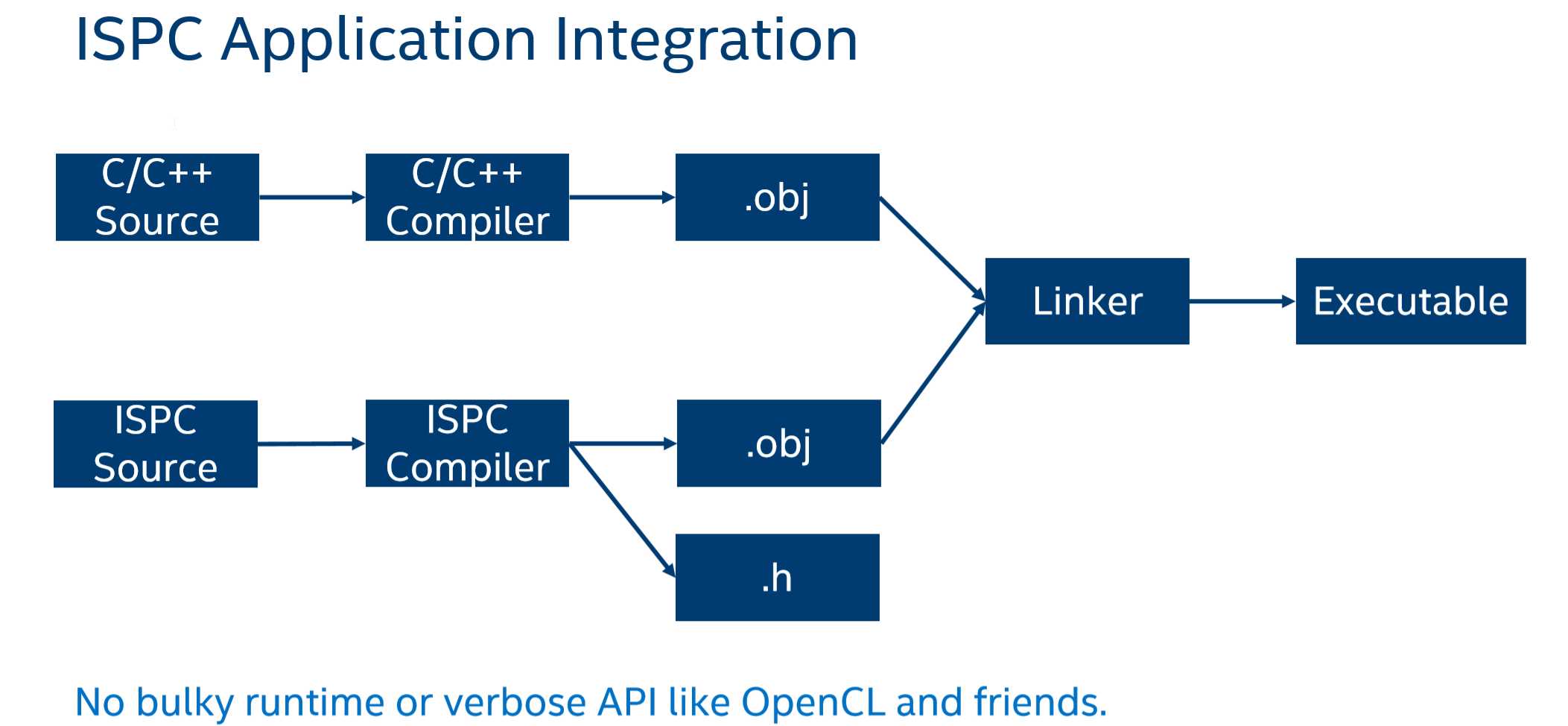
下面简单提供个代码示例比较:
// C/C++ Code
id rgb2grey(int N,
float R[],
float G[],
float B[],
float grey[]) {
for (int i = 0; i < N; i++) {
grey[i] = 0.3f * R[i] + 0.59f * G[i] + 0.11f * B[i];
}
}// ISPC Code
export void rgb2grey(uniform int N,
uniform float R[],
uniform float G[],
uniform float B[],
uniform float grey[]) {
foreach(i = 0 ... N) {
grey[i] = 0.3f * R[i] + 0.59f * G[i] + 0.11f * B[i];
}
}ISPC语言的语法非常易学,因为它的关键字真的很少:
- 类似于C/C++的关键字:if, else, switch, for, while, do…while, goto
- 当然也有为了支持并行循环的关键字:foreach, foreach_active, foreach_tiled, foreach_unique
- 还有其它一些不常用关键字就不列举了
更具体的ISPC语法就不多讲解,可以自己自行去查看官方文档(文章末尾参考部分会给出链接)。
在线编译器godbolt,可以用于测试ISPC代码及调试汇编代码:Compiler Explorer
并行循环
// C/C++ Code
void func(int N,
float A[],
float B[],
float C[]) {
for (int i = 0; i < N; i++) {
C[i] = A[i] * B[i];
}
}上面是一个正常的C/C++循环代码,这样就是一般的分量操作,如下图左侧:
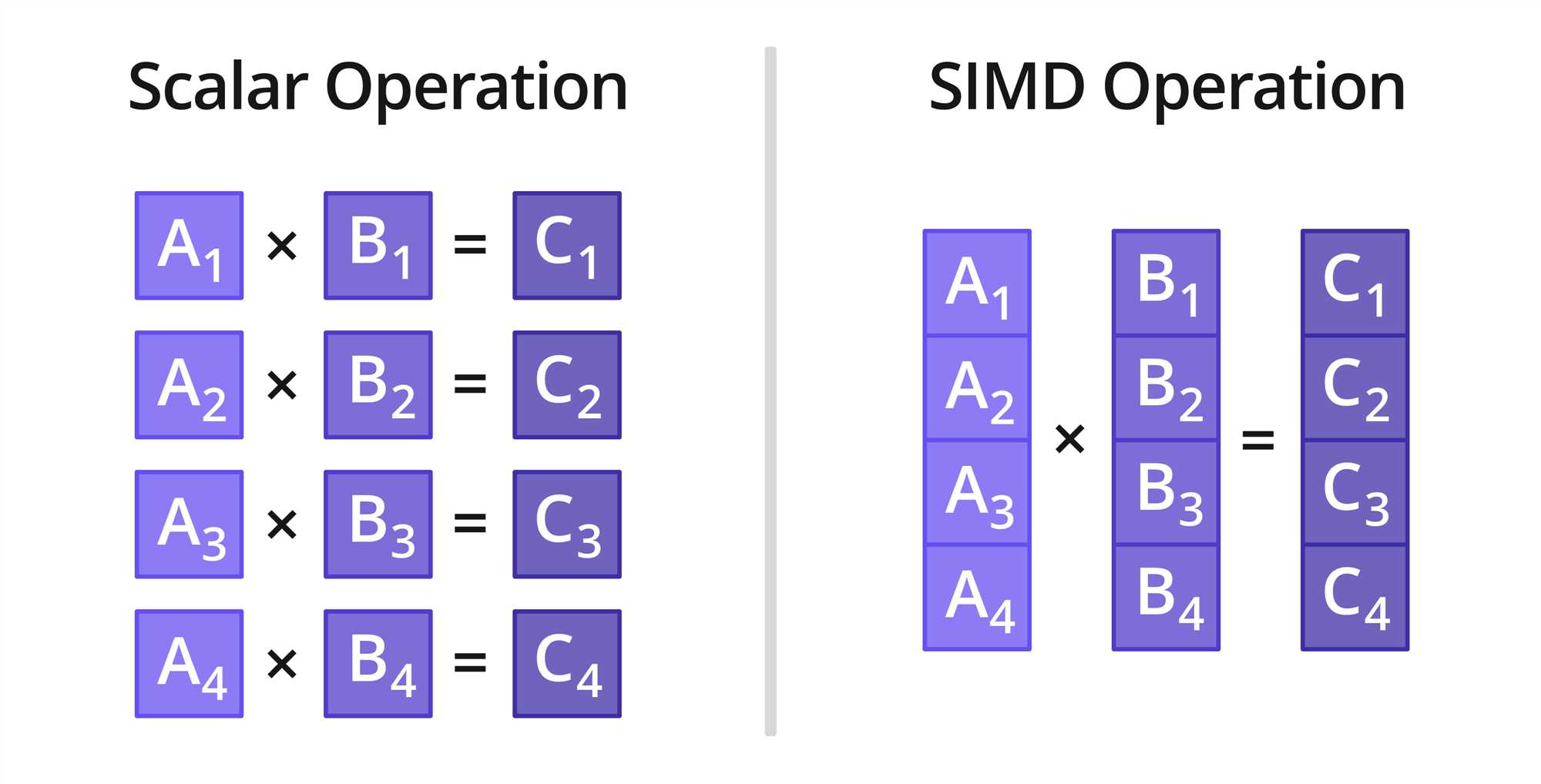
在ISPC语法里,只需简单的写上foreach(i = 0 ... N) ,IPSC编译器编译时会为其编译成图中右侧的行为,即一次循环并行处理M个元素,实际循环N/M次。
// ISPC Code
export void rgb2grey(int N,
uniform float A[],
uniform float B[],
uniform float C[]) {
foreach(i = 0 ... N) {
C[i] = A[i] * B[i];
}
}更方便的是,ISPC会自动处理并行循环的边界情况(例如每次并行处理4个元素时,N/4次循环后余出1~3个元素)。
避免Gather行为
这是一个正常的颜色结构,文中定义了若干个颜色对象。
struct Color{
float r,g,b;
};
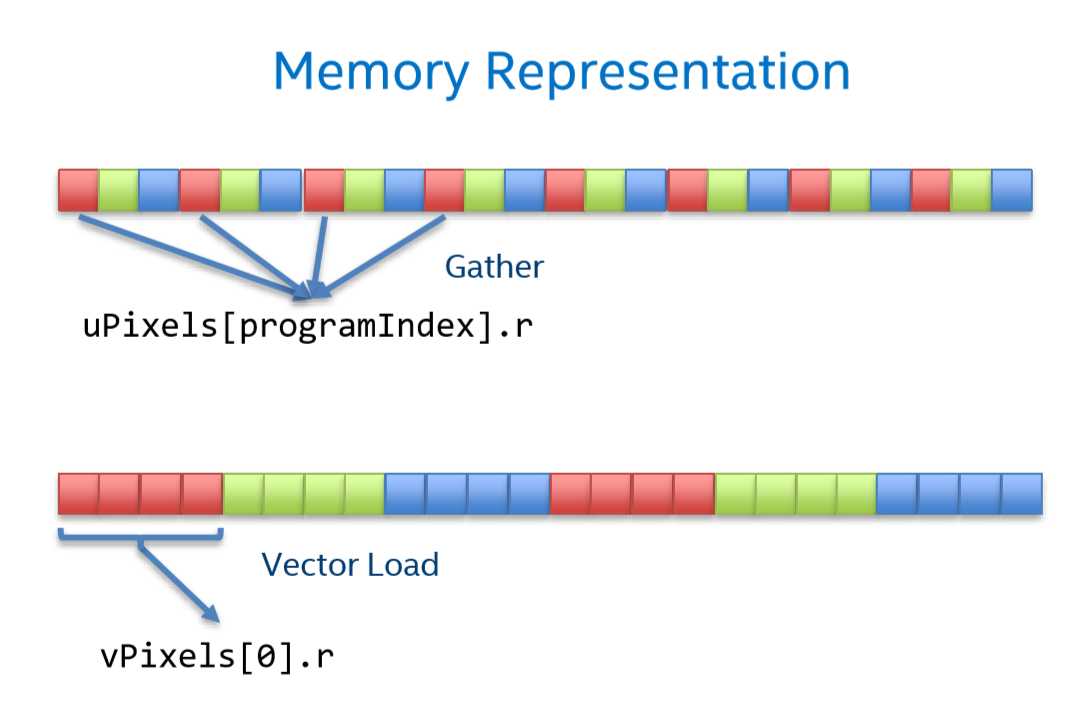
Color colors[1024];SIMD技术读取变量一般都是连续若干个(在图中为4个)变量一次性读取,这种行为叫做矢量读取。
而由于上文的颜色结构定义,其内存分布则如图中的上部分。
要对4个红色分量进行操作时,则需要进行多次读取,这被称为Gather行为。
struct VaryingColor{
float r[vectorLen];
float g[vectorLen];
float b[vectorLen];
};
Color colors[1024/vectorLen];倘若我们使用如下结构定义,则内存分布会如图中下部分。这样就能一次读入4个红色分量,高效地利用SIMD技术。这种结构被称为SIMD友好型结构。
在ISPC语言里,使用varying类型可以方便的定义SIMD友好型结构。
CPU缓存(CPU cache)
在组装电脑购买CPU的时候,不知道大家是否留意过CPU的一个参数:N级缓存(N一般有1/2/3)
什么是CPU缓存
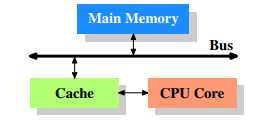
简单地剖析结构,大概会是这个关系:
CPU寄存器 <————> CPU缓存 <————> 内存
可以看到CPU缓存是介于内存和CPU寄存器之间的一个存储区域。
CPU缓存地存储空间比内存小,比寄存器大。
为什么需要CPU缓存
CPU的运行频率太快了,而CPU访问内存的速度很慢,这样在处理器时钟周期内,CPU常常需要等待寄存器读取内存,浪费时间。
而CPU访问CPU缓存则速度快很多。为了缓解CPU和内存之间速度的不匹配问题,CPU缓存则预先存储好潜在可能会访问的内存数据。
CPU缓存预先存的是什么
时间局部性:如果某个数据被访问,那么在不久的将来它很可能再次被访问。
空间局部性:如果某个数据被访问,那么与它相邻的数据很快也能被访问。
CPU多级缓存根据这两个特点,一般存储的是被访问过的数据和被访问数据的相邻数据。
CPU缓存命中/未命中
CPU把待处理的数据或已处理的数据存入缓存指定的地址中,如果即将要处理的数据已经存在此地址了,就叫作CPU缓存命中,这会比直接访问内存要快的多。
如果CPU缓存未命中,就转到内存地址访问,也就是直接访问内存。
提高CPU缓存命中率
要尽可能提高CPU缓存命中率,关键就是要尽量让使用的数据连续在一起。
由于面向数据编程技巧很多,本文篇幅有限,只介绍部分。
使用连续数组存储要批处理的对象
传统的组件模式,往往让游戏对象持有一个或多个组件的引用数据(指针数据)。
(一个典型的游戏对象类,包含了2种组件的指针)
class GameObject {
//....GameObject的属性
Component1* m_component1;
Component2* m_component2;
};下面一幅图显示了这种传统模式的结构: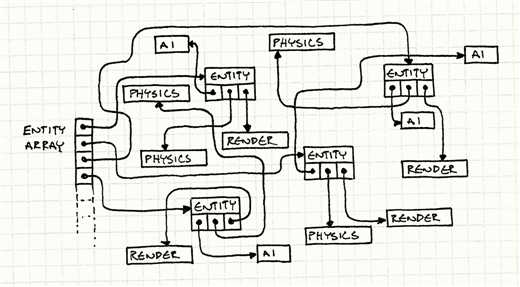
游戏对象/组件往往是批处理操作较多(每帧更新/渲染/或其他操作)的对象。
这个传统结构相应的每帧更新代码:
GameObject g[MAX_GAMEOBJECT_NUM];
for(int i = 0; i < GameObjectsNum; ++i) {
g[i].update();
if(g[i].componet1 != nullptr)g[i].componet1->update();
if(g[i].componet2 != nullptr)g[i].componet2->update();
}而根据图中可以看到,这种指来指去的结构对CPU缓存极其不友好:为了访问组件总是跳转到不相邻的内存。
倘若游戏对象和组件的更新顺序不影响游戏逻辑,则一个可行的办法是将他们都以连续数组形式存在。
注意是对象数组,而不是指针数组。如果是指针数组的话,这对CPU缓存命中没有意义(因为要通过指针跳转到不相邻的内存)。
GameObject g[MAX_GAMEOBJECT_NUM];
Component1 a[MAX_COMPONENT_NUM];
Component2 b[MAX_COMPONENT_NUM];
//连续数组存储能让下面的批处理中CPU缓存命中率较高
for (int i = 0; i < GameObjectsNum; ++i) {
g[i].update();
}
for (int i = 0; i < Componet1Num; ++i) {
a[i].update();
}
for (int i = 0; i < Componet2Num; ++i) {
b[i].update();
}
避免无效数据夹杂在连续内存区域
这是一个简单的粒子系统:
const int MAX_PARTICLE_NUM = 3000;
//粒子类
class Particle {
private:
bool active;
Vec3 position;
Vec3 velocity;
//....其它粒子所需方法
};
Particle particles[MAX_PARTICLE_NUM];
int particleNum;
它使用了典型的lazy策略,当要删除一个粒子时,只需改变active标记,无需移动内存。
然后利用标记判断,每帧更新的时候可以略过删除掉的粒子。
当需要创建新粒子时,只需要找到第一个被删除掉的粒子,更改其属性即可。
for (int i = 0; i < particleNum; ++i) {
if (particles[i].isActive()) {
particles[i].update();
}
}表面上看这很科学,实际上这样做CPU缓存命中率不高:每次批处理CPU缓存都加载过很多不会用到的粒子数据(标记被删除的粒子)。
一个可行的方法是:当要删除粒子时,将队列尾的粒子内存复制到该粒子的位置,并记录减少后的粒子数量。
移动内存(复制内存)操作是程序员最不想看到的,但是实际执行批处理带来的速度提升相比删除的开销多的非常多,除非你移动的内存对象大小实在大到令人发指
particles[i] = particles[particleNum];
particleNum--;这样我们就可以保证在这个粒子批量更新操作中,CPU缓存总是能以高命中率击中。
for (int i = 0; i < particleNum; ++i) {
particles[i].update();
}冷数据/热数据分割
有人可能认为这样能最大程度利用CPU缓存:把一个对象所有要用的数据(包括组件数据)都塞进一个类里,而没有任何用指针或引用的形式间接存储数据。
实际上这个想法是错误的,我们不能忽视一个问题:CPU缓存的存储空间是有限的
于是我们希望CPU缓存存储的是经常使用的数据,而不是那些少用的数据。这就引入了冷数据/热数据分割的概念了。
热数据:经常要操作使用的数据,我们一般可以直接作为可直接访问的成员变量。
冷数据:比较少用的数据,我们一般以引用/指针来间接访问(即存储的是指针或者引用)。
一个栗子:对于人类来说,生命值位置速度都是经常需要操作的变量,是热数据。
而掉落物对象只有人类死亡的时候才需要用到,所以是冷数据;
class Human {
private:
float health;
float power;
Vec3 position;
Vec3 velocity;
LootDrop* drop;
//....
};
class LootDrop{
Item[2] itemsToDrop;
float chance;
//....
};频繁调用的函数尽可能不要做成虚函数
C++的虚函数机制,简单来说是两次地址跳转的函数调用,这对CPU缓存十分不友好,往往命中失败。
实际上虚函数可以优雅解决很多面向对象的问题,然而在游戏程序如果有很多虚函数都要频繁调用(例如每帧调用),很容易引发性能问题。
解决方法是,把这些频繁调用的虚函数尽可能去除virtual特性(即做成普通成员函数),并避免调用基类对象的成员函数,代价是这样一改得改很多与之牵连代码。
所以最好一开始设计程序时,需要先想好哪些最好不要写成virtual函数。
这实际上就是在优雅与性能之间寻求一个平衡。
重新认识C++ STL容器
STL容器,特别是set,map,有着很多O(logN)的操作速度,但并不意味着是最佳选择,因为这种复杂度表示往往隐藏了常数很大的事实。
例如说,集合的主流实现是基于红黑树,基于节点存储的,而每次插入/删除节点都意味着调用一次系统分配内存/释放内存函数。这相比vector等矢量容器所有操作仅一次系统分配内存(理想情况来说),实际上就慢了不少。
此外,矢量容器对CPU缓存更加友好,遍历该种容器容易命中缓存,而节点式容器则相对容易命中失败。
综合上述,如果要选择一个最适合的容器,那么不要过度信赖时间复杂度,除非你十分彻底的了解STL容器,或对各容器进行多次效率测试。
更多小细节(不常用)
面向数据编程还有更多小细节,但是这些都不常用,就只作为一种思考面向数据编程的另类角度。
对二维数组int a[100][100]的遍历:
for(int x=0;x<100;++x)
for(int y=0;y<100;++y)
a[x][y]; //do somethingfor(int y=0;y<100;++y)
for(int x=0;x<100;++x)
a[x][y]; //do something内循环应该是对x递增还是对y递增比较快?答案是:对y递增比较快。
因为对 y 的递增,结果是一个int大小的跳转,也就是说容易访问到相邻的内存,即容易击中CPU缓存。
而对 x 的递增,结果是100个int大小的跳转,不容易击中CPU。
而内循环如果是y的话,那么就能内外循环总共递增100*100次y。
但内循环如果是x的话,那么就内外循环总共只能递增100次y,相比上者,CPU击中比较少。
总结
对面向对象和面向数据的看法:
先说结论:应该兼有。
因为游戏程序是一个既需要高性能又复杂的工程。
使用面向对象的游戏程序新手,常常就有一个问题:过度设计/过度抽象,什么都想用设计模式封装一下抽象一下。
这就很容易导致一些过度设计/过度抽象导致游戏性能太差。
博主现在的项目风格都比较偏向面向数据思想,尽量减少虚函数的使用,多利用数据组合成对象,而不是重写各种基类虚函数。
对于一些数据结构的考量,也尽量偏多使用连续存储的结构(例如数组)。
如何兼有两种思想,这种玄学的问题可能得靠自己去感悟,多尝试和测试性能差别。
参考
《Game Engine Architecture》 2014-1 作者: Jason Gregory
使用英特尔? ISPC 简化SIMD开发 | 英特尔? 软件
WebAssembly and SIMD - Wasmer - Medium
游戏设计模式——面向数据编程(旧) - KillerAery - 博客园
游戏设计模式系列-其他文章:
https://www.cnblogs.com/KillerAery/category/1307176.html
本文使用markdown”重置“以前写的面向数据编程文章,顺便添加和修改了一些内容。吐槽一下,博客园的博文发出去指定tinymce后就不能再修改成md类型了。
以上是关于游戏设计模式——面向数据编程(新)的主要内容,如果未能解决你的问题,请参考以下文章